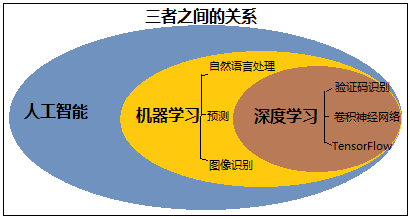
机器学习的基本概念、算法分类、开发流程、数据集划分、工具介绍(python的scikit-learn)
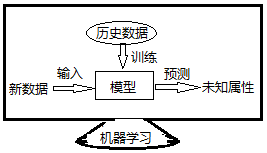
机器学习:是从历史数据中自动分析获取模型,并利用模型对未知数据进行预测。
2、机器学习数据集的构成由特征值(自变量)、目标值(因变量)构成。有些机器学习是可以没有目标值的,如聚类算法。
3、算法分类
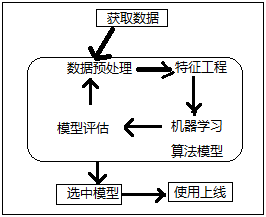
数据预处理:在python中使用pandas库,如:缺失值、异常值等的数据清洗、数据处理
Pandas数据处理:https://blog.csdn.net/weixin_41685388/article/details/103841296
特征工程:是使用专业背景知识和技巧处理数据,使得特征值(自变量)能在机器学习算法上发挥更好的作用的过程。
特征工程主要包含的内容:
特征抽取/提取 特征预处理 特征降维特征工程:https://blog.csdn.net/weixin_41685388/article/details/104398396
5、学习可用数据集Kaggle网址:https://www.kaggle.com/datasets
uci数据集网站:http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
6、scikit-learn工具介绍python语言机器学习工具(包括算法实例、数据集、文档、丰富的API等)
安装:pip install Scikit-learn #指定版本安装:pip install Scikit-learn==0.19.2
依赖numpy、pandas、scipy
导入:import sklearn
7、sklearn数据集7.1. sklearn数据集API介绍
from sklearn import datasets #机器学习数据集库
#sklearn.datasets.load_*() # *:表示某个数据集的名称,load_:获取小规模数据集
df = sklearn.datasets.load_iris() #iris:花的数据集
#print(df)
#sklearn.datasets.fetch_*(data_home=None) # *:表示某个数据集的名称,获取大规模数据集,
#需要从网上下载,data_home:表示数据集下载的目录,默认是~/scikit_learn_data/
#sklearn.datasets.fetch_*(data_home=None,subset='all')
#subset='all' /'train' / 'test' #全部数据集,训练数据集,测试数据集
#sklearn.datasets.fetch_20newsgroups(data_home=None,subset='all')
数据返回的是datasets.base.Bunch(继承自字典)
8、sklearn数据集返回值解释from sklearn import datasets #机器学习数据集库
df = sklearn.datasets.load_iris() #iris:花的数据集
#display(df.data) #返回特征值(自变量)数组
display(df["feature_names"]) #返回特征值的字段名称
display(df.target) #返回目标值(因变量)数组
display(df.target_names) #返回目标值解释
print(df["DESCR"]) #返回描述信息
#构建二维表
data=pd.DataFrame(df.data,columns=list(df["feature_names"]))
data["y"] = df.target
display(data.sample(5))
import sklearn
from sklearn import datasets #机器学习数据集库
#语法:x_train,x_test,y_train,y_test = sklearn.model_selection.train_test_split(x,y,test_size=,random_state=)
#解释:训练的特征值(自变量),测试的特征值,训练的目标值,测试的目标值= 划分函数(x特征值,y目标值,test_size=测试集比例,随机种子)
#datasets.base.Bunch(继承自字典)类
df = sklearn.datasets.load_iris() #iris:花的数据集
x_train,x_test,y_train,y_test = sklearn.model_selection.train_test_split(df.data,df.target,test_size=0.2,random_state=11)
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)
#二维表DataFrame数据类 #先构建二维表
data=pd.DataFrame(df.data,columns=list(df["feature_names"]))
data["y"] = df.target
display(data.sample(5))
x=data[df["feature_names"]]
y=data["y"]
x_train,x_test,y_train,y_test = sklearn.model_selection.train_test_split(x,y,test_size=0.2,random_state=11)
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)
作者:Jalen data analysis