详细聊聊MySQL中的LIMIT语句
问题
server层和存储引擎层
那LIMIT是什么鬼?
怎么办?
吐个槽
最近有多个小伙伴在答疑群里问了小孩子关于LIMIT的一个问题,下边我来大致描述一下这个问题。
问题为了故事的顺利发展,我们得先有个表:
CREATE TABLE t (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1)
) Engine=InnoDB CHARSET=utf8;
表t包含3个列,id列是主键,key1列是二级索引列。表中包含1万条记录。
当我们执行下边这个语句的时候,是使用二级索引idx_key1的:
mysql> EXPLAIN SELECT * FROM t ORDER BY key1 LIMIT 1;
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+
| 1 | SIMPLE | t | NULL | index | NULL | idx_key1 | 303 | NULL | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
这个很好理解,因为在二级索引idx_key1中,key1列是有序的。而查询是要取按照key1列排序的第1条记录,那MySQL只需要从idx_key1中获取到第一条二级索引记录,然后直接回表取得完整的记录即可。
但是如果我们把上边语句的LIMIT 1换成LIMIT 5000, 1,则却需要进行全表扫描,并进行filesort,执行计划如下:
mysql> EXPLAIN SELECT * FROM t ORDER BY key1 LIMIT 5000, 1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 9966 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
有的同学就很不理解了:LIMIT 5000, 1也可以使用二级索引idx_key1呀,我们可以先扫描到第5001条二级索引记录,对第5001条二级索引记录进行回表操作不就好了么,这样的代价肯定比全表扫描+filesort强呀。
很遗憾的告诉各位,由于MySQL实现上的缺陷,不会出现上述的理想情况,它只会笨笨的去执行全表扫描+filesort,下边我们唠叨一下到底是咋回事儿。
server层和存储引擎层大家都知道,MySQL内部其实是分为server层和存储引擎层的:
server层负责处理一些通用的事情,诸如连接管理、SQL语法解析、分析执行计划之类的东西
存储引擎层负责具体的数据存储,诸如数据是存储到文件上还是内存里,具体的存储格式是什么样的之类的。我们现在基本都使用InnoDB存储引擎,其他存储引擎使用的非常少了,所以我们也就不涉及其他存储引擎了。
MySQL中一条SQL语句的执行是通过server层和存储引擎层的多次交互才能得到最终结果的。比方说下边这个查询:
SELECT * FROM t WHERE key1 > 'a' AND key1 < 'b' AND common_field != 'a';
server层会分析到上述语句可以使用下边两种方案执行:
方案一:使用全表扫描
方案二:使用二级索引idx_key1,此时需要扫描key1列值在('a', 'b')之间的全部二级索引记录,并且每条二级索引记录都需要进行回表操作。
server层会分析上述两个方案哪个成本更低,然后选取成本更低的那个方案作为执行计划。然后就调用存储引擎提供的接口来真正的执行查询了。
这里假设采用方案二,也就是使用二级索引idx_key1执行上述查询。那么server层和存储引擎层的对话可以如下所示:

server层:“hey,麻烦去查查idx_key1二级索引的('a', 'b')区间的第一条记录,然后把回表后把完整的记录返给我哈”
InnoDB:“收到,这就去查”,然后InnoDB就通过idx_key1二级索引对应的B+树,快速定位到扫描区间('a', 'b')的第一条二级索引记录,然后进行回表,得到完整的聚簇索引记录返回给server层。
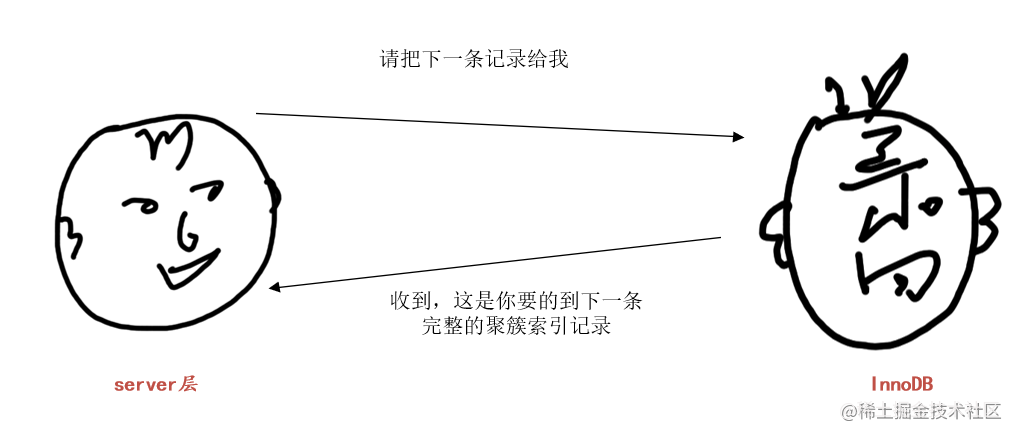
server层收到完整的聚簇索引记录后,继续判断common_field!='a'条件是否成立,如果不成立则舍弃该记录,否则将该记录发送到客户端。然后对存储引擎说:“请把下一条记录给我哈”
小贴士:
此处将记录发送给客户端其实是发送到本地的网络缓冲区,缓冲区大小由net_buffer_length控制,默认是16KB大小。等缓冲区满了才真正发送网络包到客户端。
InnoDB:“收到,这就去查”。InnoDB根据记录的next_record属性找到idx_key1的('a', 'b')区间的下一条二级索引记录,然后进行回表操作,将得到的完整的聚簇索引记录返回给server层。
小贴士:
不论是聚簇索引记录还是二级索引记录,都包含一个称作next_record的属性,各个记录根据next_record连成了一个链表,并且链表中的记录是按照键值排序的(对于聚簇索引来说,键值指的是主键的值,对于二级索引记录来说,键值指的是二级索引列的值)。
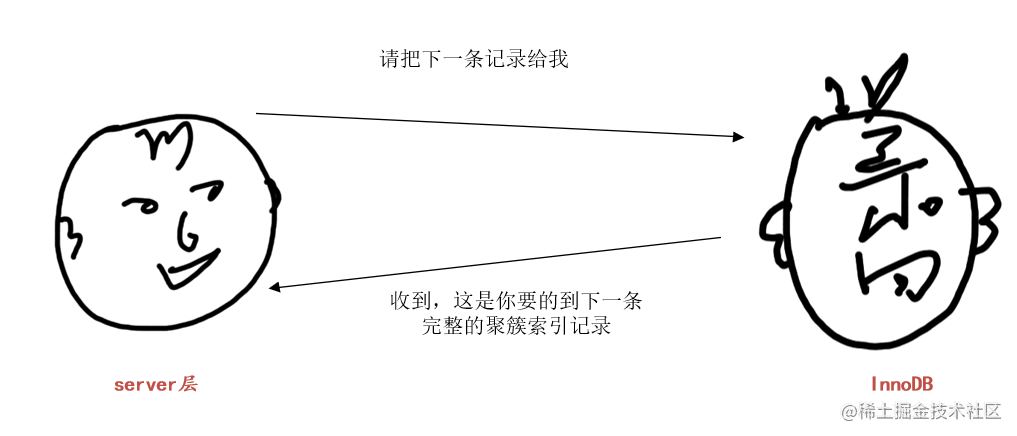
server层收到完整的聚簇索引记录后,继续判断common_field!='a'条件是否成立,如果不成立则舍弃该记录,否则将该记录发送到客户端。然后对存储引擎说:“请把下一条记录给我哈”
... 然后就不停的重复上述过程。
直到:
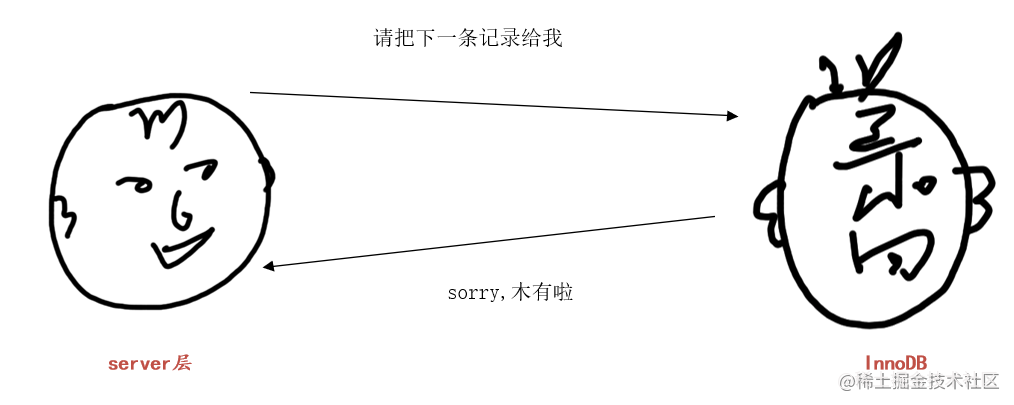
也就是直到InnoDB发现根据二级索引记录的next_record获取到的下一条二级索引记录不在('a', 'b')区间中,就跟server层说:“好了,('a', 'b')区间没有下一条记录了”
server层收到InnoDB说的没有下一条记录的消息,就结束查询。
现在大家就知道了server层和存储引擎层的基本交互过程了。
