【Python_002】RFM人群模型 X Kmeans 聚类算法
数据分析中常用RFM分析消费者人群,但常见RFM是用均值区分。 均值区分与利用Kmeans区别在于前者人为划定R、F、M高低界限(以均值为界限),后者为通过不断迭代确定界限(不过两者对于异常点都较为敏感)
RFM模型首先介绍一下RFM模型
R – Recency 最近一次消费的时间
F – Frequency 一段时间内的消费频次
M – Monetary 一段时间内的消费金额
RFM模型主要用来划分客户/消费者,通过上述三个指标衡量客户/消费者价值
每个指标都分为0和1两档,1就是高,0就是低。把人群划分为2 * 2 * 2=8种:
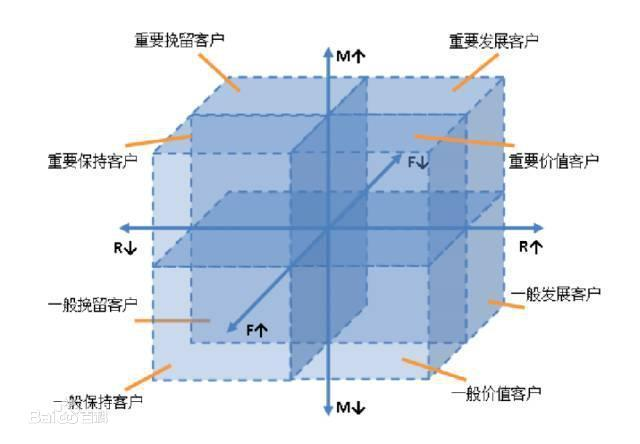
上图源于百度百科
具体分类:
111 – 重要价值人群
101 – 重要发展人群
011 – 重要保持人群
001 – 重要挽留人群
110 – 一般价值人群
100 – 一般发展人群
010 – 一般保持人群
000 – 一般挽留人群
具体应用:
最简单的例子,淘宝店给你发短信推送,开头到底是说“亲,好久不见” (例如针对重要保持人群和重要挽留人群),还是说“尊敬的VIP用户”(例如针对重要价值恩群),就可以靠RFM实现。
还可以通过RFM模型对不同人群做不同类型的促销来实现引流,提高复购率。
KMeans 聚类算法 什么是聚类先说一下聚类的概念
相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性
一句话概括就是:物以类聚,人以群分
Kmeans 常用距离作为组内判断依据,也就是看每个样本点离各组组内中心的距离,离哪个组中心更近,该样本点就属于哪组
算法原理先设定组数,也就是k到底等于几 (K必须事先给定,对于事先不知道需要划分成机组的数据集来说,这是Kmeans的缺点之一)
随机选取k个点,作为每组初始中心(因为之后需要不断迭代,所以最开始的随机点的位置并不是很重要)
计算每个样本点到各组初始中心的距离,把样本点分到最近的初始中心,这样形成了初始的K组
重新计算组内中心(以当前组内样本点的均值作为计算依据)
重复第三步与第四步,直到每个样本点不再有变化为止,或者达到指定的迭代次数
代码实现import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from mpl_toolkits.mplot3d import Axes3D
#读取数据
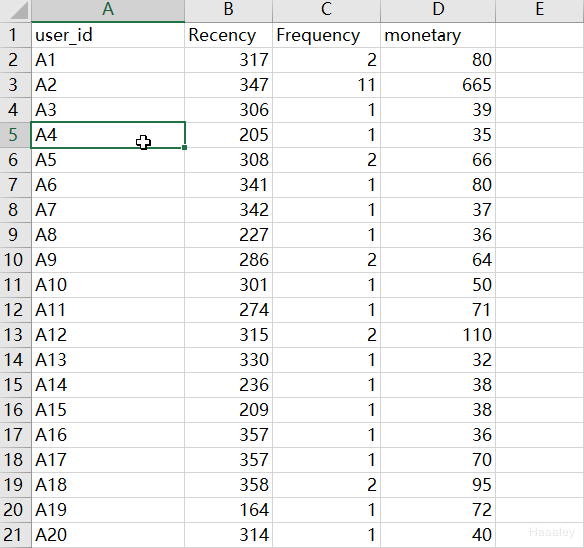
user_data = pd.read_excel("RFM X Kmeans data.xlsx")
X = user_data.values[:,1:]
# y是为了把object转成float 方便后续画图
figdata = pd.DataFrame(X.astype(float).round(3),columns=['Recency','Frequency','Monetary'])
#设定组数
k = 8
model = KMeans(n_clusters=k)
result = model.fit(X)
#每行数据被分到的组存在labels_属性中
label = model.labels_
''' 以下几行代码只是为了看一下每组质心以及每组数量
centroids =model.cluster_centers_
group = pd.Series(model.labels_,name ='user_cnt').value_counts()
client = pd.DataFrame(centroids.round(3),columns = ['Recency','Frequency','Monetary'])
client = pd.merge(client,group,left_index=True,right_index=True,how='left')
'''
R = figdata['Recency']
F = figdata['Frequency']
M = figdata['Monetary']
colors = ['red','darkorange','teal','gold','plum','pink','skyblue','sandybrown']
clist = []
for i in label:
clist.append(colors[i%8])
#绘制散点图
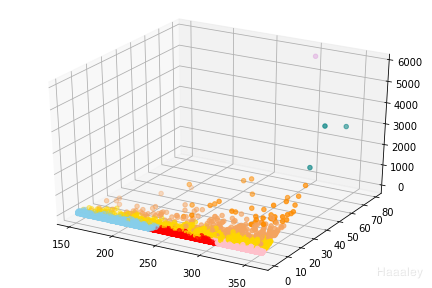
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(R,F,M,c=clist)
数据源展示
效果图展示:
作者:Haaaley