把手机上B站App缓存的视频转换为正常的mp4格式视频
首先想到的是,直接在电脑上下载,有许多软件可以实现这一功能,或者弄一个爬虫来爬,不过这么爬视频对我没啥用,还是直接下吧。
于是使用IDM这个软件,然而IDM只能一个个下载,而且文件名都要重新弄,下载下来的文件还被弄成了分段式的,或者音视频分开了,批量下载也是不用想了,没办法,还是只能自己想办法。
2.考虑到手机上下载比较方便,于是干脆从手机上批量下载,再搬到电脑上处理苹果的暂且不说,安卓上,B站的缓存文件一般存放在 \Android\data\tv.danmaku.bili\download 这样的路径下,照着这个路径应该就能找到,然后连跟数据线,直接把download里面所有文件搬到电脑上。
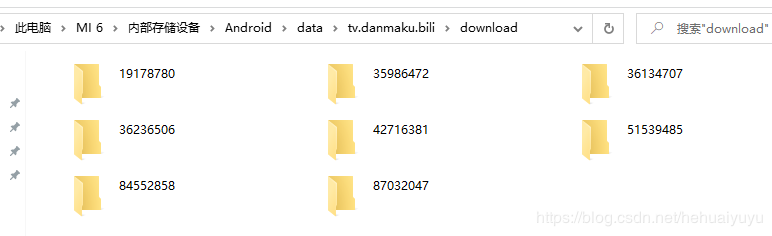
每一个文件夹下面是相应种类视频的分p:
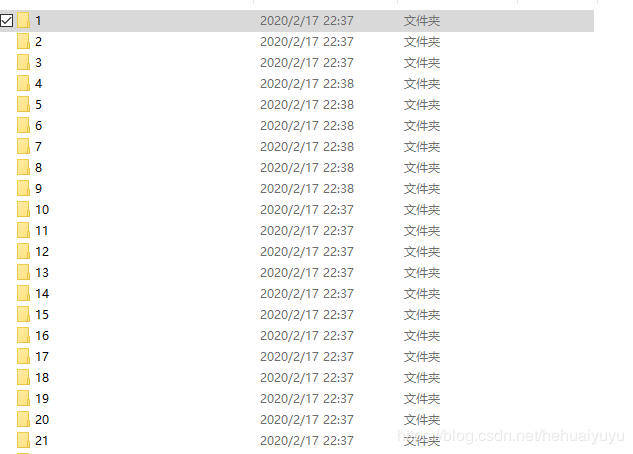
里面文件存放的方式居然还有两种,一种是比较新的:


还有一种比较老的:

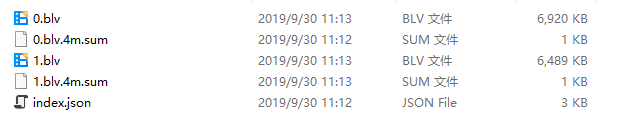
新的把音视频分开了,最里面的video.m4s 和 audio.m4s 两个文件就是我要的 ,看样子要把两个文件混流才行,而老的却是把视频分段了,直接拼起来就行了。
最简单粗暴的操作,考虑到格式工厂之类的音视频编辑软件,但是后缀名不对还识别不了,而且那么多的文件,一个个去操作实在愚蠢,于是考虑写个程序,让它自动去跑。
4.稍微写几行转换代码。(新的和老的所用代码稍微有些区别)这里使用的环境为windows、python3.7,python请尽量保持一致或更新的版本
要实现这样的功能,python有一个现成的轮子,叫moviepy,不过这个库有许多问题,而且在拼接的时候速度极为缓慢,于是干脆直接用ffmpeg
没有ffmpeg的,直接去官网下载,或者打开 powershell,输入以下命令安装:
choco install ffmpeg
提示没有choco命令的,打开 powershell 复制以下命令安装choco,再安装ffmpeg:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))
上面所说的老视频用这个(修改一下路径就行了):
import os
import json
# from moviepy.editor import *
# 待转换文件的路径,请修改为自己的
path = r"C:\待转换2"
# 转换完毕后的存放路径,可以修改为需要的
save_path = r"C:\转换完毕"
if __name__ == '__main__':
# 需要转换的所有目录名与文件名
all_title = []
all_video = []
# a:所在根目录; b:根目录下所有文件夹(以列表形式存在); c:根目录下所有文件(以列表形式存在)
for k, (a, b, c) in enumerate(os.walk(path)):
# 因为所有操作按顺序进行,所以一一对应
e = []
for i in c:
if i == 'entry.json':
title_path = os.path.join(a, i)
all_title.append(title_path)
elif os.path.splitext(i)[1] == '.blv':
video_path = os.path.join(a, i)
e.append(video_path)
all_video.append(e)
# 一个个打开对应路径文件
for i, j in enumerate(all_title):
with open(j, encoding='utf-8') as data:
title_ = json.load(data)
# 目录名
title1 = title_["title"].replace(" ", "")
# 视频名
title2 = title_["page_data"]["part"].replace(" ", "")
# 需要合成的同一个
print(f"输出目录:{title1}")
print(f"输出文件:{title2}")
_path = f"{save_path}/{title1}"
os.makedirs(_path, exist_ok=True)
with open(f"{title2}.txt", "w", encoding='utf-8') as w:
[w.write(f"file '{i}'\n") for i in all_video[i]]
cmd = f'ffmpeg -f concat -safe 0 -i {title2}.txt -c copy {_path}/{title2}.mp4'
os.system(cmd)
print("\n", "*" * 15, f"已完成{i + 1}个文件", "*" * 15)
新的视频用这个:
import os
import json
# 待转换文件的路径,请修改为自己的
path = r"D:\待转换"
# 转换完毕后的存放路径,可以修改为需要的
save_path = r"D:\转换完毕"
if __name__ == '__main__':
# 需要转换的所有目录名与文件名
all_title = []
all_video = []
all_audio = []
# a:所在根目录; b:根目录下所有文件夹(以列表形式存在); c:根目录下所有文件(以列表形式存在)
for k, (a, b, c) in enumerate(os.walk(path)):
# 因为所有操作按顺序进行,所以一一对应
for i in c:
if i == 'entry.json':
title_path = os.path.join(a, i)
all_title.append(title_path)
elif i == "video.m4s":
video_path = os.path.join(a, i)
all_video.append(video_path)
elif i == "audio.m4s":
audio_path = os.path.join(a, i)
all_audio.append(audio_path)
# 一个个打开对应路径文件
for i, j in enumerate(all_title):
with open(j, encoding='utf-8') as data:
title_ = json.load(data)
# 目录名
title1 = title_["title"].replace(" ", "")
# 视频名
title2 = title_["page_data"]["part"].replace(" ", "")
print(f"输出目录:{title1}")
print(f"输出文件:{title2}")
_path = f"{save_path}/{title1}"
os.makedirs(_path, exist_ok=True)
cmd = f'ffmpeg -i {all_video[i]} -i {all_audio[i]} {_path}/{title2}.mp4'
# python调用Shell脚本执行cmd命令
os.system(cmd)
print("\n", "*" * 15, f"已完成{i + 1}个文件", "*" * 15)
ps:老视频只是拼接一下,速度会非常的快,而新的视频需要音视频混流,所以速度比较慢,视电脑配置而定,像我的辣鸡电脑,40G的视频要跑上十几个钟头,要加快速度的话,可以考虑使用多线程。
作者:SuperYOLO