.Net Core 集成 Kafka的步骤
kafka
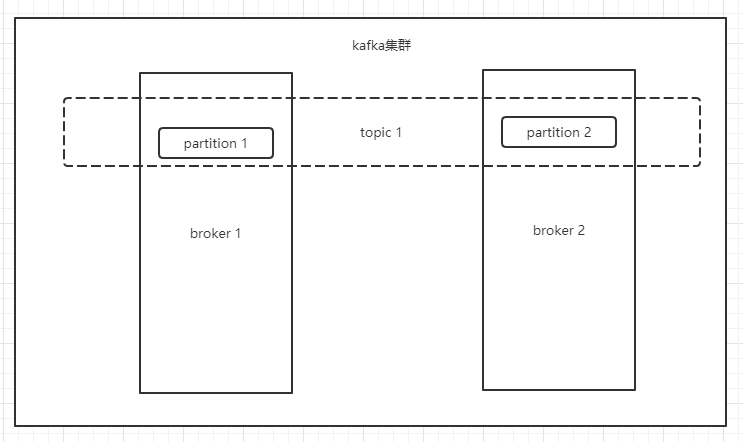
broker
topic
partition
consumer group
安装kafka
.net 操作 kafka
生产者
消费者
运行一下
总结
最近维护的一个系统并发有点高,所以想引入一个消息队列来进行削峰。考察了一些产品,最终决定使用kafka来当做消息队列。以下是关于kafka的一些知识的整理笔记。
kafkakafka 是分布式流式平台。它由linkedin开发,后贡献给了Apache开源组织并成为顶级开源项目。它可以应用在高并发场景下的日志系统,也可以当作消息队列来使用,也可以当作消息服务对系统进行解耦。
流处理平台有以下三种特性:
可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
可以储存流式的记录,并且有较好的容错性。
可以在流式记录产生时就进行处理。
一般它可以应用于两个场景:
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
brokerkafka中的每个节点即每个服务器就是一个broker 。
topickafka中的topic是一个分类的概念,表示一类消息。生产者在生产消息的时候需要指定topic,消费者在消费消息的时候也需要指定topic。
partitionpartition是分区的概念。kafka的一个topic可以有多个partition。每个partition会分散到不同的broker上,起到负载均衡的作用。生产者的消息会通过算法均匀的分散在各个partition上。
consumer groupkafka的消费者有个组的概念。一个partition可以被多consumer group订阅。每个消息会广播到每一个group中。但是每个消息只会被group中的一个consumer消费。相当于每个group,一个partition只能有一个consumer订阅,所以group中的consumer数量不可以超过topic中partition的数量。并且消息的消费的顺序在每个partition中是保证有序的,但是在多个partition之间是不保证的,因为consumer的消费速度是有快慢的。
所以如果要用kafka实现严格的消息队列点对点模式那么我们可以设置一个partition并且设置一个consumer。如果对消息消费的顺序不是那么敏感,那么可以设置多个partition来并行消费消息,提高吞吐量。

为了能体验下kafka,我们还是要实际安装一下kafka,毕竟空想是没有用的。现在有了docker,安装起来也是相当滴简单。我们只需要定义好docker-compose的yml就行了。
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.0.117
KAFKA_CREATE_TOPICS: "test:3:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
1.我们在yml里定义2个service:
2.zookeeper,kafka的分布式依赖zookeeper,所以我需要先定义它。
kafka ,kafka的定义有几个地方要注意的。
depends_on:zookeeper 指定kafka依赖zookeeper这个service,当启动kafka的时候自动会启动zookeeper。
KAFKA_ADVERTISED_HOST_NAME 这里要指定宿主机的ip
KAFKA_CREATE_TOPICS 这个变量只是的默认创建的topic。"test:3:1"代表创建一个名为test的topic并且创建3个分区1个复制。
定义好这些之后我们只需要使用docker-compose命令运行它:
sudo docker-compose up -d
.net 操作 kafka安装好kafka的docker环境之后,下面演示下如何使用.net操作kafka,进行消息的生产与消费。
生产者
static async Task Main(string[] args)
{
Console.WriteLine("Hello World Producer!");
var config = new ProducerConfig
{
BootstrapServers = "192.168.0.117:9092",
ClientId = Dns.GetHostName(),
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
string topic = "test";
for (int i = 0; i < 100; i++)
{
var msg = "message " + i;
Console.WriteLine($"Send message: value {msg}");
var result = await producer.ProduceAsync(topic, new Message<Null, string> { Value = msg });
Console.WriteLine($"Result: key {result.Key} value {result.Value} partition:{result.TopicPartition}");
Thread.Sleep(500);
}
}
Console.ReadLine();
}
新建一个控制台项目,从nuget安装kafka的官方client。
Install-Package Confluent.Kafka
代码非常简单,使用ProducerBuilder构造一个producer,然后调用ProduceAsync方法发送消息。
其中需要注意的是如果你的场景并发非常之高,官方文档推荐的方法是Produce而不是ProduceAsync。这是一个比较迷的地方。按常理使用ProduceAsync应该比使用同步方法Produce能获得更高的并发才对。但是文档确确实实说高并发场景请使用Produce。可能是为了避免ProduceAsync结果返回的时候异步线程上下文切换造成的性能开销。
原文:
消费者There are a couple of additional benefits of using the Produce method. First, notification of message delivery (or failure) is strictly in the order of broker acknowledgement. With ProduceAsync, this is not the case because Tasks may complete on any thread pool thread. Second, Produce is more performant because there is unavoidable overhead in the higher level Task based API.
