使用IDEA编写SparkSql自定义聚合函数——强类型Dataset(求平均值)
SparkSql自定义聚合函数(强类型Dataset)求平均值
强类型的Dataset提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min();
除此之外,用户可以设定自己的自定义聚合函数。
代码测试前请确保各个组件均已安装
1、环境准备
 作者:风时雨润
作者:风时雨润
1、准备json文件:
{"name": "zhangsan","age": 17}
{"name": "lisi","age": 18}
{"name": "wangwu","age": 20}
2、使用IDEA软件,创建maven工程
3、添加pom依赖
2、maven工程pom依赖
case class UserBean(name: String, age: BigInt)
case class AvgBuffer(var sum: BigInt, var count: Int)
// 1)声明用户自定义聚合函数(强类型)
// 2)继承类Aggregator类,设定泛型【传入的类型,缓冲区计算的类型,返回的类型】
// 3)重写方法
class MyAgeAvgFunctionClass extends Aggregator[UserBean, AvgBuffer, Double] {
// 初始化
override def zero: AvgBuffer = {
AvgBuffer(0, 0)
}
/**
* 聚合数据
* @param b
* @param a
* @return
*/
override def reduce(b: AvgBuffer, a: UserBean): AvgBuffer = {
b.sum = b.sum + a.age
b.count = b.count + 1
b
}
/**
* 缓冲区的合并
* @param b1
* @param b2
* @return
*/
override def merge(b1: AvgBuffer, b2: AvgBuffer): AvgBuffer = {
b1.sum = b1.sum + b2.sum
b1.count = b1.count + b2.count
b1
}
// 计算
override def finish(reduction: AvgBuffer): Double = {
reduction.sum.toDouble / reduction.count
}
override def bufferEncoder: Encoder[AvgBuffer] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
4、创建SparkSql_Aggregate_Class.Scala
import org.apache.spark.{SparkConf, sql}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession, TypedColumn}
object SparkSql_aggregate_Class {
def main(args: Array[String]): Unit = {
// 创建配置对象
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkSql_aggregate")
// 创建SparkSql的环境对象
val spark: SparkSession = new sql.SparkSession.Builder().config(conf).getOrCreate()
/*
进行转换之前需要引入隐式转换规则
这里Spark不是包名的含义,是SparkSession对象的名字
*/
import spark.implicits._
// 创建聚合函数的对象
val udaf = new MyAgeAvgFunctionClass
// 将聚合函数转换为查询列
val avgcol: TypedColumn[UserBean, Double] = udaf.toColumn.name("avgAge")
// 读取数据
val df: DataFrame = spark.read.json("input/sparksql.json")
// 变成DS
val userds: Dataset[UserBean] = df.as[UserBean]
// 应用函数
userds.select(avgcol).show()
// 释放资源
spark.stop()
}
}
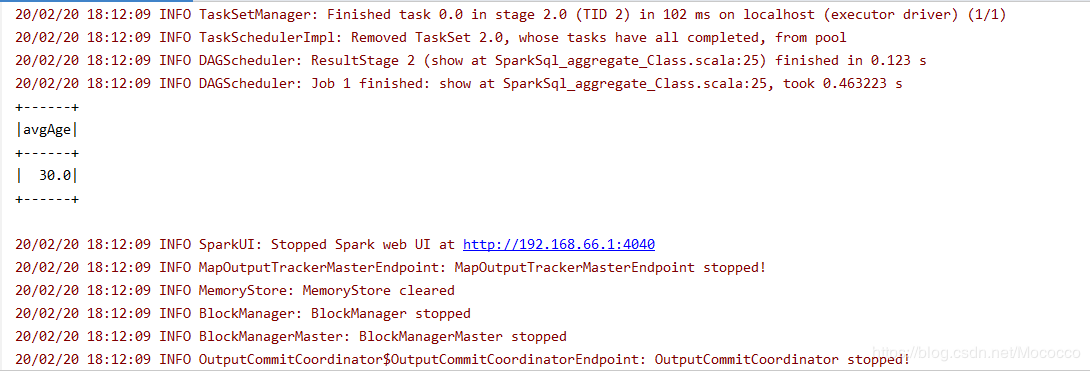
5、运行SparkSql_Aggregate_Class.Scala
得到结果:
作者:风时雨润
相关文章
Opal
2020-12-05
Xandy
2021-01-24
Gella
2020-12-11
Bella
2020-07-24
Ianthe
2023-07-20
Lani
2023-07-20
Thirza
2023-07-20
Rhoda
2023-07-20
Tesia
2023-07-20
Ursula
2023-07-20
Edana
2023-07-20
Dabria
2023-07-20
Paula
2023-07-20
Peony
2023-07-20
Rayna
2023-07-20
Fawn
2023-07-21
Tia
2023-07-21
Victoria
2023-07-21
Crystal
2023-07-21