Flink 1.10 Native Kubernetes 原理与实践
千呼万唤始出来,在 Kubernetes 如火如荼的今天,Flink 社区终于在 1.10 版本提供了对 Kubernetes 的原生支持,也就是 Native Kubernetes Integration[1]。不过还只是 Beta 版本,预计会在 1.11 版本里面提供完整的支持。
我们知道,在 Flink 1.9 以及之前的版本里面,如果要在 Kubernetes 上运行 Flink 任务是需要事先指定好需要的 TaskManager(TM) 的个数以及 CPU 和内存的。这样的问题是:大多数情况下,你在任务启动前根本无法精确的预估这个任务需要多少个 TM。如果指定的 TM 多了,会导致资源浪费;如果指定的 TM 个数少了,会导致任务调度不起来。本质原因是在 Kubernetes 上运行的 Flink 任务并没有直接向 Kubernetes 集群去申请资源。
Flink 在 1.10 版本完成了 Active Kubernetes Integration 的第一阶段,支持了 session clusters。后续的第二阶段会提供更完整的支持,如支持 per-job 任务提交,以及基于原生 Kubernetes API 的高可用,支持更多的 Kubernetes 参数如 toleration, label 和 node selector 等。Active Kubernetes Integration中的Active意味着 Flink 的 ResourceManager (KubernetesResourceManager) 可以直接和 Kubernetes 通信,按需申请新的 Pod,类似于 Flink 中对 Yarn 和 Mesos 的集成所做的那样。在多租户环境中,用户可以利用 Kubernetes 里面的 namespace 做资源隔离启动不同的 Flink 集群。当然,Kubernetes 中的用户帐号和赋权是需要提前准备好的。
原 理
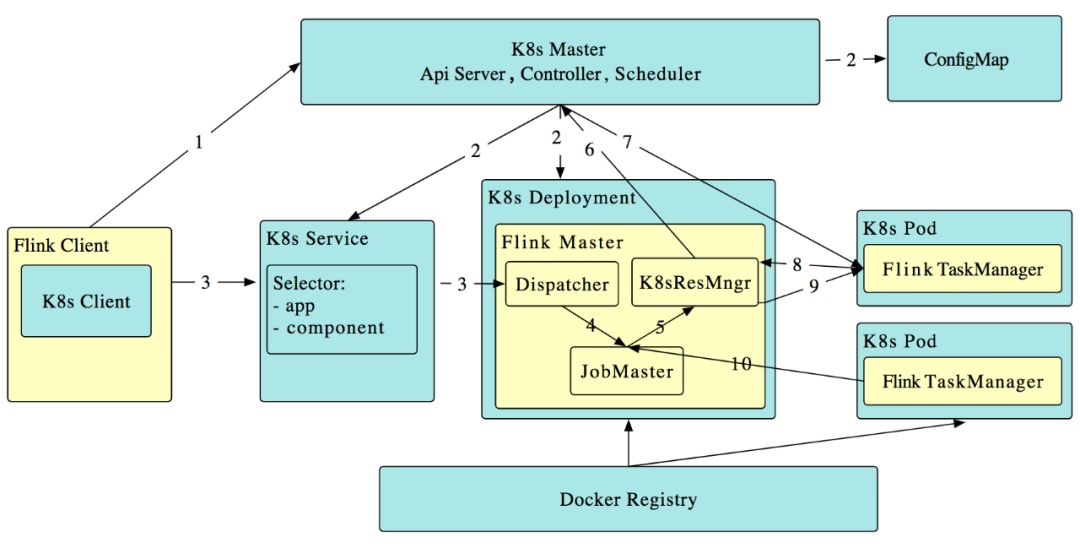
Flink 1.10 native k8s
工作原理如下(段首的序号对应图中箭头所示的数字):
Flink 客户端首先连接 Kubernetes API Server,提交 Flink 集群的资源描述文件,包括 configmap,job manager service,job manager deployment 和 Owner Reference[2]。
Kubernetes Master 就会根据这些资源描述文件去创建对应的 Kubernetes 实体。以我们最关心的 job manager deployment 为例,Kubernetes 集群中的某个节点收到请求后,Kubelet 进程会从中央仓库下载 Flink 镜像,准备和挂载 volume,然后执行启动命令。在 flink master 的 pod 启动后,Dispacher 和 KubernetesResourceManager 也都启动了。
前面两步完成后,整个 Flink session cluster 就启动好了,可以接受提交任务请求了。
用户可以通过 flink 命令行即 flink client 往这个 session cluster 提交任务。此时 job graph 会在 flink client 端生成,然后和用户 jar 包一起通过 RestClinet 上传。
一旦 job 提交成功,JobSubmitHandler 收到请求就会提交 job 给 Dispatcher。接着就会生成一个 job master。
JobMaster 向 KubernetesResourceManager 请求 slots。
KubernetesResourceManager 从 Kubernetes 集群分配 TaskManager。每个 TaskManager 都是具有唯一标识的 Pod。KubernetesResourceManager 会为 TaskManager 生成一份新的配置文件,里面有 Flink Master 的 service name 作为地址。这样在 Flink Master failover之后,TaskManager 仍然可以重新连上。
Kubernetes 集群分配一个新的 Pod 后,在上面启动 TaskManager。
TaskManager 启动后注册到 SlotManager。
SlotManager 向 TaskManager 请求 slots。
TaskManager 提供 slots 给 JobMaster。然后任务就会被分配到这个 slots 上运行。
实 践
Flink 的文档[3]上对如何使用已经写的比较详细了,不过刚开始总会踩到一些坑。如果对 Kubernetes 不熟,可能会花点时间。
(1) 首先得有个 Kubernetes 集群,会有个 ~/.kube/config 文件。尝试执行 kubectl get nodes 看下集群是否正常。
如果没有这个 ~/.kube/config 文件,会报错:
