浅谈MySQL表空间回收的正确姿势
前置说明
问题重现
删除数据原理
数据的复用
哪些操作会造成数据空洞
如何收缩表空间
小结
不知道大家有没有遇到这样的一种情况,线上业务在MySQL表上做增删改查操作,随着时间的推移,表里面的数据越来越多,表数据文件越来越大,数据库占用的空间自然也逐渐增长
为了缩小磁盘上表数据文件占用的空间,我们在最大的一张业务表中用delete命令删除了一半儿的旧数据,删除之后,磁盘上表数据文件并没有缩小,即使删除整张表的数据,文件依然没有变小,这是为什么呢?
本文将详细的分析上述问题,并给出正确回收表空间的方法
前置说明目前大部分MySQL数据库都是用的 InnoDB 引擎,所以如无特殊说明,文中的实例都是基于InnoDB引擎的
在MySQL配置中有个配置项叫 innodb_file_per_table 将它设置为1之后,
每个表的数据会单独存储在一个以 .ibd 为后缀的文件中
如果 innodb_file_per_table 没有开启的话,
表的数据是存储在系统的共享表空间,这样即使删除了表,共享表空间也不会释放这部分空间
所以,通常情况下,都是将 innodb_file_per_table 选项设置为 1, 同时为了能直观的看到表数据文件的大小变化,文中的实例也都是基于开启了 此选项来说明的
新建一张表ta,表的结构如下
mysql> show create table ta\G
*************************** 1. row ***************************
Table: ta
Create Table: CREATE TABLE `ta` (
`id` int(11) NOT NULL,
`ia` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
使用下面的存储过程,向 ta 中批量插入数据
delimiter //
create procedure multinsert(in beg int,in cnt int)
begin
declare icnt int default 0;
declare tmp int default 0;
while icnt < cnt do
set icnt = icnt + 1;
set tmp = beg + icnt;
insert into ta(id,ia) values(tmp,tmp);
end while;
end//
delimiter ;
在MySQL控制台执行 call multinsert(0,100000) 命令,往 ta表插入10万条数据
mysql> call multinsert(0,100000);
mysql> select count(*) from ta;
+----------+
| count(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.02 sec)
查看磁盘上ta表的数据文件 ta.ibd 的大小
[root@ecs-centos-7 test]# cd /var/lib/mysql/test/
[root@ecs-centos-7 test]# ls -l ta.ibd
-rw-r----- 1 mysql mysql 11534336 1月 3 23:14 ta.ibd
从上面的结果可以知道,ta表插入10万条数据之后,ta.ibd 大小为 11534336 字节( 大约 11M )