那LIMIT是什么鬼?说出来大家可能有点儿惊讶,MySQL是在server层准备向客户端发送记录的时候才会去处理LIMIT子句中的内容。拿下边这个语句举例子:
SELECT * FROM t ORDER BY key1 LIMIT 5000, 1;
如果使用idx_key1执行上述查询,那么MySQL会这样处理:
server层向InnoDB要第1条记录,InnoDB从idx_key1中获取到第一条二级索引记录,然后进行回表操作得到完整的聚簇索引记录,然后返回给server层。server层准备将其发送给客户端,此时发现还有个LIMIT 5000, 1的要求,意味着符合条件的记录中的第5001条才可以真正发送给客户端,所以在这里先做个统计,我们假设server层维护了一个称作limit_count的变量用于统计已经跳过了多少条记录,此时就应该将limit_count设置为1。
server层再向InnoDB要下一条记录,InnoDB再根据二级索引记录的next_record属性找到下一条二级索引记录,再次进行回表得到完整的聚簇索引记录返回给server层。server层在将其发送给客户端的时候发现limit_count才是1,所以就放弃发送到客户端的操作,将limit_count加1,此时limit_count变为了2。
... 重复上述操作
直到limit_count等于5000的时候,server层才会真正的将InnoDB返回的完整聚簇索引记录发送给客户端。
从上述过程中我们可以看到,由于MySQL中是在实际向客户端发送记录前才会去判断LIMIT子句是否符合要求,所以如果使用二级索引执行上述查询的话,意味着要进行5001次回表操作。server层在进行执行计划分析的时候会觉得执行这么多次回表的成本太大了,还不如直接全表扫描+filesort快呢,所以就选择了后者执行查询。
怎么办?由于MySQL实现LIMIT子句的局限性,在处理诸如LIMIT 5000, 1这样的语句时就无法通过使用二级索引来加快查询速度了么?其实也不是,只要把上述语句改写成:
SELECT * FROM t, (SELECT id FROM t ORDER BY key1 LIMIT 5000, 1) AS d
WHERE t.id = d.id;
这样,SELECT id FROM t ORDER BY key1 LIMIT 5000, 1作为一个子查询单独存在,由于该子查询的查询列表只有一个id列,MySQL可以通过仅扫描二级索引idx_key1执行该子查询,然后再根据子查询中获得到的主键值去表t中进行查找。
这样就省去了前5000条记录的回表操作,从而大大提升了查询效率!
吐个槽设计MySQL的大叔啥时候能改改LIMIT子句的这种超笨的实现呢?还得用户手动想欺骗优化器的方案才能提升查询效率~
到此这篇关于MySQL中LIMIT语句的文章就介绍到这了,更多相关MySQL的LIMIT语句内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!