机器学习推导+python实现(二):逻辑回归
写在开头:今天开始逻辑回归的内容分享,仍然是参考学习公众号机器学习实验室的思路和内容,尽量在实现的环节多加一些自己的思考,吸收一下。
内容安排线性回归(一)、逻辑回归(二)、K近邻(三)、决策树值ID3(四)、CART(五)、感知机(六)、神经网络(七)、线性可分支持向量机(八)、线性支持向量机(九)、线性不可分支持向量机(十)、朴素贝叶斯(十一)、Lasso回归(十二)、Ridge岭回归(十三)等。
今天就是从逻辑回归的内容进行分享,逻辑回归的思想其实在现实生活中很常见,比如通过一段编程的能力来定义这个人是不是高手如何,其实里面的自变量比如有算法的能力、代码的能力等等,这其实都和逻辑回归很类似。说到底逻辑回归就是想通过已有的自变量数据,来预测这个样本属于哪一类。之前在学习逻辑回归的时候,在思考一个问题,如果训练集中从未出现过那一类,但是测试集里又实实在在的有这样首次出现的类别样本,逻辑回归应该怎么应付。最后思来想去,觉得没法应付,后面了解到有聚类分析,能够无监督的进行学习,这样的话对于那些首次的样本就可以单独为一类。我觉得这其实就是无监督学习的一个能力所在。话题说远了,接下来让我们开始逻辑回归的内容吧。
这里让参考部分书籍的相关公式,遇到的时候会在公式附近添加说明,在介绍逻辑回归函数形式的时候呢,根据周志华老师的“西瓜书”的安排,我们来先介绍一下sigmoid函数,由于这几天才把激活函数的文章写了一下,对sigmoid的印象还是很深刻的,sigomid不管是在激活函数还是在构造逻辑回归上,作用都是将数值压缩到0到1之间,只是说两者压缩后的目的不一样,一个是为了非线性处理神经元,一个是为了概率预测,那么感兴趣的朋友可以点击这里查看激活函数中的sigmoid,不过在这里还是展示一下该函数的公式和图像,
σ(x)=11+e−x\sigma(x)=\frac{1}{1+e^{-x}}σ(x)=1+e−x1

从图像来看,当我们输入的值越小就会使得,sigmoid函数的输出值越接近于0,反之就越接近1。于是我们可以将这个看作一个概率,大于0.5就为正例类,小于0.5就为反例类,除此之外,还因为sigmoid的函数求导后导函数为,
dσ(x)dx=e−x(1+e−x)2=1(1+e−x)−1(1+e−x)2=σ(x)(1−σ(x))\frac{d\sigma (x)}{dx}=\frac{e^{-x}}{(1+e^{-x})^2}=\frac{1}{(1+e^{-x})}-\frac{1}{(1+e^{-x})^2}=\sigma (x)(1-\sigma (x))dxdσ(x)=(1+e−x)2e−x=(1+e−x)1−(1+e−x)21=σ(x)(1−σ(x)),在计算梯度的时候比较方便,所以又能够看作概率,有方便求导计算所以就很适合做我们的分类函数的选择。但是只有一个x肯定是不够的,就像之前举的例子一样,我们衡量一个人是不是高手还得从多个角度入手,于是这里需要引入一个多元信息,那么就迎来了我们的逻辑回归函数,
y=11+e−(wTx+b)y=\frac{1}{1+e^{-(w^Tx+b)}}y=1+e−(wTx+b)1更换的地方就是将x变更为了矩阵运算形式,与此系列上一节的多元线性回归形式类似,顺便把记号换成y,和回归接轨,在学习了上一节线性函数基础上的情况下,我们尝试着把公式变得和线性回归差不多,于是公式变形为,
ln(y1−y)=wTx+bln(\frac{y}{1-y})=w^Tx+bln(1−yy)=wTx+b这样的形式是不是就和线性回归的很像了,左侧对数里的y/(1−y)y/(1-y)y/(1−y)可以理解为几率,因为yyy反应的是x为正的可能性,于是几率就可以理解成反应相对的一个概率,然后左侧就是对数几率,其实感觉左侧这个公式就是用右侧的线性回归去拟合。以一种更加概率的形式来展示一下这个公式,
ln(p(y=1∣x)p(y=0∣x))=wTx+bln(\frac{p(y=1|x)}{p(y=0|x)})=w^Tx+bln(p(y=0∣x)p(y=1∣x))=wTx+b然后等于1和等于0的概率就为,
p(y=1∣x)=e(wTx+b)1+e(wTx+b)p(y=1|x)=\frac{e^{(w^Tx+b)}}{1+e^{(w^Tx+b)}}p(y=1∣x)=1+e(wTx+b)e(wTx+b)p(y=0∣x)=11+e(wTx+b)p(y=0|x)=\frac{1}{1+e^{(w^Tx+b)}}p(y=0∣x)=1+e(wTx+b)1
下面需要来定义损失函数,在线性回归中我们使用的是MSE均方误差,在这里我们使用交叉熵误差,下面是交叉熵误差的来由,其实就是通过极大似然估计得到,希望通过极大似然估计来得到参数的估计值,于是就先得到模型的对数似然函数,这里的操作是对于每一类进行对数似然,
