手把手基于Mycat实现MySQL数据拆分
点赞多大胆,就有多大产!有支持才有动力!微信搜索公众号【达摩克利斯之笔】获取更多资源,文末有二维码!
Github地址:https://github.com/stt0626/JavaGreat持续收录更新资料
数据库拆分的理论知识有一篇不错的文章,没有必要再复制一遍,不过还是建议大家先看看这篇文章,再动手实现,我们这篇文章主要是基于Mycat去实现一下数据库拆分
https://www.cnblogs.com/butterfly100/p/9034281.html
select user()
select user()
在两个mysql实例中分别创建orders数据库
CREATE DATABASE orders;
登陆Mycat创建四张表
-- 用户表,假如有20W用户
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(20),
PRIMARY KEY (id)
);
-- 订单表,假如有2000W个订单
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY (id)
);
-- 订单详情表,数据量和订单表一样
CREATE TABLE order_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(20),
order_id INT,
PRIMARY KEY (id)
);
-- 字典表,数据量假如有20条,对应订单的类型字典,类型说明数字对应字符串,订单表中只需要存储数字即可
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(20),
PRIMARY KEY (id)
);
查看表
如下图,在Mycat上创建完之后Mycat窗口可以查询出四张表,stt202上有一张customer表,stt203上有三张表,和我们理想效果一样
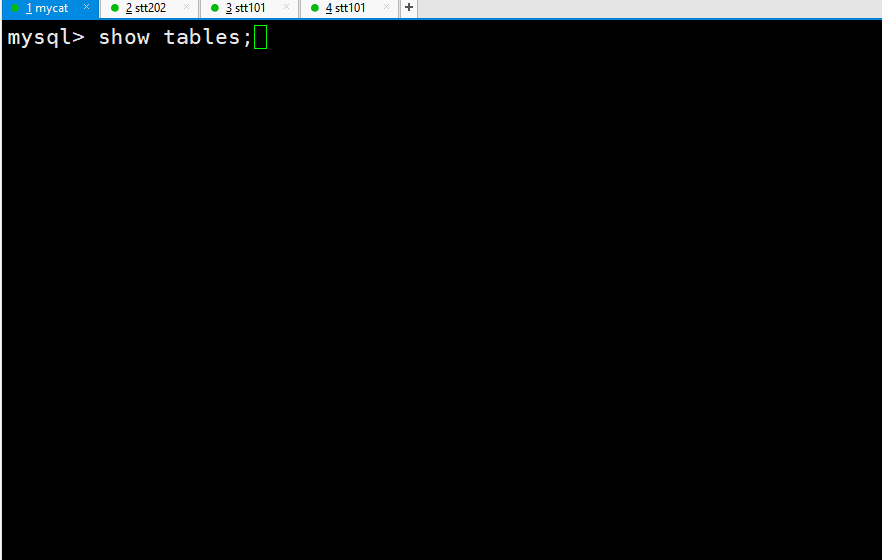
我们发现order和order_detail两张表中数据量非常多,如果存储在同一个节点上的同一个库中性能会受到影响,我们考虑将order表和order_detail表进行拆分,分布式存储全量数据,平均存储在两台节点上。
切片规则 我们切分表中数据需要按照一定的规则切分,比如按照时间,id,用户id等 如果按照时间切分,老的数据存储在一起,新的数据存储在一起,用户一般查询的是新的数据,所以会导致新数据所在节点的负载要高于旧数据节点 如果按照id分区与日期效果类似,一样会导致节点负载不均匀 在本例中我们可以按照customer_id分配,具体的项目需求大家在具体考虑,尽可能让数据平均分配,节点负载均衡
配置mycat的schema.xml配置文件
select user()
select user()
配置rule.xml配置文件
customer_id
mod-long
2
在dn2上创建orders表,重启mycat,登陆mycat新增数据到orders表中
-- 我们以前添加,sql语法表名后的字段名可以省略,但是mycat分库分表添加数据不可省略,因为需要指明哪一列数据是customer_id
INSERT INTO orders(id,order_type,customer_id,amount)VALUES(1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount)VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount)VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount)VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount)VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount)VALUES(6,102,100,100020);
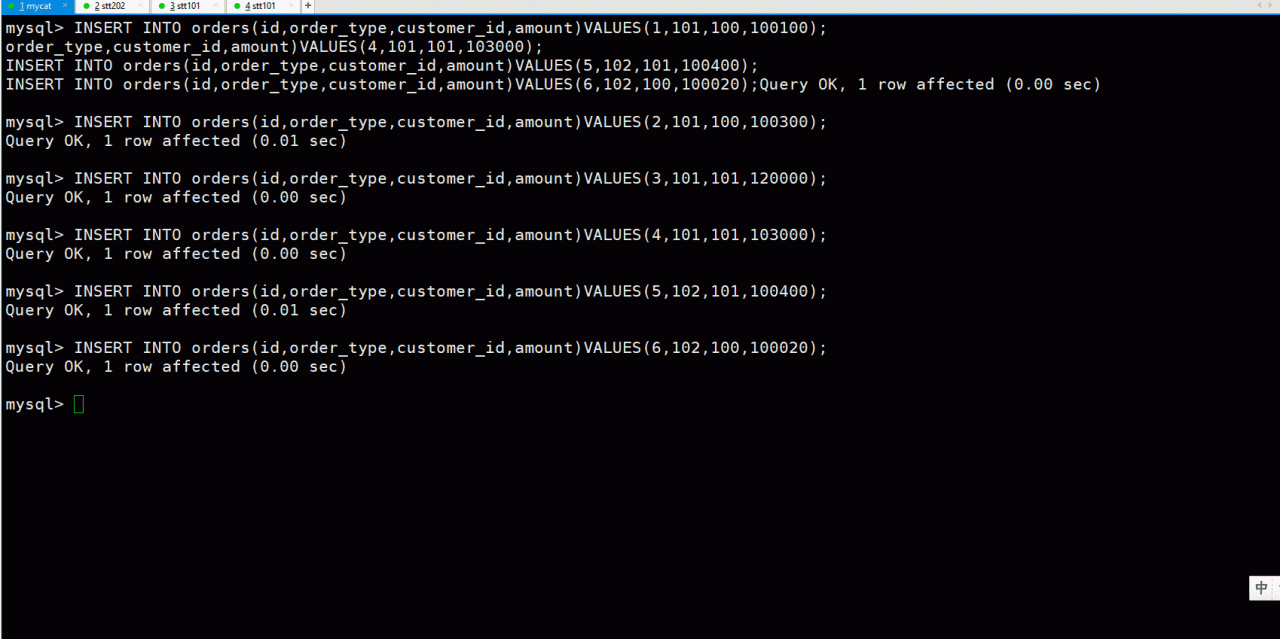
通过上图可以看出我们在mycat中添加6条数据,在mycat端可以全量查出,但是顺序并不是按照id排序的,如果想要飘絮可以使用order by语句,在stt201和stt202上分别查出3条数据,这样就实现了数据的水平拆分
水平拆分的join关联查询 在dn2上创建order_detail表,重启mycat插入数据再做查询
在dn2上创建order_detail表,重启mycat插入数据再做查询
-- 插入数据和查询都是在mycat端操作
-- 插入数据
INSERT INTO order_detail(id,detail,order_id)VALUES(1,'detail',1);
INSERT INTO order_detail(id,detail,order_id)VALUES(2,'detail',2);
INSERT INTO order_detail(id,detail,order_id)VALUES(3,'detail',3);
INSERT INTO order_detail(id,detail,order_id)VALUES(4,'detail',4);
INSERT INTO order_detail(id,detail,order_id)VALUES(5,'detail',5);
INSERT INTO order_detail(id,detail,order_id)VALUES(6,'detail',6);
-- 连接查询
SELECT * FROM orders o inner join order_detail od on o.id = od.order_id;

