【NLP】_02_NLP经典任务
【一】NER(命名实体识别) ORG(组织),LOC(地点),PER(人物)
常用方法(原文链接:https://blog.csdn.net/weixin_37665090/article/details/89454829)
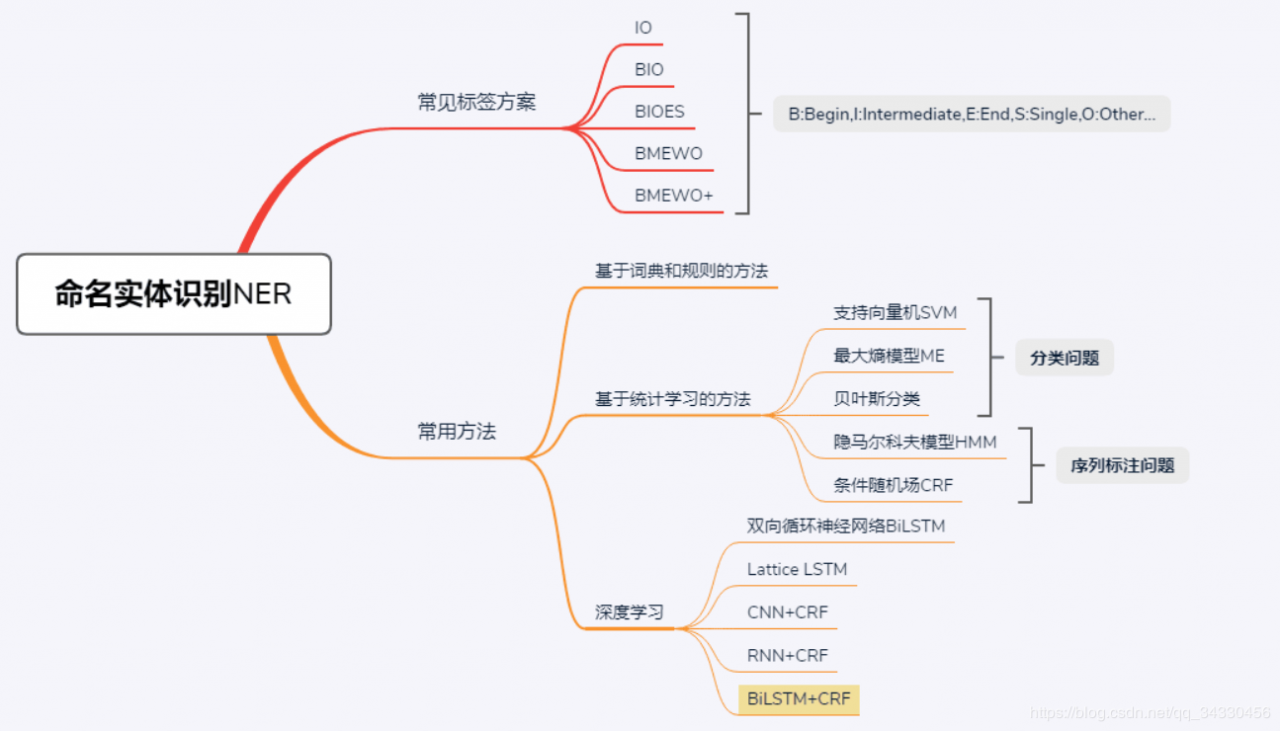
LSTM 的优点是能够通过双向的设置学习到观测序列(输入的单词)之间的依赖,在训练过程中,LSTM 能够根据目标(比如识别实体)自动提取观测序列的特征,但是缺点是无法学习到状态序列(输出的标注)之间的关系,要知道,在命名实体识别任务中,标注之间是有一定的关系的,比如 B类标注(表示某实体的开头)后面不会再接一个 B类标注,所以 LSTM 在解决 NER 这类序列标注任务时,虽然可以省去很繁杂的特征工程,但是也存在无法学习到标注上下文的缺点。
当用 Bi-LSTM 来做命名实体识别时,Bi-LSTM 的输出为实体标签的分数,且选择最高分数对应的标签。然而某些时候,Bi-LSTM 却不能得到真正正确的实体标签,这时候就需要加入 CRF 层。
CRF 由Lafferty 等人于2001 年提出,结合了 最大熵模型 和 隐马尔科夫模型 的特点,能对隐含状态建模,学习状态序列的特点,但它的缺点是需要手动提取序列特征。
所以一般的做法是,在 LSTM 后面再加一层CRF,以获得两者的优点。
