Pythonsklearn分类决策树方法详解
决策树模型
决策树学习
使用Scikit-learn进行决策树分类
决策树模型决策树(decision tree)是一种基本的分类与回归方法。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
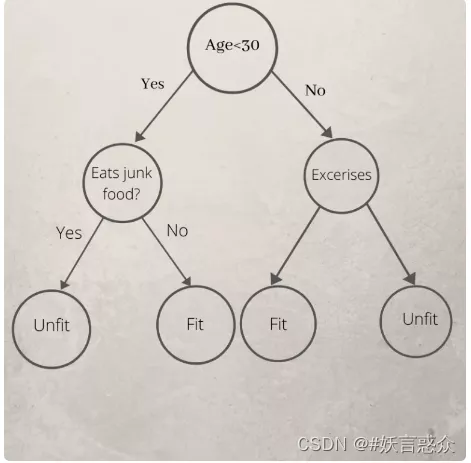
用于预测一个人是否肥胖或不肥胖的决策树
决策树学习决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用的算法有ID3、 C4.5和CART。
1、特征选择的目的在于选取对训练数据能够分类的特征。特征选择的关键是其准则。常用的准则如下:
(1)样本集合D对特征A的信息增益(ID3)
(2)样本集合D对特征A的信息增益比(C4.5)
(3)样本集合D的基尼指数(CART)
2.决策树的生成。通常使用信息增益最大、信息增益比最大或基尼指数最小作为特征选择的准则。决策树的生成往往通过计算信息增益或其他指标,从根结点开始,递归地产生决策树。这相当于用信息增益或其他准则不断地选取局部最优的特征,或将训练集分割为能够基本正确分类的子集。
3.决策树的剪枝。由于生成的决策树存在过拟合问题,需要对它进行剪枝,以简化学到的决策树。决策树的剪枝,往往从已生成的树上剪掉一些叶结点或叶结点以上的子树,并将其父结点或根结点作为新的叶结点,从而简化生成的决策树。
使用Scikit-learn进行决策树分类import numpy as np
from sklearn.datasets import load_iris
from sklearn import tree
import matplotlib.pyplot as plt
iris=load_iris()
print(iris.feature_names)
print(iris.target_names)
#划分数据集
removed =[0,50,100]
new_target = np.delete(iris.target,removed)
new_data = np.delete(iris.data,removed, axis=0)
#训练分类器
clf = tree.DecisionTreeClassifier() # 定义决策树分类器
clf=clf.fit(new_data,new_target)
prediction = clf.predict(iris.data[removed])
print("Original Labels",iris.target[removed])
print("Labels Predicted",prediction)
#绘制决策树
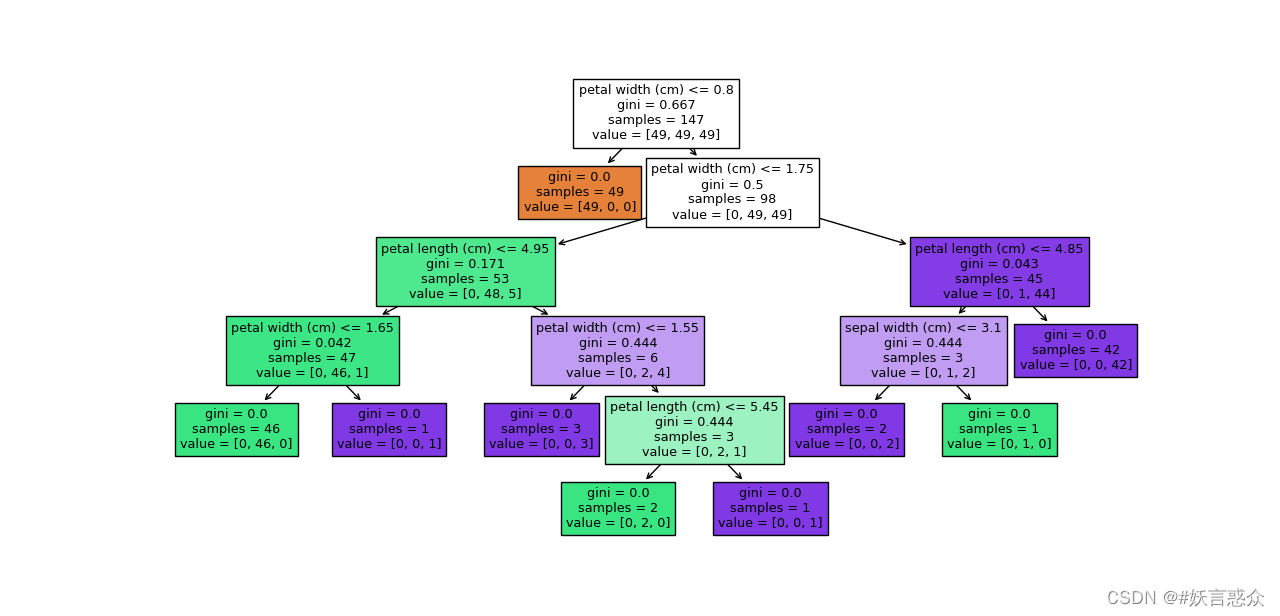
plt.figure(figsize=(15, 10))
tree.plot_tree(clf, feature_names=iris.feature_names, filled=True)
plt.show()
参考链接传送门
到此这篇关于Python sklearn分类决策树方法详解的文章就介绍到这了,更多相关Python sklearn决策树内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!