联邦学习(Federated Learning)分类及架构设计
联邦学习(Federated Learning)分类及架构设计1、联邦学习起源2、联邦学习定义3、联邦学习的隐私保护机制4、联邦学习分类4.1 水平/横向联邦学习(Horizontal Federated Learning)4.2 垂直/纵向联邦学习(Vertical Federated Learning)4.3 联邦迁移学习( Federated Transfer Learning)5、联邦学习系统架构5.1 水平联邦学习系统架构5.2 垂直联邦学习系统架构5.3 联邦迁移学习系统架构5.4 联邦学习激励机制6、联邦学习的应用
(声明:本文参考论文“Federated Machine Learning: Concept and Applications”)
1、联邦学习起源
\qquad联邦学习(Federated Learning)是一种新兴的人工智能基础技术,谷歌在2016年最先提出联邦学习的概念,其主要思想是基于多个设备上的数据集构建机器学习模型,同时防止数据泄露。在此基础上,后来的学者进一步研究更安全、更个性化的联邦学习机制,并在数据分布不平衡、用户管理机制等方向进行优化。微众银行首席人工智能官杨强教授在2019世界人工智能大会(WAIC)演讲时表示,未来行业面临的社会大众的要求和监管会越来越严格,联邦学习能够在满足用户隐私保护和数据安全需求的同时,实现多方共赢。
2、联邦学习定义
\qquad定义N个数据拥有方{F1,⋯ ,FN}\left\{ {{F^1}, \cdots ,{F^N}} \right\}{F1,⋯,FN},各方都期望整合各自的数据集{D1,⋯ ,DN}\left\{ {{D^1}, \cdots ,{D^N}} \right\}{D1,⋯,DN}的训练机器学习模型。常规的方法是将所有的数据集成D=D1∪,⋯ ,∪DN{D = {{D^1}\cup,\cdots ,\cup{D^N}} }D=D1∪,⋯,∪DN训练一个机器学习模型MSUM{M_{SUM}}MSUM 。而联邦学习系统是各数据拥有方作为协作单元训练出模型MFED{M_{FED}}MFED,无需将自己的数据暴露给其他数据方。并且联邦学习训练出的模型MFED{M_{FED}}MFED的准确率VFED{V_{FED}}VFED非常接近于MSUM{M_{SUM}}MSUM的准确率VSUM{V_{SUM}}VSUM,定义δδδ为非负实数,如果∣VFED−VSUM∣<δ{|V_{FED}-V_{SUM}| < δ}∣VFED−VSUM∣<δ,那么我们可以认为联邦学习算法具有δδδ精度损失。
3、联邦学习的隐私保护机制
\qquad隐私是联邦学习的基本属性之一,需要安全模型和分析,提供有意义的隐私保证。下面介绍几种不同的隐私技术方法以及潜在的挑战。
(1) 安全多方计算(Secure Multi-party Computation)。安全模型涉及多个参与主体,每个主体需要提供仿真平台的安全证明,确保各主体除了输入和输出外无法获取额外信息。但是理想模型需要复杂的计算框架,并且实现的有效性有限。在某些场景,可以考虑部分知识披露,接受有安全保证的数据披露。
(2) 差分隐私(Differential Privacy)。将差分隐私技术或者匿名技术用于数据隐私保护。差分隐私通过在数据中添加噪声或使用泛化方法掩盖某些敏感属性,使得第三方无法区分主体。但是具体的实现仍然要求将数据传输到其他地方,涉及到数据真实性和隐私性问题。
(3) 同态加密(Homomorphic Encryption)。通过机器学习在加密机制下的参数交换实现隐私保护,数据和模型本身不会传输。
4、联邦学习分类