到此我们的垂直拆分和水平拆分就告一段落,当然还没有结束,真是XXXX了,咋还没完心态炸裂,不慌大家老规矩喝杯茶继续搞。
全局表 我们的业务表比如orders、order_detail表数据量很多时就需要切分,但是还一些附属表,比如我们这里的dict_order_type(字典表),他们之间也要关联,字典表数据并不多,数据变动不频繁进行切片就没有必要,这种表Mycat中定义为全局表
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');
INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');
我们查询数据在dn1和dn2都有完整的两条数据,虽然存在数据冗余,但是好在这些表中的数据并不多,不用切分实现JOIN查询
常用分片规则 我们在上边的例子中切分数据时使用的是取模切分,这里我们说一说其他开发中经常用到的数据切分方式
在配置文件中配置可能用到的枚举ID,自己设置分片,比如按照省份或者区县来做保存,而全国的省份区县是固定的,可以使用在这些场景下
修改schema.xml配置文件
修改rule.xml配置文件
areacode
hash-int
......
partition-hash-int.txt
1
0
修改partition-hash-int.txt配置文件
110=0
120=1
重启mycat,创建表插入数据
-- 创建表
CREATE TABLE orders_ware_info(
id INT AUTO_INCREMENT,
order_id INT,
address VARCHAR(20),
areacode VARCHAR,
PRIMARY KEY(id)
);
-- 插入数据
INSERT INTO orders_ware_info(id,order_id,address,areacode) VALUES (1,1,'北京','110');
INSERT INTO orders_ware_info(id,order_id,address,areacode) VALUES (2,2,'天津','120');

