Kettle将数据导入导Hive2
前言
本来将数据导入到hive,但是不知道什么原因太慢了,一小时200条数据,优化一波kettle,还是成效不大,因此改为借用hadoop file output 到hdfs,然后再load 到hive表里
一,正文1.在转换里拖入big data/hadoop file output
新建hadoop cluster连接
从集群里下载core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml
覆盖kettle的plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26中的4个同名文件。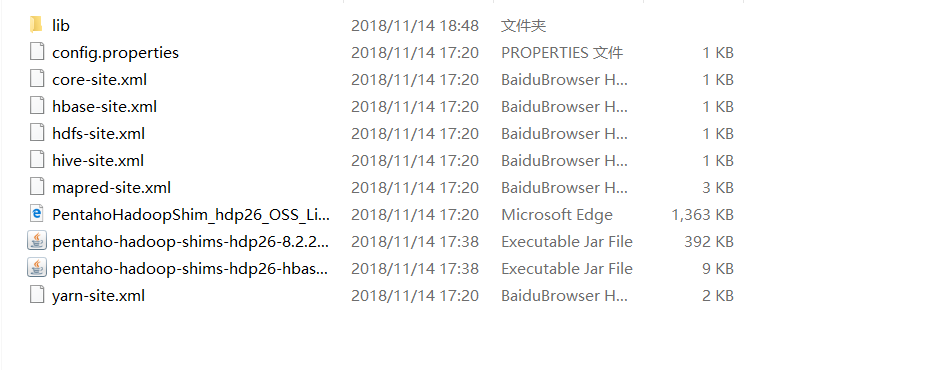
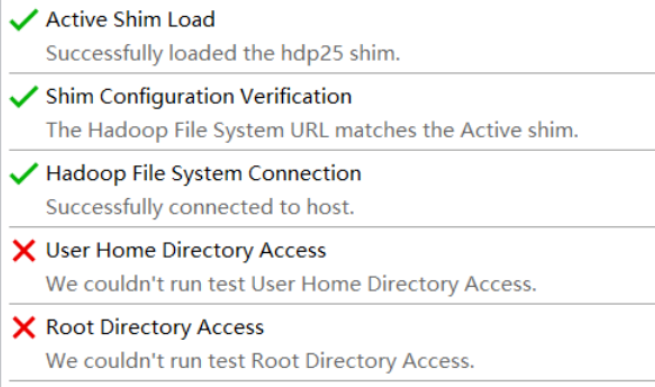
2.填写配置

连接信息只要hadoop file system connection连对就行
再从脚本里托人SQL

在文件里输入路径/文件名
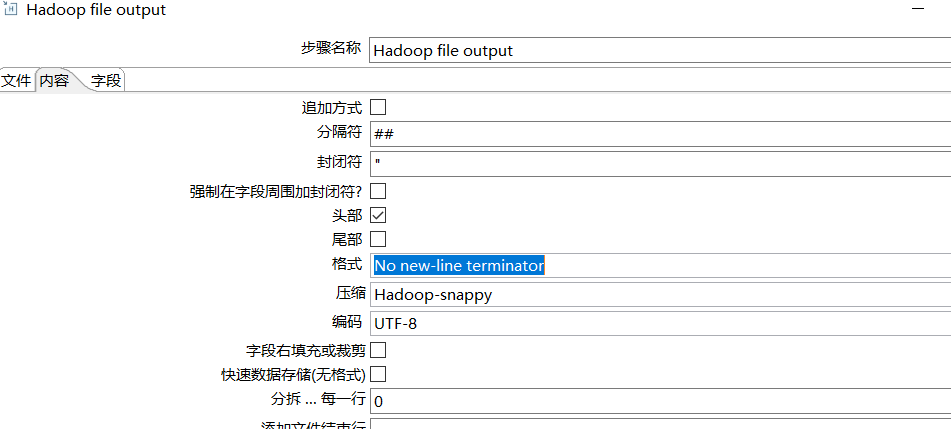
 内容里选择分隔符,是不是显示字段名(头部),压缩格式(orc,snappy)
内容里选择分隔符,是不是显示字段名(头部),压缩格式(orc,snappy)
 在生气了语句里,新建数据库连接,写入sql语句
在生气了语句里,新建数据库连接,写入sql语句

作者:Joseph25
相关文章
Anne
2020-10-24
Vanora
2020-02-14
Rachel
2023-07-20
Psyche
2023-07-20
Winola
2023-07-20
Gella
2023-07-20
Grizelda
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Angie
2023-07-21
Nora
2023-07-24