\qquad令矩阵DiD_iDi表示第iii个数据拥有者的信息,每一行代表一个样本,每一列代表一个特征,某些数据集要求包含数据标签列。使用XXX表示特征空间,YYY表示标签取值范围,III表示样本的ID空间,X,Y,IX,Y,IX,Y,I共同构成了完整的训练数据集。根据特征和样本空间的而不同,将联邦学习分为水平联邦学习、垂直联邦学习和联邦迁移学习。
4.1 水平/横向联邦学习(Horizontal Federated Learning)
\qquad水平/横向联邦学习是基于用户的联邦学习,在数据集的特征空间重合较多但用户重合较少的情况下,取双方用户特征完全相同而用户不完全相同的数据集进行训练,并在保证参与者数据隐私的前提下训练出公开的通用模型和参数。例如,不同地区银行的用户群体不同,但是业务非常相似,因此特征空间存在较大重合。水平联邦学习可以总结为:
Xi=Xj,Yi=Yj,Ii≠Ij,∀Di,Dj,i≠jX_i=X_j,Y_i=Y_j,I_i≠I_j,∀ D_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,∀Di,Dj,i=j
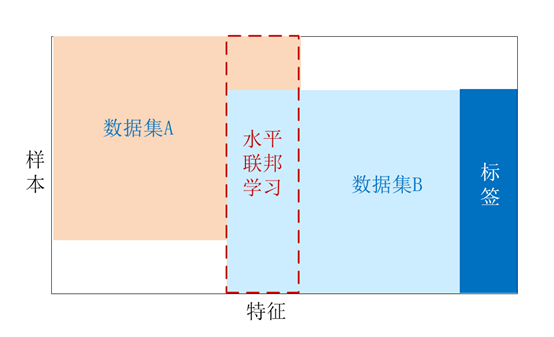 4.2 垂直/纵向联邦学习(Vertical Federated Learning)
\qquad垂直联邦学习是基于特征的联邦学习,适用于两个数据集用户重合较大但特征空间重合较少的情况,这时候需要取双方用户相同而用户特征不完全相同的数据集进行训练,在加密机制的保护下训练出损失函数和梯度并进行聚合。例如,同一地区的银行和电子商务公司,它们的用户群体大多数是该地区的居民,但银行重点记录用户收入和支出、电商重点记录用户网购记录,特征空间存在较大区别。垂直联邦学习可以总结为:
Xi≠Xj,Yi≠Yj,Ii=Ij,∀Di,Dj,i≠jX_i≠X_j,Y_i≠Y_j,I_i=I_j,∀ D_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,∀Di,Dj,i=j
4.2 垂直/纵向联邦学习(Vertical Federated Learning)
\qquad垂直联邦学习是基于特征的联邦学习,适用于两个数据集用户重合较大但特征空间重合较少的情况,这时候需要取双方用户相同而用户特征不完全相同的数据集进行训练,在加密机制的保护下训练出损失函数和梯度并进行聚合。例如,同一地区的银行和电子商务公司,它们的用户群体大多数是该地区的居民,但银行重点记录用户收入和支出、电商重点记录用户网购记录,特征空间存在较大区别。垂直联邦学习可以总结为:
Xi≠Xj,Yi≠Yj,Ii=Ij,∀Di,Dj,i≠jX_i≠X_j,Y_i≠Y_j,I_i=I_j,∀ D_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,∀Di,Dj,i=j
 4.3 联邦迁移学习( Federated Transfer Learning)
\qquad联邦迁移学习针对的是数据集的用户和特征均重叠较少的情况,这时可以采用迁移学习技术提供联合整个样本和特征空间的解决方案。例如,位于中国和美国的电子商务公司,一方面由于地理位置的不同,两个机构的用户群体交叉很少;另一方面由于业务范围的不同,特征空间只有小部分的重叠。联邦迁移学习可以总结为:
Xi≠Xj,Yi≠Yj,Ii≠Ij,〖∀D〗i,Dj,i≠jX_i≠X_j,Y_i≠Y_j,I_i≠I_j,〖∀ D〗_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,〖∀D〗i,Dj,i=j
4.3 联邦迁移学习( Federated Transfer Learning)