static void Main(string[] args)
{
Console.WriteLine("Hello World kafka consumer !");
var config = new ConsumerConfig
{
BootstrapServers = "192.168.0.117:9092",
GroupId = "foo",
AutoOffsetReset = AutoOffsetReset.Earliest
};
var cancel = false;
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
var topic = "test";
consumer.Subscribe(topic);
while (!cancel)
{
var consumeResult = consumer.Consume(CancellationToken.None);
Console.WriteLine($"Consumer message: { consumeResult.Message.Value} topic: {consumeResult.Topic} Partition: {consumeResult.Partition}");
}
consumer.Close();
}
}
消费者的演示代码同样很简单。我们需要指定groupId,然后订阅topic。使用ConsumerBuilder构造一个consumer,然后调用Consume方法进行消费就可以。
注意:
这里默认是自动commit消费。你也可以根据情况手动提交commit。
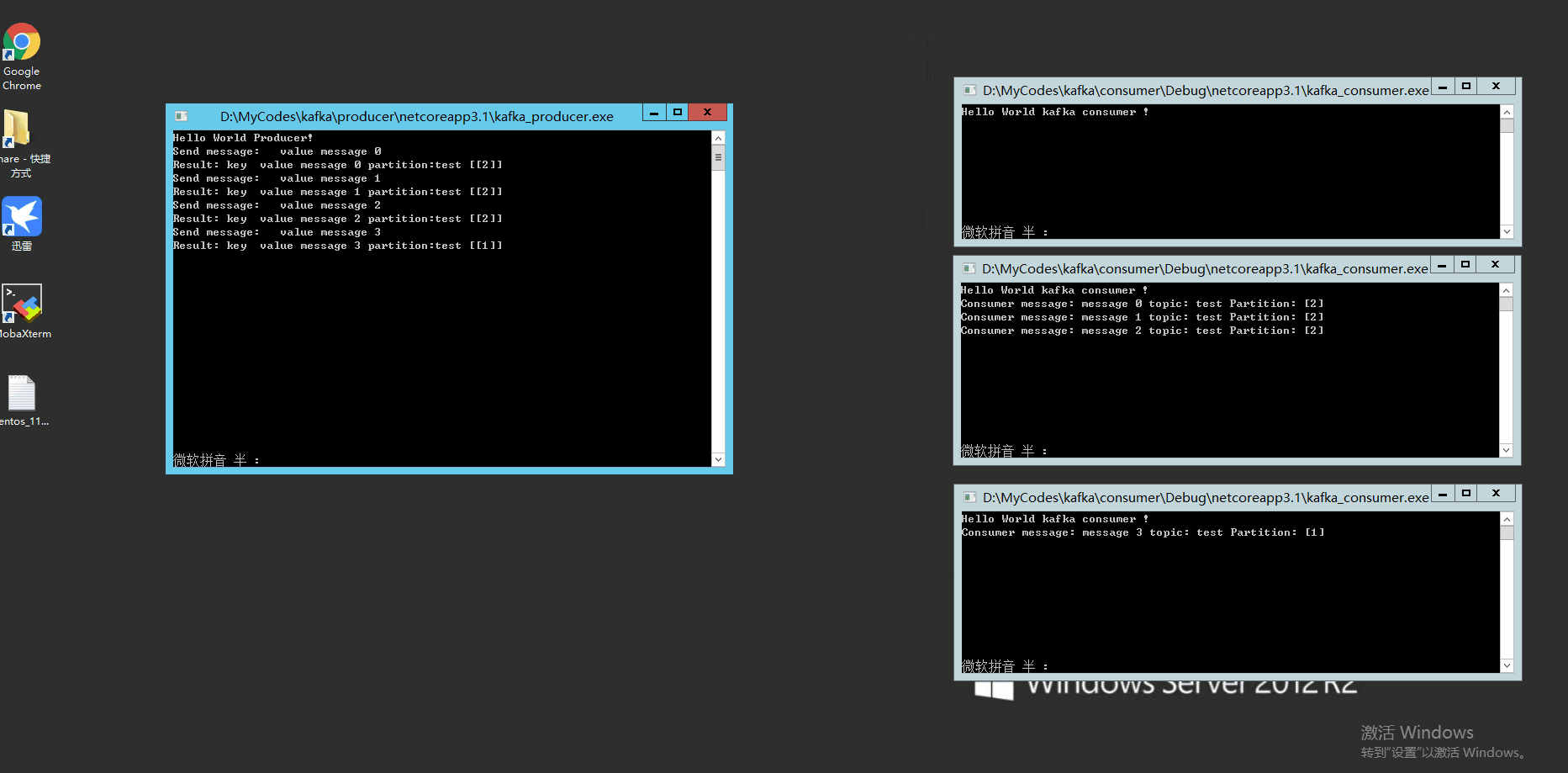
我们运行一个生产者进程,按照500ms的速度生产消息。运行三个consumer进行消费,可以看到消息被均匀的推送到三个consumer上去。
总结以上简单的介绍了kafka的背景、安装方法、使用场景。还简单演示了如何使用.net来操作kafka。它可以当作流式计算平台来使用,也可以当作传统的消息队列使用。它当前非常流行,网上的资料也多如牛毛。官方也提供了简单易用的.net sdk ,为.net 平台集成kafka提供了便利。
以上就是.Net Core 集成 Kafka的步骤的详细内容,更多关于.Net Core 集成 Kafka的资料请关注软件开发网其它相关文章!