根据查询结果在mycat上查询是两条数据,在stt201上是北京,在stt202上是天津
范围约定分片比如我们的用户id,将0-100000、100001-200000等这些按照范围存储,适用于范围提前规定好的场景,我们这里使用一张支付信息表为例
配置schema.xml文件
配置rule.xml配置文件
order_id
rang-long
......
autopartition-long.txt
0
修改autopartition-long.txt文件
注意:将原本有的配置删除
0-102 = 0
103-200=1
重启mycat,创建表,插入数据
CREATE TABLE payment_info(
id INT AUTO_INCREMENT,
order_id INT,
payment_status INT,
PRIMARY KEY (id)
);
INSERT INTO payment_info(id,order_id,payment_status) VALUES (1,101,0);
INSERT INTO payment_info(id,order_id,payment_status) VALUES (2,102,1);
INSERT INTO payment_info(id,order_id,payment_status) VALUES (3,103,0);
INSERT INTO payment_info(id,order_id,payment_status) VALUES (4,104,1);

我们可以看到在mycat上查询全量数据,在stt201上展示两条,在stt202上展示两条,并且数据分布也正确
按照日期分片我们按照天进行划分,设定时间格式、范围
修改schema.xml配置文件
修改rule.xml配置文件
login_date
shardingByDate
......
yyyy-MM-dd
2020-04-01
2020-04-04
2
重启Mycat,创建表插入数据
CREATE TABLE login_info(
id INT AUTO_INCREMENT,
user_id INT,
login_date date,
PRIMARY KEY (id)
);
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2020-04-01');
INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2020-04-02');
INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2020-04-03');
INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2020-04-04');
INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2020-04-05');
INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2020-04-06');

看到效果,stt201上四条数据因为超过结束日期重新开始分区,stt202上两条数据,大家可以按照自己的想法去操作,看看是否和自己预想的效果一样,好好体会体会!到此我们完成了基于Mycat的数据库切分操作以及常用的切分方式作为参考
全局序列在分库分表的情况下,数据库自增主键已无法保证自增主键的唯一性,为此Mycat提供了全局序列,提供了本地配置和数据库配置多种实现方式
本地文件此方式Mycat将sequence配置到文件中,当使用到sequence中的配置后,Mycat会更新该值
优势:本地加载,读取速度较快 弊端:抗风险性差,mycat宕机无法读取配置文件,重启之后序列会重新开始,造成重复 数据库方式(推荐使用)利用数据库的一个表来进行累加,并不是每次生成序列都读写数据库,这样太慢,Mycat会预先加载一部分到Mycat内存中,这样大部分读写都在内存中完成,如果内存中号段用完Mycat再向数据库要一次
在dn1上创建MYCAT_SEQUENCE序列表CREATE TABLE MYCAT_SEQUENCE (
name VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY(name)
)ENGINE=InnoDB;
创建函数获取当前sequence的值
DELIMITER $
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET utf8
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT concat(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM MYCAT_SEQUENCE WHERE name = seq_name;
RETURN retval;
END $
DELIMITER ;
创建函数设置sequence的值
DELIMITER $
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),value INTEGER) RETURNS varchar(64) CHARSET utf8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END $
DELIMITER ;
创建函数获取下一个sequence的值
DELIMITER $
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET utf8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END $
DELIMITER ;
初始化序列表
-- 新增一条数据,序列名为ORDERS,初始值为400000,increment100,这个设置的是Mycat重启之后的值递增100,这个大家根据业务自己设置
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES('ORDERS',400000,100);
修改schmea.xml文件
前边为序列名后边为所在节点,我们序列名为ORDERS就是在dn1上创建的,如果你是在dn2上创建的序列表,则改为dn2
#sequence stored in datanode
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
ORDERS=dn1
修改server.xml文件

把改为1,配置使用序列的哪种方式,Mycat提供了三种方式,0为本地文件,1为数据库方式,2为时间戳方式
语法就是将ID的值改为next value for MYCATSEQ_SeqName咱么这里的序列名为ORDERS。
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (next value for MYCATSEQ_ORDERS,101,102,1000);
查询数据
SELECT * FROM orders;

全局序列ID=64位二进制(42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加))换算成十进制为18位的long类型,每毫秒可以并发12位二进制累加
优势:配置简单 弊端:太长 自主生成可以在项目中自己编写生成序列的代码,或者使用redis的incr生成序列,这种方式也行但是需要在程序中进行编码,我们还是推荐使用Mycat自带的全局序列,也就是第二种方式
总结 实现制定好切分方式或者说切分计划 准备好物理Mysql,这些Mysql应该都是白白的很干净的 安装好Mycat,配置Mycat的配置文件 启动Mycat创建表插入数据等操作,通过Mycat会将表和数据创建并且插入到真正的物理MySQL中维护 Mycat提供三种全局序列,解决分布式数据库主键ID唯一问题,我们使用数据库方式微信公众号搜索【达摩克利斯之笔】回复【资料】领取更多免费学习视频
欢迎评论区留言讨论

作者:添添长芝士