\qquad联邦迁移学习针对的是数据集的用户和特征均重叠较少的情况,这时可以采用迁移学习技术提供联合整个样本和特征空间的解决方案。例如,位于中国和美国的电子商务公司,一方面由于地理位置的不同,两个机构的用户群体交叉很少;另一方面由于业务范围的不同,特征空间只有小部分的重叠。联邦迁移学习可以总结为:
Xi≠Xj,Yi≠Yj,Ii≠Ij,〖∀D〗i,Dj,i≠jX_i≠X_j,Y_i≠Y_j,I_i≠I_j,〖∀ D〗_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,〖∀D〗i,Dj,i=j
 5、联邦学习系统架构
\qquad本节我们将说明联邦学习系统的通用体系结构的示例。 水平和垂直联合学习系统的体系结构之间存在很大差异设计,我们将分别介绍它们。
5.1 水平联邦学习系统架构
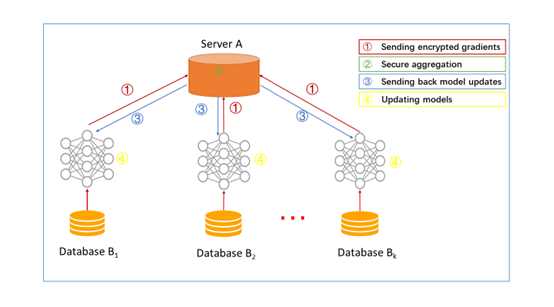
\qquadk个参与者拥有相同的数据结构,在云服务器上学习机器学习模型。在诚实(honest)的参与者和诚实且好奇(honest-but-curious)的服务器的前提假设下,保证了参与者的数据不被泄露。系统的训练过程通常包含以下步骤:
\qquadStep 1:参与者使用加密、差分隐私和加密共享技术,在本利训练模型梯度和参数并传给中间服务器;
\qquadStep 2:服务器在不了解任何参与者信息的情况下执行安全聚合;
\qquadStep 3:服务器将汇总结果回传各参与者;
\qquadStep 4:各参与者使用解密后的梯度更新各自模型。
\qquad继续执行上述步骤,直到损失函数收敛,完成了整个训练过程。
5、联邦学习系统架构
\qquad本节我们将说明联邦学习系统的通用体系结构的示例。 水平和垂直联合学习系统的体系结构之间存在很大差异设计,我们将分别介绍它们。
5.1 水平联邦学习系统架构
\qquadk个参与者拥有相同的数据结构,在云服务器上学习机器学习模型。在诚实(honest)的参与者和诚实且好奇(honest-but-curious)的服务器的前提假设下,保证了参与者的数据不被泄露。系统的训练过程通常包含以下步骤:
\qquadStep 1:参与者使用加密、差分隐私和加密共享技术,在本利训练模型梯度和参数并传给中间服务器;
\qquadStep 2:服务器在不了解任何参与者信息的情况下执行安全聚合;
\qquadStep 3:服务器将汇总结果回传各参与者;
\qquadStep 4:各参与者使用解密后的梯度更新各自模型。
\qquad继续执行上述步骤,直到损失函数收敛,完成了整个训练过程。
 5.2 垂直联邦学习系统架构
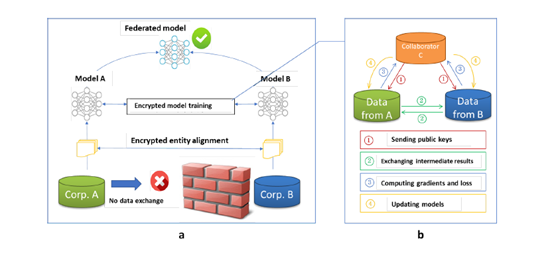
\qquad各参与者希望基于各自数据联合训练机器学习模型,不直接交换数据,这就需要利益无关且受信任的第三方介入。垂直联邦系统由两部分组成。
\qquad第一部分:加密样本对齐。由于参与者的用户群体不同,系统使用基于加密的用户ID对齐技术,确定双方的共同用户。在对齐时,各参与方不公开各自数据,系统也不会暴露彼此不重叠的用户。
\qquad第二部分:加密模型训练。确定共同用户后,使用这些共同用户的样本数据来训练机器学习模型,具体步骤如下:
\qquadStep 1:协作者创建加密对齐样本的公钥并发送给A和B,用于对参与模型训练的共同数据进行加密;
\qquadStep 2:A和B加密并交互计算的梯度和损失函数的中间参数;
\qquadStep 3:A和B基于加密的中间参数计算梯度值,B还需要额外根据标签计算损失函数,将加密结果发送给C;
\qquadStep 4:C将解密后的梯度和损失函数回传给A和B,A和B根据梯度更新模型参数。
5.2 垂直联邦学习系统架构