2020-02-17 22:27:17,253 WARN io.fabric8.kubernetes.client.Config - Error reading service account token from: [/var/run/secrets/kubernetes.io/serviceaccount/token]. Ignoring. 2020-02-17 22:27:17,437 ERROR org.apache.flink.kubernetes.cli.KubernetesSessionCli - Error while running the Flink session. io.fabric8.kubernetes.client.KubernetesClientException: Operation: [get] for kind: [Service] with name: [flink-cluster-81832d75-662e-40fd-8564-cd5a902b243c] in namespace: [default] failed. at io.fabric8.kubernetes.client.KubernetesClientException.launderThrowable(KubernetesClientException.java:64) at io.fabric8.kubernetes.client.KubernetesClientException.launderThrowable(KubernetesClientException.java:72) at io.fabric8.kubernetes.client.dsl.base.BaseOperation.getMandatory(BaseOperation.java:231) at io.fabric8.kubernetes.client.dsl.base.BaseOperation.get(BaseOperation.java:164) at org.apache.flink.kubernetes.kubeclient.Fabric8FlinkKubeClient.getService(Fabric8FlinkKubeClient.java:334) at org.apache.flink.kubernetes.kubeclient.Fabric8FlinkKubeClient.getInternalService(Fabric8FlinkKubeClient.java:246) at org.apache.flink.kubernetes.cli.KubernetesSessionCli.run(KubernetesSessionCli.java:104) at org.apache.flink.kubernetes.cli.KubernetesSessionCli.lambda$main$0(KubernetesSessionCli.java:185) at org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30) at org.apache.flink.kubernetes.cli.KubernetesSessionCli.main(KubernetesSessionCli.java:185) Caused by: java.net.UnknownHostException: kubernetes.default.svc: nodename nor servname provided, or not known(2) 提前创建好用户和赋权(RBAC[4])
kubectl create serviceaccount flink kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:flink如果没有创建用户,使用默认的用户去提交,会报错:
Caused by: io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: GET at: https://10.10.0.1/api/v1/namespaces/default/pods?labelSelector=app%3Dkaibo-test%2Ccomponent%3Dtaskmanager%2Ctype%3Dflink-native-kubernetes. Message: Forbidden!Configured service account doesn't have access. Service account may have been revoked. pods is forbidden: User "system:serviceaccount:default:default" cannot list resource "pods" in API group "" in the namespace "default".(3) 这一步是可选的。默认情况下, JobManager 和 TaskManager 只会将 log 写到各自 pod 的 /opt/flink/log 。如果想通过 kubectl logs 看到日志,需要将 log 输出到控制台。要做如下修改 FLINK_HOME/conf 目录下的 log4j.properties 文件。
log4j.rootLogger=INFO, file, console # Log all infos to the console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n然后启动 session cluster 的命令行需要带上参数:
-Dkubernetes.container-start-command-template="%java% %classpath% %jvmmem% %jvmopts% %logging% %class% %args%"(4) 终于可以开始启动 session cluster了。如下命令是启动一个每个 TaskManager 是4G内存,2个CPU,4个slot 的 session cluster。
