计算框架相关的编译器知识(XLA)
Tensorflow XLA的加速原理主要是融合Kernel
def model_fn(x,y,z):
return tf.reduce_sum(x + y * z)
如果运行模型时不使用 XLA,图表会启动三个内核,分别用于乘法、加法和减法。
官网原话:XLA 可以优化计算图,将加法、乘法和减法 “融合” 到单个 GPU Kernel中。此外,这种融合运算不会将 y*z 和 x+y*z 生成的中间值写入内存,而是将这些中间计算的结果直接 “流式传输” 给用户,并完整保存在 GPU 寄存器中。融合是 XLA 最重要的一种优化方式。内存带宽通常是硬件加速器上最稀缺的资源,因此删除内存运算是提升性能的最佳方法之一。
我的理解:计算融合到一个Kernel,减少Kernel启动次数,减少中间结果来回读写显存次数;
Tensorflow使用XLA比不使用,在大部分模型下,能有10%~50%左右的加速提升;可以用户自己指定哪些操作做XLA编译优化,也可以让系统自动去找可优化的地方自动进行XLA优化;
AOT方式和JIT方式
两种方式下都会将整个计算图或则计算图的一部分直接编译成可执行代码。两则的区别也是比较明显的,除了编译时机不一样(AOT计算图在不会在运行阶段前被编译成可执行代码,JIT是在进入运行阶段后的适当的时机才会被编译成可执行代码),还有就是runtime(运行时)的参与程度。AOT中彻底不需要运行时的参与了,而JIT中还是需要运行时参与的,但是JIT会优化融合原计算图中的节点,加入XlaLaunch节点,来加速计算图的执行。
经典LLVM编译器架构:(扩展性支持好,即插即用的前端和后端)
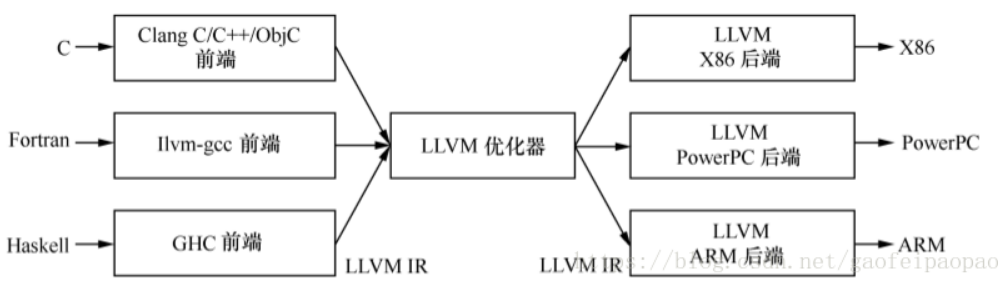
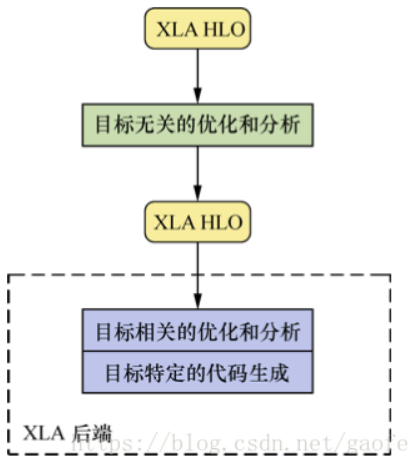
Tensorflow的XLA架构(类似LLVM):
作者:smartcat2010