Max Pooling和 Average Pooling的区别,使用场景分别是什么?
池化操作时在卷积神经网络中经常采用过的一个基本操作,一般在卷积层后面都会接一个池化操作,但是近些年比较主流的ImageNet上的分类算法模型都是使用的max-pooling,很少使用average-pooling,这对我们平时设计模型时确实有比较重要的参考作用,但是原因在哪里呢?
pooling作为一个对特征的操作,应该看具体任务。有论文提到,低层的网络对细节特征的响应更高,那么随着对特征的不断处理,高层的网络对抽象特征有更好的响应。pooling作为对特征的处理操作,也应该考虑,pooling前的数据是什么数据,数据代表了什么意义,数据的相关性是怎么样的。假设区分由不同点集构成的“A”和"P",这两个数据集中的相临数据间的位置相关性不大(从NN的角度看,当然从图形学提取特征就另说了),那么我觉得,你可以用一个平均值的pooling来作为一个特征提取的手段。而如果通过一个卷积核处理后的数据里面的某个信息是很有效的,譬如说其中可能出现很大的值,而这个值对结果影响很大,那么你可以用max的pooling
pooling的主要作用一方面是去掉冗余信息,一方面要保留feature map的特征信息,同时降低参数量
通常来讲,max-pooling的效果更好,虽然max-pooling和average-pooling都对数据做了下采样,但是max-pooling感觉更像是做了特征选择,选出了分类辨识度更好的特征,提供了非线性。这就类似于nms(非极大抑制),一方面能抑制噪声,另一方面能提升特征图在区域内的显著性(筛选出的极大值)。
根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大; (2)卷积层参数误差造成估计均值的偏移。一般来说,average-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
average-pooling更强调对整体特征信息进行一层下采样,在减少参数维度的贡献上更大一点,更多的体现在信息的完整传递这个维度上,在一个很大很有代表性的模型中,比如说DenseNet中的模块之间的连接大多采用average-pooling,在减少维度的同时,更有利信息传递到下一个模块进行特征提取。
但是average-pooling在全局平均池化(global average pooling)操作中应用也比较广,在ResNet和Inception结构中最后一层都使用了平均池化。有的时候在模型接近分类器的末端使用全局平均池化还可以代替Flatten操作,使输入数据变成一维向量。
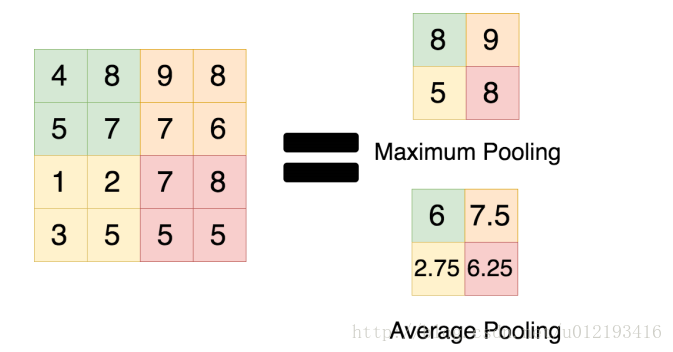
max-pooling和average-pooling的使用性能对于我们设计卷积网络还是很有用的,虽然池化操作对于整体精度提升效果也不大,但是在减参,控制过拟合以及提高模型性能,节约计算力上的作用还是很明显的,所以池化操作时卷积设计上不可缺少的一个操作。
作者:ytusdc