\qquad各参与者希望基于各自数据联合训练机器学习模型,不直接交换数据,这就需要利益无关且受信任的第三方介入。垂直联邦系统由两部分组成。
\qquad第一部分:加密样本对齐。由于参与者的用户群体不同,系统使用基于加密的用户ID对齐技术,确定双方的共同用户。在对齐时,各参与方不公开各自数据,系统也不会暴露彼此不重叠的用户。
\qquad第二部分:加密模型训练。确定共同用户后,使用这些共同用户的样本数据来训练机器学习模型,具体步骤如下:
\qquadStep 1:协作者创建加密对齐样本的公钥并发送给A和B,用于对参与模型训练的共同数据进行加密;
\qquadStep 2:A和B加密并交互计算的梯度和损失函数的中间参数;
\qquadStep 3:A和B基于加密的中间参数计算梯度值,B还需要额外根据标签计算损失函数,将加密结果发送给C;
\qquadStep 4:C将解密后的梯度和损失函数回传给A和B,A和B根据梯度更新模型参数。
 5.3 联邦迁移学习系统架构
\qquad联邦迁移学习的总体架构类似于垂直联邦学习的总体架构,不同的是改变部分交互的中间结果。具体地,迁移学习需要学习出A和B共同的代表性特征,并且最小化B标签预测的错误率。因此联邦迁移学习得到的A和B的梯度值不同,并且都需要计算预测结果。
5.4 联邦学习激励机制
\qquad为了在不同组织之间联邦学习的商业化应用,需要建立一个公平的平台和激励机制。模型建成后,其性能将在实际应用中得到体现,并且记录在永久数据记录机制(例如区块链)中。模型的性能取决于对系统的数据贡献,分配给联合机制各参与方,激励更多用户加入联合机制。上述联邦学习的架构不仅考虑了隐私保护和多个参与方协作建模的有效性,还考虑到实施一致性的激励机制来奖励贡献更多数据的组织。因此,联邦学习是一种“闭环(closed-loop)”学习机制,通过利用带标签的数据参与方的标签,最大程度减少预测错误率。
6、联邦学习的应用
\qquad目前,联邦学习在应用中存在两个问题:
\qquad 1、银行、社交网站、电商平台之间的数据孤岛很难被打破;
\qquad 2、数据存储的异构性,传统的机器学习无法直接处理异质数据。
\qquad联邦学习和迁移学习能很好的解决这些问题。首先,利用联邦学习的特点,在无需数据共享的情况下为各方建立一个机器学习模型,不仅保护了数据的隐私性和安全性,还为客户提供了有针对性的个性化服务,实现互惠互利。同时,利用迁移学习来解决数据异质的问题。因此联邦学习可以为我们建立起跨企业、跨数据的大数据和人工智能的跨域生态圈。也可以使用联邦学习框架进行多方数据库查询而不暴露数据。例如,某些用户恶意从一家银行A借款以支付另一家银行B的贷款,可以再银行A和银行B之间利用联邦学习框架,利用加密机制加密各方的用户列表,获得各方加密列表的交集,并将多方共同借款人列表解密发送给银行。智慧医疗是另一个受益于联邦学习的领域。在医疗领域,疾病症状、基因序列、医学报告非常敏感和隐私,而且存在于独立的医院和医疗中心是,收集难度较大。数据源不足和标签缺失导致机器学习模型的性能不尽人意,这成了当前智慧医疗的瓶颈。如果所有医疗机构团结起来共享数据,形成大型医疗数据集,可进一步改善训练模型的性能,在智慧医疗领域发挥关键作用。
作者:有梦想的咸鱼~
5.3 联邦迁移学习系统架构
\qquad联邦迁移学习的总体架构类似于垂直联邦学习的总体架构,不同的是改变部分交互的中间结果。具体地,迁移学习需要学习出A和B共同的代表性特征,并且最小化B标签预测的错误率。因此联邦迁移学习得到的A和B的梯度值不同,并且都需要计算预测结果。
5.4 联邦学习激励机制