【2.1】 Bootstrap:由 规则 生成 记录,再生成 规则,以此类推直到收敛
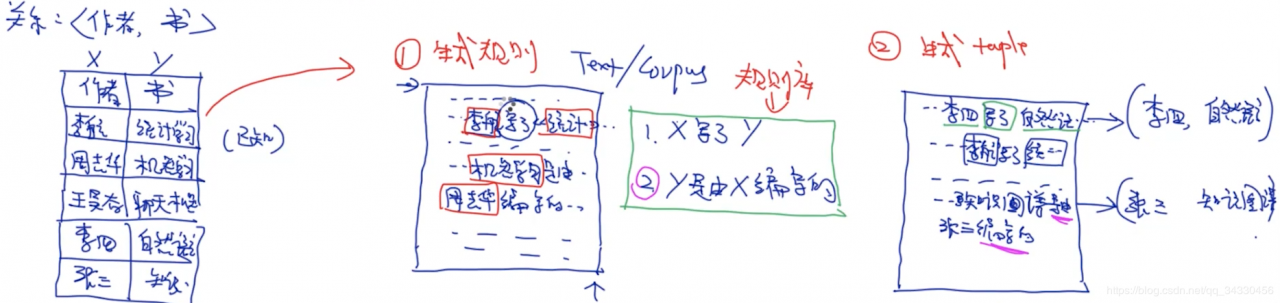
【2.2】 Snowball:在 Bootstrap 的基础上,每个循环都增加了 评估过滤规则,和 评估过滤记录 的操作


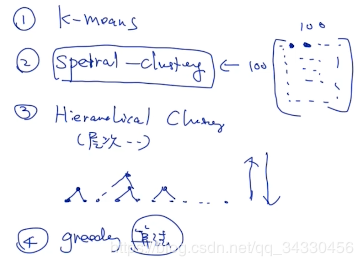
五元组 构建向量后,通过 聚类 将规则减少
【2.2】 强化学习:论文(Robust Distant Supervision Relation Extraction via Deep Reinforcement Learning)
【3.1】Word Mover’s Distance(词移距离)
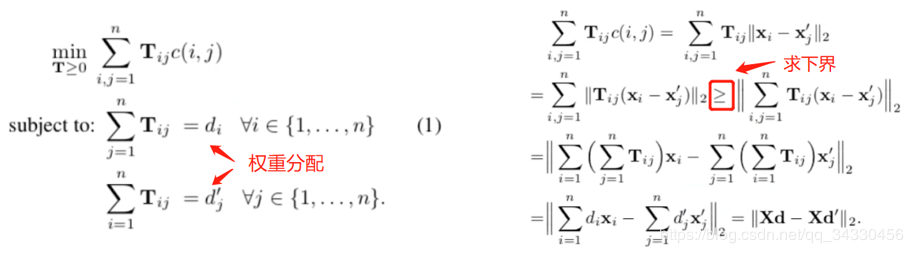 图示(词数越多,Tij 分配的权重越小)
图示(词数越多,Tij 分配的权重越小)
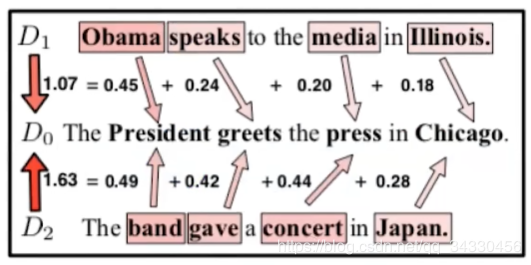
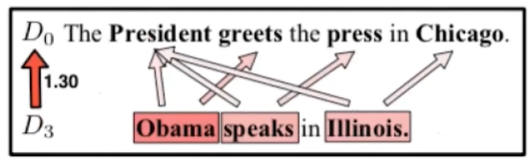

【3.1】Supervised Word Mover’s Distance(监督词移距离)
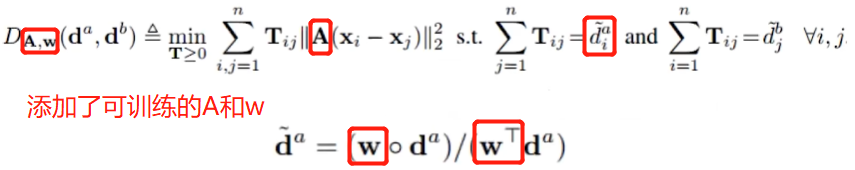
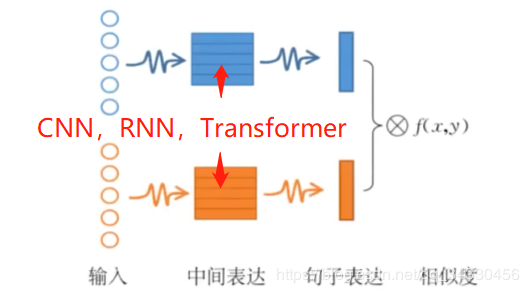
【3.2】深度文本匹配
作者:欲戴皇冠