现在我们使用 delete 命令删除一半儿表数据( 5万行记录 )
mysql> delete from ta where id between 1 and 50000;
Query OK, 10000 rows affected (0.03 sec)
mysql> select count(*) from ta;
+----------+
| count(*) |
+----------+
| 50000 |
+----------+
1 row in set (0.02 sec)
删除操作完成之后,再次查看磁盘上 ta.ibd 的大小
[root@ecs-centos-7 test]# cd /var/lib/mysql/test/
[root@ecs-centos-7 test]# ls -l ta.ibd
-rw-r----- 1 mysql mysql 11534336 1月 3 23:14 ta.ibd
从上面的结果可以知道,ta表删除了一半儿,也就是5万行数据之后,ta.ibd的大小是 11534336 字节( 约11M )
也就是说 ta表删除数据前后,磁盘上表数据文件并没有缩小
要弄明白数据文件为什么没有缩小,就需要深入了解删除数据的原理
删除数据原理我们都知道,InnoDB里的数据都是用B+树组织的,关于B+树的知识请参考 理解B+树
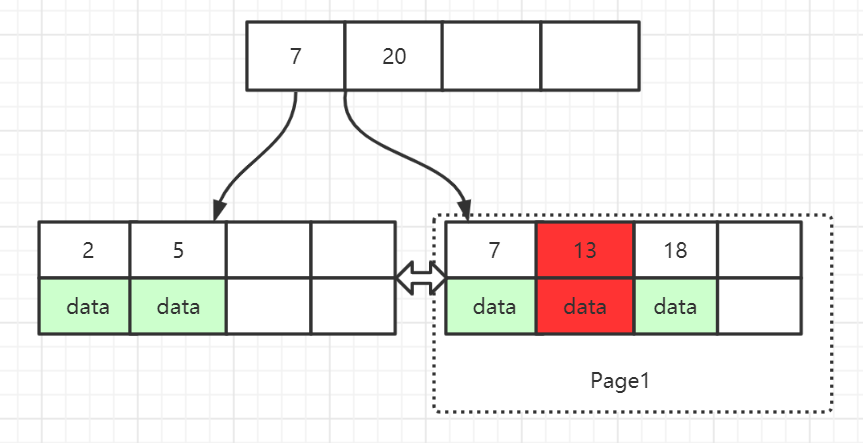
图(1)
上面是InnoDB的索引示意图,其中用虚线框起来的节点是属于Page1数据页,叶子节点存储的是索引对应的数据,它们按照索引从小到大的顺序组成了一个有序数组
假如我们要删除Page1页中索引key值为 13 的数据,也即上图中红色部分
InnoDB引擎会把索引key值为13的节点标记为已删除,它并不会回收节点真实的物理空间,只是将它标记为已删除的节点,后续是可以复用的,所以,删除表记录,磁盘上数据文件不会缩小
你可能会说,上面只是删除了Page1页中一个节点的数据,那如果把Page1页中节点数据全部删除了,应该会回收Page1页的空间吧?
答案是,不会回收
当Page1页数据全部删除了,整个数据页都会被标记为已删除,并且整个数据页都可以复用,所以,这种情况下,磁盘上的数据文件仍然不会缩小
数据的复用数据的复用涉及到数据节点的插入、删除、转移以及数据页的合并等操作,具体的操作流程相关的细节请参考 理解B+树,这里就不再重复说明了
数据节点的复用
在上面 图(1) 中,当删除了索引key值为 13 的节点后,此节点就被标记为可复用的
如果之后又插入了一条索引key值在 7 到 18 之间的记录时,就会复用原来索引key值为13的数据节点
但是如果之后插入的记录的索引key值不在 7 到 18 之间时,可能就无法复用原来索引key值为13的数据节点
也就是说,数据节点的复用,需要索引key值满足一定的范围条件
数据页的复用
在 图(1) 当删除了Page1数据页全部数据节点后,Page1整页都是可复用的,当插入的记录需要用到新页的时候,Page1就可以被复用
当相邻的数据页利用率比较低的时候,有可能会把它们合并到其中一个数据页中,这时,另外一个数据页就空出来了,这个空出来的数据页就变成可复用的了
哪些操作会造成数据空洞我们用 delete 命令删除一条记录后,InnoDB只是把对应的数据节点标记为已删除且可复用的,这些可空着的等待使用的数据节点可以看作是一个一个的数据空洞
删除数据
删除数据的时候,会造成数据空洞,前面已经解释过,这里不再赘述了