L=∑i=1mlnp(yi∣xi;w,b)L=\sum\limits_{i=1}^{m}lnp(y_i|x_i;w,b)L=i=1∑mlnp(yi∣xi;w,b)这里的yi,xiy_i,x_iyi,xi是给定样本,这个公式就是希望每个样本xix_ixi等于本身类的概率越大越好,然后我们将p(yi∣xi;w,b)p(y_i|x_i;w,b)p(yi∣xi;w,b)进行展开,
p(yi∣xi;w,b)=p(y=1∣xi)yi×p(y=0∣xi)1−yip(y_i|x_i;w,b)=p(y=1|x_i)^{y_i}\times p(y=0|x_i)^{1-y_i}p(yi∣xi;w,b)=p(y=1∣xi)yi×p(y=0∣xi)1−yi然后将这个式子代入对数似然函数,注意这里不是直接将公示代入
L=∑i=1myiln(p(y=1∣xi))+(1−yi)ln(p(y=0∣xi))L=\sum\limits_{i=1}^{m}y_iln(p(y=1|x_i))+(1-y_i)ln(p(y=0|x_i))L=i=1∑myiln(p(y=1∣xi))+(1−yi)ln(p(y=0∣xi)) 然后考虑到这个是寻找最大的似然函数,我们需要构建损失函数,即最小的损失也就是似然函数的对偶形式,于是即得到损失函数为,
E(w,b)=−1m∑i=1myiln(p(y=1∣xi))+(1−yi)ln(p(y=0∣xi))E(w,b)= -\frac{1}{m}\sum\limits_{i=1}^{m}y_iln(p(y=1|x_i))+(1-y_i)ln(p(y=0|x_i))E(w,b)=−m1i=1∑myiln(p(y=1∣xi))+(1−yi)ln(p(y=0∣xi))其最优解为,w∗,b∗=arg min(w,b) −1m∑i=1myiln(p(y=1∣xi))+(1−yi)ln(p(y=0∣xi))w^*,b^*={\underset {(w,b)}{\operatorname {arg\,min} }}\ -\frac{1}{m}\sum\limits_{i=1}^{m}y_iln(p(y=1|x_i))+(1-y_i)ln(p(y=0|x_i))w∗,b∗=(w,b)argmin −m1i=1∑myiln(p(y=1∣xi))+(1−yi)ln(p(y=0∣xi))=arg min(w,b) −1m∑i=1myiln(e(wTx+b)1+e(wTx+b))+(1−yi)ln(11+e(wTx+b)) ={\underset {(w,b)}{\operatorname {arg\,min} }}\ -\frac{1}{m}\sum\limits_{i=1}^{m}y_iln(\frac{e^{(w^Tx+b)}}{1+e^{(w^Tx+b)}})+(1-y_i)ln(\frac{1}{1+e^{(w^Tx+b)}})=(w,b)argmin −m1i=1∑myiln(1+e(wTx+b)e(wTx+b))+(1−yi)ln(1+e(wTx+b)1)这里为了方便看,我们令σ(w,b)=e(wTx+b)1+e(wTx+b)\sigma(w,b)=\frac{e^{(w^Tx+b)}}{1+e^{(w^Tx+b)}}σ(w,b)=1+e(wTx+b)e(wTx+b),于是损失函数就为,
E(w,b)=−1m∑i=1myiln(σ(w,b))+(1−yi)ln(1−σ(w,b))E(w,b)= -\frac{1}{m}\sum\limits_{i=1}^{m}y_iln(\sigma(w,b))+(1-y_i)ln(1-\sigma(w,b))E(w,b)=−m1i=1∑myiln(σ(w,b))+(1−yi)ln(1−σ(w,b))
下面就需要对逻辑回归的损失函数进行求偏导,计算过程如下,
∂E(w,b)∂w=−1m∑i=1myi1σ(w,b)∂σ(w,b)∂(wxi+b)∂(wxi+b)∂w+(1−yi)11−σ(w,b)∂(1−σ(w,b))∂(wxi+b)∂(wxi+b)∂w\frac{\partial E(w,b)}{\partial w}=-\frac{1}{m}\sum\limits_{i=1}^{m}y_i\frac{1}{\sigma(w,b)}\frac{\partial \sigma(w,b)}{\partial (wx_i+b)}\frac{\partial (wx_i+b)}{\partial w}+(1-y_i)\frac{1}{1-\sigma(w,b)}\frac{\partial(1- \sigma(w,b))}{\partial (wx_i+b)}\frac{\partial (wx_i+b)}{\partial w}∂w∂E(w,b)=−m1i=1∑myiσ(w,b)1∂(wxi+b)∂σ(w,b)∂w∂(wxi+b)+(1−yi)1−σ(w,b)1∂(wxi+b)∂(1−σ(w,b))∂w∂(wxi+b)
