机器学习算法-kmeans 聚类算法一
1.1 k-means算法的步骤
假设k=3,要分3个群体
随机在数据当中抽取3个样本,当作三个类别的中心点(k1,k2,k3) 计算其余的点分别到这3个中心点的距离,每一个样本有3个距离(a,b,c),从中选出距离最近的一个点作为自己的标记形成3个族群。 分别计算这3个族群的平均值,把3个平均值与之前的3个旧中心点进行比较如果相同,结束聚类,算法收敛。
如果不相同:把这3个平均值当做新的中心点,从第二步开始重新开始。
1.2 k-means算法的评估标准
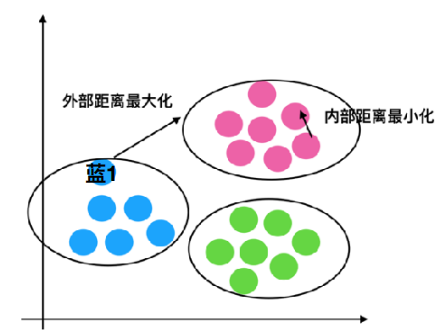
外部距离最大化,内部距离最小化。

1、计算蓝1到自身类别的点距离的平均值a_i
2、计算蓝1分别到红色类别,绿色类别所有的点的距离,求出平均值
b1, b2,取其中最⼩的值当做b_i
轮廓系数的范围为:[-1 1]
简单案例:
# -*- coding: utf-8 -*-
# @File : k-means2.py
# @Date : 2020-02-18 11:25
# @Author : admin
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
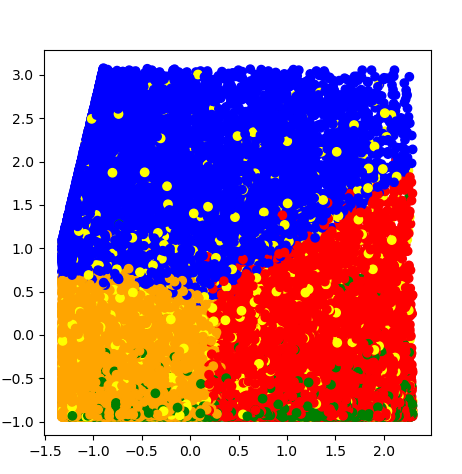
def programmer_4():
inputfile = '../data/zscoreddata.xls'
k = 5
data = pd.read_excel(inputfile)
kmodel = KMeans(n_clusters=k, n_jobs=4)
kmodel.fit(data)
r1 = pd.Series(kmodel.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) # 找出聚类中心
r = pd.concat([r2, r1], axis=1) # 横向连接(axis=0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + [u'类别个数'] # 重命名表头
print(r)
#matlib 显示
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5));
colored = ["orange", "green", "blue","red","yellow"];
colr = [colored[i] for i in kmodel.labels_];
plt.scatter(data.values[:, 0], data.values[:, 1], color=colr);
plt.show()
programmer_4();
作者:健康平安的活着
相关文章
Serafina
2021-03-06
Quirita
2021-04-07
Jayne
2021-07-02
Alice
2020-11-20
Flower
2021-02-22
Iris
2021-08-03
Rhea
2023-05-31
Pandora
2023-07-07
Tallulah
2023-07-17
Trixie
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Hester
2023-07-20
Ianthe
2023-07-20
Irma
2023-07-20
Valora
2023-07-20
Kirima
2023-07-20