插入数据
如果数据是按照索引大小顺序插入,这个时候数据页是紧凑的,不会出现数据空洞
如果是从索引中间插入的话,有可能会造成页分裂,分裂之后的页有可能出现数据空洞,下图就是插入导致页分裂的一个例子
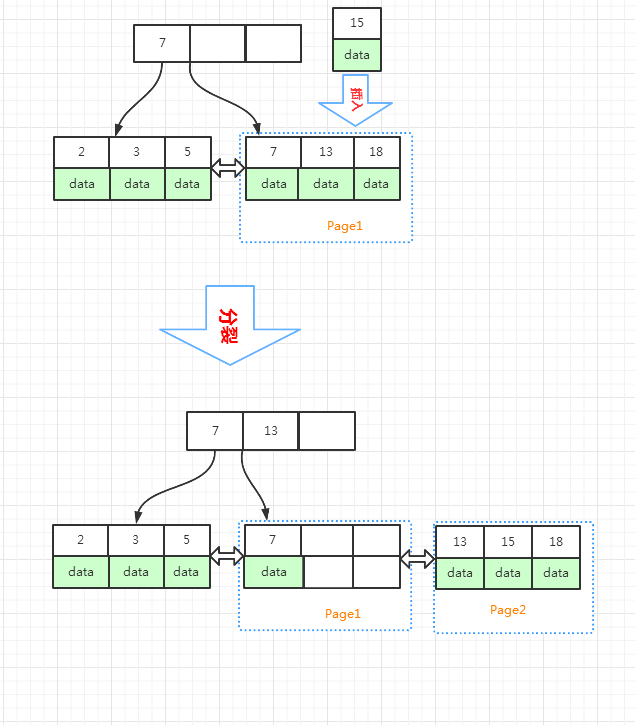
如图所示,分裂前叶子页面已经满了,这时数据排列得很紧凑
现在插入了一个索引key值为15的数据,插入之后,Page1 页分裂成了上图中 Page1,Page2两个页面
分裂之后,Page1 页面出现了两个空洞,这两个数据节点是可复用的,而 Page2页面刚好满了
更新数据
更新数据可以看成先删除再插入,也是有可能造成数据空洞
比如: id 是表 ta的主键, update ta set id = 10 where id = 1 语句把 id = 1 修改为 id = 10,相当于先删除 id = 1 的记录,再插入 id = 10 的记录,这种情况是会产生数据空洞的
但是如果是类似 update ta set ia = ia + 1 where id = 1 这种没有更改主键值的语句是不会造成空洞的
所以,更新数据可能会造成数据空洞
总结下来就是,表的增删改操作,可能会造成数据空洞的,而线上的服务会对表进行大量的增删改操作,数据空洞存在的可能性比较大
如何收缩表空间既然一张表,经过大量无规则的增删改操作之后,会产生大量的数据空洞
那如果我们新建一张和原来有数据空洞的表结构相同的新表,然后把旧表中的数据按照索引升序依次插入到新表中,待旧表数据全部插入到新表之后,删除旧表,再把新表重命名为旧表的名字
由于新表中叶子节点数据是按顺序添加的,所以页面是很紧凑的, 页面利用率很高,需要的页面比旧表少了很多,这样旧表中索引上的空洞在新表就不存在了,新表数据文件占用的磁盘空间自然就会缩小,这样就实现了表空间的收缩的目的
下面介绍的几种收缩表空间的方法,虽然方法不同,但是基本的原理都是通过重建表的形式来达到目的的
truntace table 表名
此操作等于 drop + create,先删除表,然后再创建一个同名的新表,当然,再执行 truncate table 命令之前需要先保存一份旧表的数据, 命令执行完成之后,再把这份数据导入新表
alter table 表名 engine=InnoDB
这个操作是遍历旧表主键索引的数据页,把数据页中的记录生成B+树结构,存储到磁盘上的临时文件中,数据页遍历完了之后,用临时文件替换掉旧表的数据文件
从MySQL5.6版本之后,这个操作是 Online DDL 的,需要说明的是,这种方法需要扫描表数据文件,对于大表来说是非常耗时的,如果是针对线上服务的话,需要避开业务高峰期,小心操作。
注意:
在重建表的时候,InnoDB 不会把整张表占满,每个页留了大概10%左右的数据节点 给后续的更新用, 也就是说,其实重建表之后并不是最紧凑的
假如有这么一个过程: 将表 t 重建一次,
插入一部分数据,但是插入的这些数据,用掉了一部分的预留空间,
这种情况下,再重建一次表 t,就可能会出现重建表后比重建之前占用的空间还要大
本文从一个实际的问题出发,重现问题、分析问题到解决问题,每一步都进行了详细的分析,限于篇幅,有些细节没有深入,需要读者自行了解
到此这篇关于浅谈MySQL表空间回收的正确姿势的文章就介绍到这了,更多相关MySQL表空间回收内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!