面试刷题29:mysql事务隔离实现原理?
mysql的事务是innodb存储引擎独有的,myisam存储引擎不支持事务。
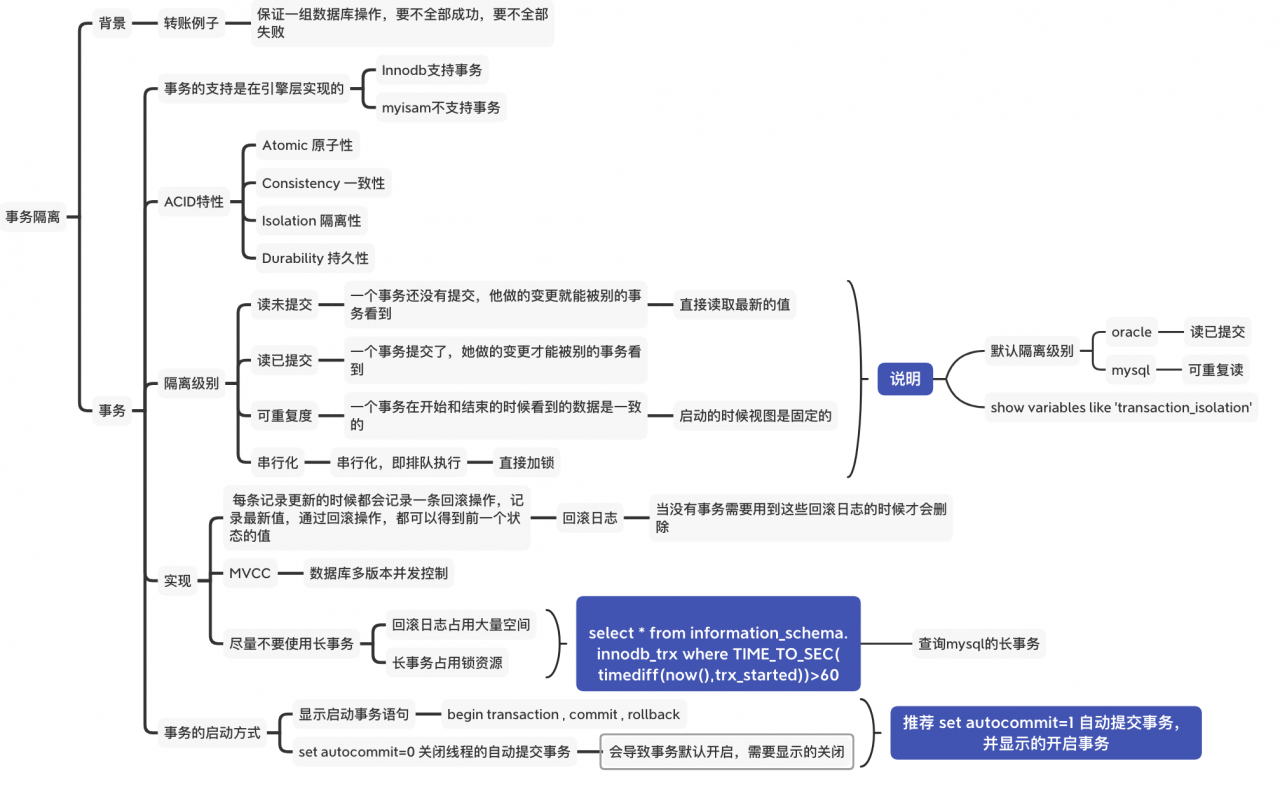
事务最经典的例子就是转账了,事务要保证的是一组数据库的操作要么全部成功,要么全部失败。是为了保证高并发场景下数据的正确性而定义。
事务并非mysql独有。在mysql中,数据库的事务隔离采用的是MVCC结合锁来实现的。
我是李福春,今天的问题是,mysql是如何实现事务隔离的?在实际开发中应该如何正确的使用事务?
ACID特性事务首先具备ACID特性,即
Atomic原子性,
Consistency一致性
Isolation隔离性
durability持久性;
事务隔离级别事务的隔离级别有4个层级,隔离级别依次升高,并发性能依次降低;
读未提交:一个事务可以看到别的事务没有提交的数据,最低隔离水平,容易出现脏读问题;
读已提交:一个事务看到的都是别的事务已经提交过的数据,会出现不可重复度和幻读问题;
可重复度:一个事务的开始和结束阶段读取到的数据一致,mysql默认隔离级别,会出现幻读问题;
串行化:所有的语句都加锁,select读锁,更新操作写锁,where语句还会使用区间锁,最高的隔离级别;
mysql的默认隔离级别是可重复度,而oracle的默认隔离级别是读已提交。
查询mysql当前隔离级别的语句是: show variables like '%transaction%'
mysql实现事务隔离的原理是: 每条更新记录都会记录一条回滚操作,记录最新值,通过回滚操作,都可以得到前一个状态的值; 基于MVCC和锁,数据库的多版本并发控制实现; 如下图:
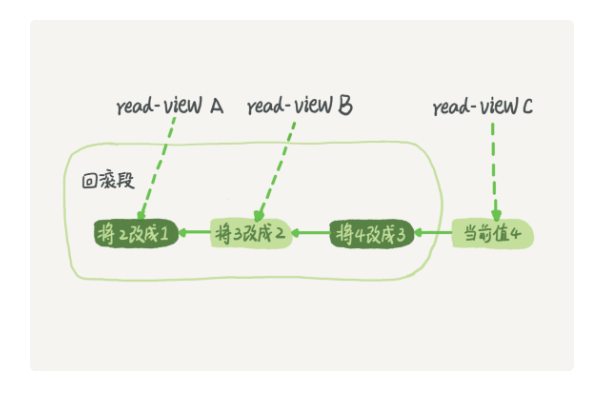
事务之间互不影响,但是回滚操作是共享的,某个事务回滚,根据版本号,拿到回滚操作,可以回滚到事务改变前的值;
长事务的避免和定位实际的编程中,尽量不用长事务,因为: 1,长事务会产生很多的回滚操作日志,占用大量的空间; 2,长事务占用锁资源;
查看当前mysql服务器的长事务的sql语句:
select * from infomation_schema.innodb_trx where time_to_second(timediff(now(),trx_started))>60;
1, set autocommit=1 ,然后显示的使用事务语句或者不使用事务;
2,使用事务的语句 begin transaction , commit ,rollback ;
利用类似 select for update 对数据加锁,避免其他事物意外修改数据;
并发编程的基本概念,在操作共享数据的时候,悲观锁认为数据冲突的可能性比较大。
排它锁(读写锁,双阶段锁)是悲观锁;
乐观锁在并发操作共享数据的时候,乐观锁认为数据出现冲突的可能性比较小。 MVCC本质上可以看成是乐观锁机制。
类似于java的 AtomicFieldLongUpdater , 利用CAS机制,并不会对数据加锁,而是对比数据的时间戳或者版本号,需要皆准版本判断;
售票系统适合使用乐观锁;
小结本节回答了mysql的事务隔离级别,隔离级别越高,并发性能越低;
以及mysql事务隔离的实现原理:基于MVCC和锁实现;
结合编程实践,介绍了悲观锁,乐观锁,并对比了java的并发编程中的工具;
最后给出了一个编程中推荐使用事务的方式。以及一个排查mysql的长事务的sql语句。
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!

作者:李福春