bin/kubernetes-session.sh -Dkubernetes.container-start-command-template="%java% %classpath% %jvmmem% %jvmopts% %logging% %class% %args%" -Dkubernetes.cluster-id=kaibo-test -Dtaskmanager.memory.process.size=4096m -Dkubernetes.taskmanager.cpu=2 -Dtaskmanager.numberOfTaskSlots=4更多的参数详见文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/config.html#kubernetes
使用 kubectl logs kaibo-test-6f7dffcbcf-c2p7g -f 就能看到日志了。
如果出现大量的如下这种日志(目前遇到是云厂商的LoadBalance liveness探测导致):
2020-02-17 14:58:56,323 WARN org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Unhandled exception java.io.IOException: Connection reset by peer at sun.nio.ch.FileDispatcherImpl.read0(Native Method) at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39) at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223) at sun.nio.ch.IOUtil.read(IOUtil.java:192) at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:377) at org.apache.flink.shaded.netty4.io.netty.buffer.PooledByteBuf.setBytes(PooledByteBuf.java:247)可以暂时在 log4j.properties 里面配置上:
log4j.logger.org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint=ERROR, file这个日志太多会导致 WebUI 上打开 jobmanger log 是空白,因为文件太大了前端无法显示。
如果前面第(1)和第(2)步没有做,会出现各种异常,通过 kubectl logs 就能很方便的看到日志了。
Session cluster 启动后可以通过 kubectl get pods,svc 来看是否正常。
通过端口转发来查看 Web UI:
kubectl port-forward service/kaibo-test 8081打开 http://127.0.0.1:8001 就能看到 Flink 的 WebUI 了。
(5) 提交任务
./bin/flink run -d -e kubernetes-session -Dkubernetes.cluster-id=k test.jar我们从 Flink WebUI 页面上可以看到,刚开始启动时,UI上显示 Total/Available Task Slots 为0, Task Managers 也是0。随着任务的提交,资源会动态增加。任务停止后,资源会释放掉。
在提交任务后,通过 kubectl get pods 能够看到 Flink 为 TaskManager 分配了新的 Pod。
pods
(6) 停止 session cluster
echo 'stop' | ./bin/kubernetes-session.sh -Dkubernetes.cluster-id=kaibo-test -Dexecution.attached=true也可以手工删除资源:
kubectl delete service/总 结
可以看到,Flink 1.10 版本对和 Kubernetes 的集成做了很好的尝试。期待社区后续的 1.11 版本能对 per-job 提供支持,以及和 Kubernetes 的深度集成,例如基于原生 Kubernetes API 的高可用。最新进展请关注 FLINK-14460[5]。
参考链接:
[1] https://flink.apache.org/news/2020/02/11/release-1.10.0.html#native-kubernetes-integration-beta
[2] https://kubernetes.io/docs/concepts/workloads/controllers/garbage-collection/
[3] https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/deployment/native_kubernetes.html
[4] https://kubernetes.io/docs/reference/access-authn-authz/rbac/
[5] https://issues.apache.org/jira/browse/FLINK-14460
Tips:点击「阅读原文」可查看作者原版博客~
作者介绍:
周凯波(宝牛),阿里巴巴技术专家,四川大学硕士,2010 年毕业后加入阿里搜索事业部,从事搜索离线平台的研发工作,参与将搜索后台数据处理架构从 MapReduce 到 Flink 的重构。目前在阿里计算平台事业部,专注于基于 Flink 的一站式计算平台的建设。
关注 Flink 中文社区,获取更多技术干货
你也「在看」吗?????
作者:Ververica

