JVM内存模型及垃圾回收
通俗的来讲,jvm主要分为5个部分 程序计数器、虚拟机枝、本地方法枝、 Java 堆、 方法区, 引用大佬总结的概括程序计数器用于存放下一条运行的指令,虚拟机栈和本地方法栈用于存放函数调用堆栈信息, Java 堆用于存放 Java 程序运行时所需的对象等数据,方法区用于存放程序的类元数据信息 。
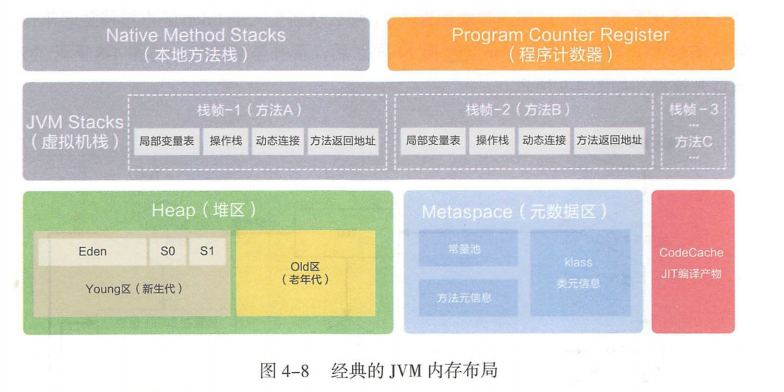
程序计数器: 是一块很小的内存空间,每个线程私有,可以看作当前线程程序执行的字节码的行号提示器。
栈: 线程私有存储空间,访问速度仅次于寄存器,栈里面的存储单位为,栈帧, 栈帧对应着方法, 存放着方法的 局部变量表,操作数栈,常量池引用,方法返回地址。
本地方法栈:用于管理本地方法的调用,本地方法一般都是由C语言编写,调用本地方法,都会使用本地方法栈, 而不是像 自己定义的方法那样在虚拟机的栈中创建栈帧,而是java栈动态连接到本地方法栈。
方法区: 线程之间共享的,储存类的类型信息,常量池,方法信息,JIT编译后的代码等数据等, jdk1.7后 对方法区,的位置都由改变, jdk 1.7以前, 常量池在永久代中, 从1.7 以后就搬入到堆中, 方便对其进行垃圾回收, jdk1.8以后永久代就被元空间取代;
堆: 所有线程之间共享的,首先是默认分为 新生代和老年代,默认占比是1:2,新生代有分为eden区和survivor(分为 from 和to) 默认比例为 8:1;
垃圾回收算法垃圾标记算法有,引用计数法,和根搜索算法(可达性分析)等,常见的垃圾收集算法有 标记-清除算法( Mark-Sweep ),复制算法(Copying ),标记-整理算法(Mark-Compact )
引用计数法引用计数法( Reference Counting)在 GC 执行垃圾回收之前,首先需要区分出内存中哪些
是存活对象,哪些是已经死亡的对象。只有被标记为己经死亡的对象, GC 才会在执行垃圾回
收时,释放掉其所占用的内存空间 , 因此这个过程我们可以称为垃圾标记阶段。
对于对象A来说,只要有任意一个对象引用了A,A的引用计数器就加1, 当引用失效时,计数器就减一,当对象A的计数器的值为0时,就可以被回收, 但是有个明显的问题,当存在对象A,对象B,它们之间互相引用,导致引用计数都不为0,就不能被删除掉。
根搜索算法以根对象集合为起始点,按照从上至下的方式搜索被根对象集合所连接的目标对象是否可达(使用根搜索算法后,内存中
的存活对象都会被根对象集合直接或间接连接着),如果目标对象不可达,就意味着该对象己经死亡,便可以将其标记为垃圾对象。在根搜索算法中,只有能够被根对象集合直接或者间接连接的对象才是存活对象, 当对象被标记为不可达,并不意味着会被马上清除掉,一个对象的死亡,至少要经历两次标记过程。 第一次是执行对象的finalize()将对象放入F-Queue 中, 之后再进行一次判断,才会被清除掉
当对象放入F-queue时候,只要将对象,与任何引用关联上,就可以使对象重新存活,
public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, i am still alive");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize mehtod executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
public static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinalizeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
// 因为Finalizer方法优先级很低,暂停0.5秒,以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead");
}
// 下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
// 因为Finalizer方法优先级很低,暂停0.5秒,以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead");
}
}
}
(对象的finalize方法只会被执行一次,第二次对象就没有被放入到F-queue 直接被回收了)执行的结果为:
finalize mehtod executed!
yes, i am still alive
no, i am dead
标记-清除算法
算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。

复制算法
它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。

标记-整理算法
标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动整理压缩,然后直接清理掉端边界以外的内存。


增量算法
垃圾回收的过程都需要暂停应用程序,如果垃圾回收暂停了很长时间,就会影响用户的体验,因此增量算法的思想,就是用多线程的方式,一边进行标记-清除,复制,清理垃圾, 一边执行应用程序, 这样就减少了系统的停顿时间;
分代收集算法
将堆细分为年轻代,和老年代,根据不同代中对象的使用情况不用, 分别使用不同垃圾收集器, 年轻代中,对象大多数属于朝生夕死的,使用效率较高的复制算法, 老年代对象大多是都是经历过多次垃圾回收幸存的对象, 在加上老年代回收性价要比年轻代低,使用标记整理算法。(看到分代收集器,是不是突然明白了,为啥jvm的堆,要分为年轻代,老年代,年轻代 有为啥有两个survivor区 )
博客笔记,参考了 《深入理解JVM & G1 GC》和 《深入理解Java虚拟机_JVM高级特性与最佳实践》 安利一下
作者:记录每一份笔记