\qquad为了在不同组织之间联邦学习的商业化应用,需要建立一个公平的平台和激励机制。模型建成后,其性能将在实际应用中得到体现,并且记录在永久数据记录机制(例如区块链)中。模型的性能取决于对系统的数据贡献,分配给联合机制各参与方,激励更多用户加入联合机制。上述联邦学习的架构不仅考虑了隐私保护和多个参与方协作建模的有效性,还考虑到实施一致性的激励机制来奖励贡献更多数据的组织。因此,联邦学习是一种“闭环(closed-loop)”学习机制,通过利用带标签的数据参与方的标签,最大程度减少预测错误率。
6、联邦学习的应用
\qquad目前,联邦学习在应用中存在两个问题:
\qquad 1、银行、社交网站、电商平台之间的数据孤岛很难被打破;
\qquad 2、数据存储的异构性,传统的机器学习无法直接处理异质数据。
\qquad联邦学习和迁移学习能很好的解决这些问题。首先,利用联邦学习的特点,在无需数据共享的情况下为各方建立一个机器学习模型,不仅保护了数据的隐私性和安全性,还为客户提供了有针对性的个性化服务,实现互惠互利。同时,利用迁移学习来解决数据异质的问题。因此联邦学习可以为我们建立起跨企业、跨数据的大数据和人工智能的跨域生态圈。也可以使用联邦学习框架进行多方数据库查询而不暴露数据。例如,某些用户恶意从一家银行A借款以支付另一家银行B的贷款,可以再银行A和银行B之间利用联邦学习框架,利用加密机制加密各方的用户列表,获得各方加密列表的交集,并将多方共同借款人列表解密发送给银行。智慧医疗是另一个受益于联邦学习的领域。在医疗领域,疾病症状、基因序列、医学报告非常敏感和隐私,而且存在于独立的医院和医疗中心是,收集难度较大。数据源不足和标签缺失导致机器学习模型的性能不尽人意,这成了当前智慧医疗的瓶颈。如果所有医疗机构团结起来共享数据,形成大型医疗数据集,可进一步改善训练模型的性能,在智慧医疗领域发挥关键作用。
作者:有梦想的咸鱼~
4.2 垂直/纵向联邦学习(Vertical Federated Learning)
\qquad垂直联邦学习是基于特征的联邦学习,适用于两个数据集用户重合较大但特征空间重合较少的情况,这时候需要取双方用户相同而用户特征不完全相同的数据集进行训练,在加密机制的保护下训练出损失函数和梯度并进行聚合。例如,同一地区的银行和电子商务公司,它们的用户群体大多数是该地区的居民,但银行重点记录用户收入和支出、电商重点记录用户网购记录,特征空间存在较大区别。垂直联邦学习可以总结为:
Xi≠Xj,Yi≠Yj,Ii=Ij,∀Di,Dj,i≠jX_i≠X_j,Y_i≠Y_j,I_i=I_j,∀ D_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,∀Di,Dj,i=j
4.3 联邦迁移学习( Federated Transfer Learning)
\qquad联邦迁移学习针对的是数据集的用户和特征均重叠较少的情况,这时可以采用迁移学习技术提供联合整个样本和特征空间的解决方案。例如,位于中国和美国的电子商务公司,一方面由于地理位置的不同,两个机构的用户群体交叉很少;另一方面由于业务范围的不同,特征空间只有小部分的重叠。联邦迁移学习可以总结为:
Xi≠Xj,Yi≠Yj,Ii≠Ij,〖∀D〗i,Dj,i≠jX_i≠X_j,Y_i≠Y_j,I_i≠I_j,〖∀ D〗_i,D_j,i≠jXi=Xj,Yi=Yj,Ii=Ij,〖∀D〗i,Dj,i=j
5、联邦学习系统架构
\qquad本节我们将说明联邦学习系统的通用体系结构的示例。 水平和垂直联合学习系统的体系结构之间存在很大差异设计,我们将分别介绍它们。
5.1 水平联邦学习系统架构
\qquadk个参与者拥有相同的数据结构,在云服务器上学习机器学习模型。在诚实(honest)的参与者和诚实且好奇(honest-but-curious)的服务器的前提假设下,保证了参与者的数据不被泄露。系统的训练过程通常包含以下步骤:
\qquadStep 1:参与者使用加密、差分隐私和加密共享技术,在本利训练模型梯度和参数并传给中间服务器;
\qquadStep 2:服务器在不了解任何参与者信息的情况下执行安全聚合;
\qquadStep 3:服务器将汇总结果回传各参与者;
\qquadStep 4:各参与者使用解密后的梯度更新各自模型。
\qquad继续执行上述步骤,直到损失函数收敛,完成了整个训练过程。
5.2 垂直联邦学习系统架构
\qquad各参与者希望基于各自数据联合训练机器学习模型,不直接交换数据,这就需要利益无关且受信任的第三方介入。垂直联邦系统由两部分组成。
\qquad第一部分:加密样本对齐。由于参与者的用户群体不同,系统使用基于加密的用户ID对齐技术,确定双方的共同用户。在对齐时,各参与方不公开各自数据,系统也不会暴露彼此不重叠的用户。
\qquad第二部分:加密模型训练。确定共同用户后,使用这些共同用户的样本数据来训练机器学习模型,具体步骤如下:
\qquadStep 1:协作者创建加密对齐样本的公钥并发送给A和B,用于对参与模型训练的共同数据进行加密;
\qquadStep 2:A和B加密并交互计算的梯度和损失函数的中间参数;
\qquadStep 3:A和B基于加密的中间参数计算梯度值,B还需要额外根据标签计算损失函数,将加密结果发送给C;
\qquadStep 4:C将解密后的梯度和损失函数回传给A和B,A和B根据梯度更新模型参数。
5.3 联邦迁移学习系统架构
\qquad联邦迁移学习的总体架构类似于垂直联邦学习的总体架构,不同的是改变部分交互的中间结果。具体地,迁移学习需要学习出A和B共同的代表性特征,并且最小化B标签预测的错误率。因此联邦迁移学习得到的A和B的梯度值不同,并且都需要计算预测结果。
5.4 联邦学习激励机制
\qquad为了在不同组织之间联邦学习的商业化应用,需要建立一个公平的平台和激励机制。模型建成后,其性能将在实际应用中得到体现,并且记录在永久数据记录机制(例如区块链)中。模型的性能取决于对系统的数据贡献,分配给联合机制各参与方,激励更多用户加入联合机制。上述联邦学习的架构不仅考虑了隐私保护和多个参与方协作建模的有效性,还考虑到实施一致性的激励机制来奖励贡献更多数据的组织。因此,联邦学习是一种“闭环(closed-loop)”学习机制,通过利用带标签的数据参与方的标签,最大程度减少预测错误率。
6、联邦学习的应用
\qquad目前,联邦学习在应用中存在两个问题:
\qquad 1、银行、社交网站、电商平台之间的数据孤岛很难被打破;
\qquad 2、数据存储的异构性,传统的机器学习无法直接处理异质数据。
\qquad联邦学习和迁移学习能很好的解决这些问题。首先,利用联邦学习的特点,在无需数据共享的情况下为各方建立一个机器学习模型,不仅保护了数据的隐私性和安全性,还为客户提供了有针对性的个性化服务,实现互惠互利。同时,利用迁移学习来解决数据异质的问题。因此联邦学习可以为我们建立起跨企业、跨数据的大数据和人工智能的跨域生态圈。也可以使用联邦学习框架进行多方数据库查询而不暴露数据。例如,某些用户恶意从一家银行A借款以支付另一家银行B的贷款,可以再银行A和银行B之间利用联邦学习框架,利用加密机制加密各方的用户列表,获得各方加密列表的交集,并将多方共同借款人列表解密发送给银行。智慧医疗是另一个受益于联邦学习的领域。在医疗领域,疾病症状、基因序列、医学报告非常敏感和隐私,而且存在于独立的医院和医疗中心是,收集难度较大。数据源不足和标签缺失导致机器学习模型的性能不尽人意,这成了当前智慧医疗的瓶颈。如果所有医疗机构团结起来共享数据,形成大型医疗数据集,可进一步改善训练模型的性能,在智慧医疗领域发挥关键作用。
作者:有梦想的咸鱼~