java为什么匿名内部类的参数引用时final?final局部变量的生命周期
在知乎上看到了一篇帖子
在这个问题下面大家已经吵得不可开交了,看了很多篇文章,被误导进了很多的坑,发现只有下面两篇文章是写的最好的,解释的很清楚,我把两篇文章简单的总结了一下:
https://blog.csdn.net/tianjindong0804/article/details/81710268 https://blog.csdn.net/ch717828/article/details/46922777/ 1.问题的引出
public class Hello {
public static void main(String[] args) {
String str="haha";
new Thread() {
@Override
public void run() {
System.out.println(str);
}
}.start();
}
}
JDK1.8之后做了优化,即不需要将局部变量显示的声明为final也不会发生编译错误,实际上java底层还是加上了final,那么问题来了,为什么匿名内部类访问局部变量要使用final修饰?
这个问题的答案就只有一个: 为了保持数据的一致性
对匿名内部类字节码文件进行反编译
public class Hello$1 extends Thread {
private String val$str;
Hello$1(String paramString) {
this.val$str = paramString;
}
public void run() {
System.out.println(this.val$str);
}
}
也就是说匿名内部类之所以可以访问局部变量,是因为在底层将这个局部变量的值传入到了匿名内部类中,并且以匿名内部类的成员变量的形式存在,这个值的传递过程是通过匿名内部类的构造器完成的。
这里所说的数据一致性,对引用变量来说是引用地址的一致性,对基本类型来说就是值的一致性。
为什么需要用final保护数据的一致性呢?
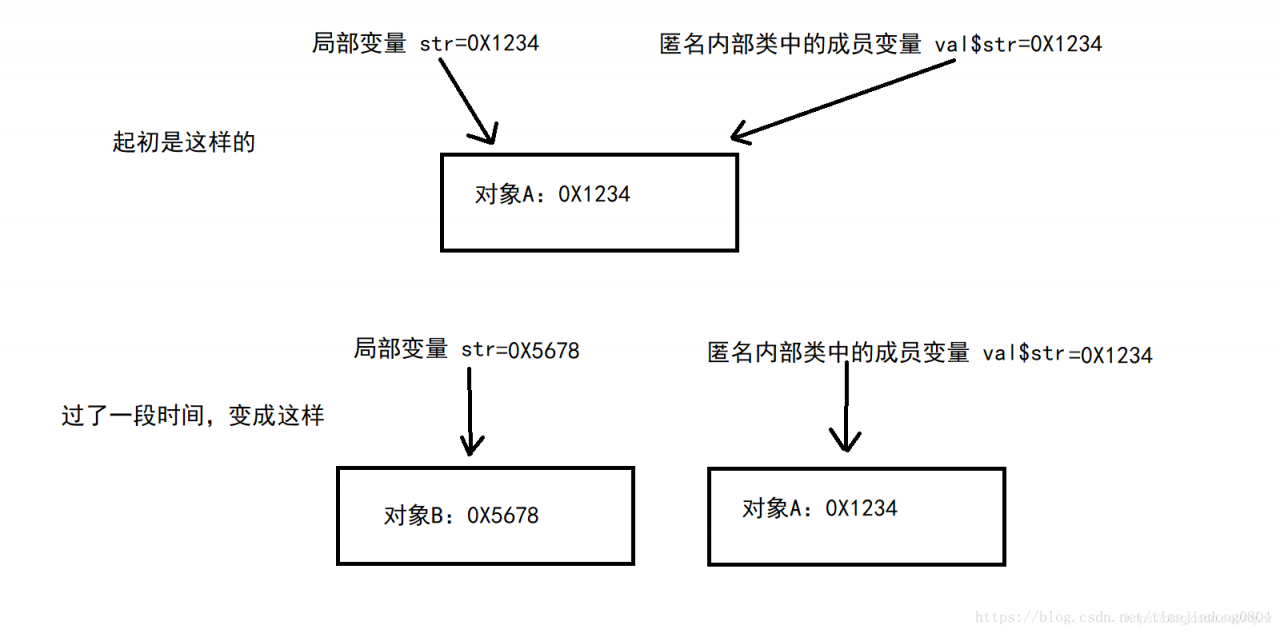
因为将数据拷贝完成后,如果不用final修饰,则原先的局部变量可以发生变化。这里到了问题的核心了,如果局部变量发生变化后,匿名内部类是不知道的(因为他只是拷贝了局不变量的值,并不是直接使用的局部变量)。这里举个栗子:原先局部变量指向的是对象A,在创建匿名内部类后,匿名内部类中的成员变量也指向A对象。但过了一段时间局部变量的值指向另外一个B对象,但此时匿名内部类中还是指向原先的A对象。那么程序再接着运行下去,可能就会导致程序运行的结果与预期不同。
可能还有的回答是:
使用final可以保证局部变量的生命周期,因为在方法中,该方法的局部内部类或匿名内部类创建了,对象存在于堆空间,而局部变量则是存在于栈中,随着方法结束变量也就消失,而对象却不一定消失,所以对象引用的就是不存在的变量了,使用final可以在编译期将final送进常量池中
真有这么简单?
被final修饰的变量确实被当成常量放进了常量池,什么是生命周期?首先变量是在栈空间,对象在堆空间这是没有问题的,栈空间里变量的生命周期就对应着入栈出栈,出栈这个变量就没了,和是不是final有关系?,而对象在堆上的生命周期有专门的GC回收算法
作者:Alphr