=−1m∑i=1myi1σ(w,b)σ(w,b)(1−σ(w,b))∂(wxi+b)∂w+(yi−1)11−σ(w,b)σ(w,b)(1−σ(w,b))∂(wxi+b)∂w=-\frac{1}{m}\sum\limits_{i=1}^{m}y_i\frac{1}{\sigma(w,b)}\sigma(w,b)(1-\sigma(w,b))\frac{\partial (wx_i+b)}{\partial w} +(y_i-1)\frac{1}{1-\sigma(w,b)}\sigma(w,b)(1-\sigma(w,b))\frac{\partial (wx_i+b)}{\partial w}=−m1i=1∑myiσ(w,b)1σ(w,b)(1−σ(w,b))∂w∂(wxi+b)+(yi−1)1−σ(w,b)1σ(w,b)(1−σ(w,b))∂w∂(wxi+b)
=−1m∑i=1myi(1−σ(w,b))x+(yi−1)σ(w,b)xi=-\frac{1}{m}\sum\limits_{i=1}^{m}y_i(1-\sigma(w,b))x +(y_i-1)\sigma(w,b)x_i=−m1i=1∑myi(1−σ(w,b))x+(yi−1)σ(w,b)xi
=1m∑i=1m(σ(w,b)−yi)xi=\frac{1}{m}\sum\limits_{i=1}^{m}(\sigma(w,b)-y_i)x_i=m1i=1∑m(σ(w,b)−yi)xi
=1m∑i=1m(y^i−yi)xi=\frac{1}{m}\sum\limits_{i=1}^{m}(\hat {y}_i-y_i)x_i=m1i=1∑m(y^i−yi)xi
同理对于b的导数计算一样,得到
∂E(w,b)∂w=1m∑i=1m(y^i−yi)xi\frac{\partial E(w,b)}{\partial w}=\frac{1}{m}\sum\limits_{i=1}^{m}(\hat {y}_i-y_i)x_i∂w∂E(w,b)=m1i=1∑m(y^i−yi)xi∂E(w,b)∂b=1m∑i=1m(y^i−yi)\frac{\partial E(w,b)}{\partial b}=\frac{1}{m}\sum\limits_{i=1}^{m}(\hat {y}_i-y_i)∂b∂E(w,b)=m1i=1∑m(y^i−yi)既然得到了分类函数、损失函数和梯度,下面就通过随机梯度下降的方法来更新梯度,寻找最优解,具体代码如下。
首先应该是定义的sigmoid函数,因为这个函数时这个逻辑回归的核心,
import numpy as np
def sigmoid(x):
return 1/(1 + np.exp(-x))
然后定义的是我们模型的核心,得分函数,损失函数与梯度,
def lrmodel(X, y, W, b):
num_Train = X.shape[0]
y_hat = sigmoid(np.dot(X, W) + b)
loss = -1/num_Train * np.sum(y * np.log(y_hat) + (1-y)*np.log(1-y_hat))
dW = 1/num_Train * np.dot(X.T, y_hat-y)
db = 1/num_Train * np.sum(y_hat-y)
return y_hat, loss, dW, db
初始化参数的部分,
def initial(d):
W = np.zeros((d, 1)) + 0.01
b = 0.01
return W, b
然后构造训练函数与测试函数,
def train(X, y, lr = 0.001, item_num = 1000):
W, b = initial(X.shape[1])
loss_hist = []
ranning_loss = 0
for it in range(1,item_num):
y_hat, loss, dW, db = lrmodel(X, y, W, b)
W += -lr * dW
b += -lr * db
ranning_loss += loss
if it % 100 == 99:
loss_hist.append(loss)
print("%d it loss %f"%(it+1,ranning_loss/100))
ranning_loss = 0
params = {
'W':W,
'b':b
}
grads = {
'dW':dW,
'db':db
}
return loss_hist, params, grads
def test(X, params):
W, b = params['W'], params['b']
y_pred = sigmoid(np.dot(X, W)+b)
