K-Means欠采样处理不平衡样本python实现
K-Means欠采样python实现
作者:SQAHJSW
1. K-Means欠采样原理
为解决分类问题中效果受样本集类间不平衡,并提高训练样本的多样性,可以使用K-Means欠采样对样本进行平衡处理。该方法利用K-means方法对大类样本聚类,形成与小类样本个数相同的簇类数,从每个簇中随机抽取单个样本与风险样本形成平衡样本集。K-means欠采样过程如下:
Step1:随机初始化k个聚类中心,分别为uj(1,2,…,k);
Step2:对于大样本xi(1,2,…,n),计算样本到每个聚类中心uj的距离,将xi划分到聚类最小的簇,c(i)为样本i与k个类中距离最近的那个类,c(i)的值为1到k中的一个,则c(i)计算如式(1)所示:
![]()
Step3:待样本全部划分完成之后,重新确定簇中心,uj计算如式(5)所示:
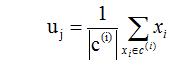
Step4:重复步骤2和步骤3,直到总距离(各个簇中样本与各自簇中心距离之和)不再降低,返回最后的聚类结果;
Step5:从每个簇中随机抽取单个样本,与风险样本合并形成平衡样本集。
2. K-Means欠采样demo
from pandas as pd
from numpy as np
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 10, max_iter = 500) #10为小样本数,500为迭代的次数
model.fit(data)#data为大样本数据集
result = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #输出每个样本对应的类别
result.columns = list(data.columns) + [u'聚类类别'] #重命名表头
df = pd.DataFrame(columns = list(r.columns))
for i in range(0,10):
N_data = r[r["聚类类别"]==i]
N_data = N_data.sample(n=1,axis=0)
df = pd.concat([df,N_data])
print(df)#df为从每个簇中抽取单个样本的结果
data0 = df.iloc[:,:25]
class = np.zeros((10,1))
data0["class"] = class#将原来样本的标签赋值回来
r = pd.concat([data0,data1])#和小类样本拼接起来
作者:SQAHJSW