模型选择问题
模型选择问题
欠拟合和过拟合问题
当统计模型或机器学习算法无法捕捉数据的基础变化趋势时,就会出现欠拟合。
当统计模型把随机误差和噪声也考虑进去而不仅仅考虑数据的基础关联时,就会出现过拟合。
正则化
添加参数的惩罚项,防止模型对数据的过拟合。
regularization
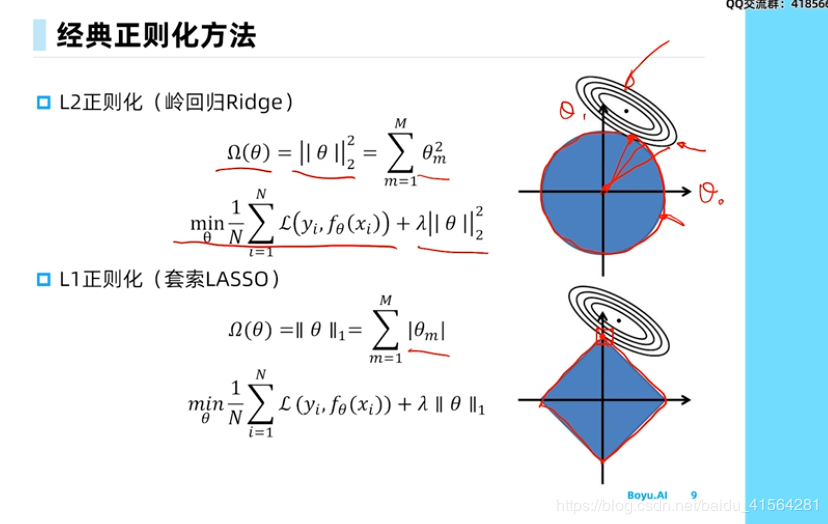
L2正则化 (岭回归Ridge)
L1正则化 (套锁LASSO)
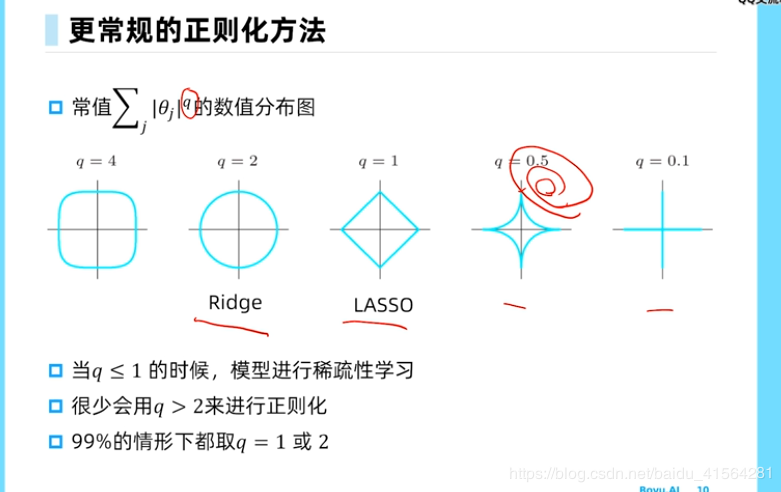
奥卡姆剃刀原则
尽量使得模型简单
有多个假设模型时,我们应该选择假设条件最少的建模方法
原始损失 + 基于假设的损失
超参数
定义模型的更高层次的概念,无法从数据中学习。
交叉验证
选择了“好的”超参数后,对整个训练数据进行模型训练,然后用测试数据对模型进行测试。
作者:baidu_41564281
相关文章
Rebecca
2021-05-19
Tia
2023-04-18
Pandora
2023-05-02
Dulcea
2023-05-02
Kirima
2023-05-12
Kalika
2023-05-12
Jacinda
2023-05-13
Bella
2023-05-13
Olivia
2023-05-16
Fawn
2023-05-16
Tanisha
2023-05-27
Pandora
2023-07-01
Xanthe
2023-07-20
Samira
2023-07-20
Carly
2023-07-20
Irma
2023-07-20
Posy
2023-07-20