y_pred[y_pred>0.5] = 1
y_pred[y_pred<=0.5] = 0
return y_pred
然后就该开始生成数据了,我们在这里使用sklearn里面的生成数据函数来生成二分类数据,
from sklearn.datasets.samples_generator import make_classification
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
def get_data():
X,y=make_classification(n_samples=400,n_features=2,n_redundant=0,n_clusters_per_class=1,n_classes=2)
data = pd.DataFrame({
'X1':X[:,0],
'X2':X[:,1],
'y':y
})
sns.scatterplot(x='X1', y='X2', data=data, hue='y', palette="Set2")
plt.show()
return X, y
让我们一起来看一下数据是啥样的,再来划分一下训练集和测试集,
X, y = get_data()
offset = int(X.shape[0]*0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
print("Xtrain:",X_train.shape)
print("Xtest:",X_test.shape)
print("ytrain:",y_train.shape)
print("ytest:",y_test.shape)
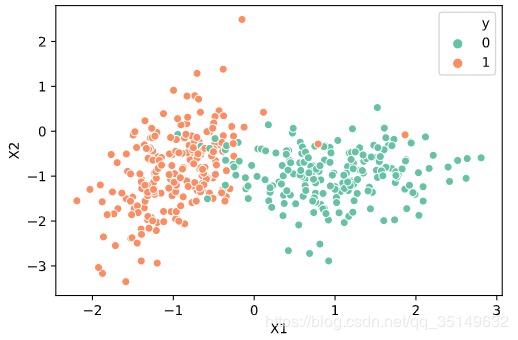
Xtrain: (360, 2)
Xtest: (40, 2)
ytrain: (360, 1)
ytest: (40, 1)
然后就可以开始训练啦,
loss_hist, parmas, grads = train(X_train, y_train, lr=0.01, item_num=1000)
100 it loss 0.593287
200 it loss 0.463263
300 it loss 0.384163
400 it loss 0.333762
500 it loss 0.299031
600 it loss 0.273666
700 it loss 0.254315
800 it loss 0.239049
900 it loss 0.226686
1000 it loss 0.216458
再来看看测试集的预测效果咋样,
y_pred = test(X_test, parmas)
print("acc = %f"%np.mean(y_pred == y_test))
acc = 0.875
这里的预测准确度是87.5%,效果还是很不错的,最后我们在通过可视化,来看看我们得到的wTx+bw^Tx+bwTx+b这条线的是怎么存在于数据之中的把,
def plot_logistic(params, X, y):
data = pd.DataFrame({
'X1':X[:,0],
'X2':X[:,1],
'y':y
})
ax = sns.scatterplot(x='X1', y='X2', data=data, hue='y', palette="Set2")
x1 = np.arange(-2,3,0.1)
y1 = (-params['b'] - parmas['W'][0]*x1)/params['W'][1]
plt.plot(x1,y1)
plt.ylim(-3,2.5)
plt.show()
plot_logistic(params, X, y)
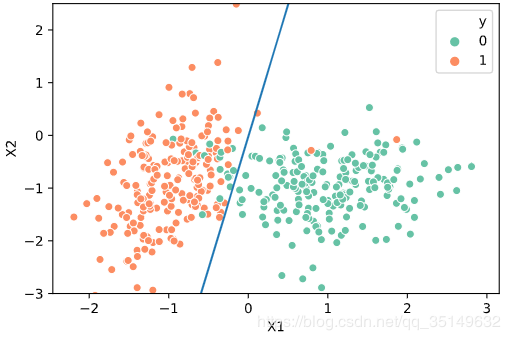
从图中可以看到除了个别点没有划分进来以外,逻辑回归的表现还是很不错的。最后的最后还是按照习惯,将今天的程序进行封装,代码如下,
import numpy as np
from sklearn.datasets.samples_generator import make_classification
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
class LogisticRegression():
def __init__(self):
pass
def get_data(self):
X, y=make_classification(n_samples=400,n_features=2,n_redundant=0,n_clusters_per_class=1,n_classes=2)
data = pd.DataFrame({
'X1':X[:,0],
'X2':X[:,1],
'y':y
})
sns.scatterplot(x='X1', y='X2', data=data, hue='y', palette="Set2")
plt.show()
return X, y
def train_test(self, X, y):
offset = int(X.shape[0]*0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
print("Xtrain:",X_train.shape)
print("Xtest:",X_test.shape)
print("ytrain:",y_train.shape)
print("ytest:",y_test.shape)
return X_train, y_train, X_test, y_test
def sigmoid(self, x):
return 1/(1 + np.exp(-x))
def lrmodel(self, X, y, W, b):
num_Train = X.shape[0]
y_hat = self.sigmoid(np.dot(X, W) + b)
loss = -1/num_Train * np.sum(y * np.log(y_hat) + (1-y)*np.log(1-y_hat))
dW = 1/num_Train * np.dot(X.T, y_hat-y)
db = 1/num_Train * np.sum(y_hat-y)
return y_hat, loss, dW, db
def initial(self, d):
W = np.zeros((d, 1)) + 0.01
b = 0.01
return W, b
def train(self, X, y, lr = 0.001, item_num = 1000):
W, b = self.initial(X.shape[1])
loss_hist = []
ranning_loss = 0
for it in range(1,item_num):
y_hat, loss, dW, db = self.lrmodel(X, y, W, b)
W += -lr * dW
b += -lr * db
ranning_loss += loss
if it % 100 == 99:
loss_hist.append(loss)
print("%d it loss %f"%(it+1,ranning_loss/100))
ranning_loss = 0
params = {
'W':W,
'b':b
}
grads = {
'dW':dW,
'db':db
}
return loss_hist, params, grads
def test(self, X, params):
W, b = params['W'], params['b']
y_pred = self.sigmoid(np.dot(X, W)+b)
y_pred[y_pred>0.5] = 1
y_pred[y_pred<=0.5] = 0
return y_pred
def plot_logistic(self, params, X, y):
data = pd.DataFrame({
'X1':X[:,0],
'X2':X[:,1],
'y':y
})
ax = sns.scatterplot(x='X1', y='X2', data=data, hue='y', palette="Set2")
x1 = np.arange(-2,3,0.1)
y1 = (-params['b'] - parmas['W'][0]*x1)/params['W'][1]
plt.plot(x1,y1)
plt.ylim(-3,2.5)
plt.show()
if __name__ == "__main__":
Logit = LogisticRegression()
X, y = Logit.get_data()
X_train, y_train, X_test, y_test = Logit.train_test(X, y)
loss_hist, params, grads = Logit.train(X_train, y_train, lr=0.01, item_num=1000)
y_pred = Logit.test(X_test, params)
print("this acc = %f"%np.mean(y_pred == y_test))
Logit.plot_logistic(params, X, y)
结语
今天对于逻辑回归的分享就到这里啦。
参考
公众号:机器学习实验室
作者:明曦君