主流卷积神经网络结构探索和分析(三)
接上一片的内容,本篇博客主要讨论(一)中分析的网络具体结构及keras实现方法
3 VGG16,VGG16_bigConv, GoogLeNet_V3及ResNet18网络结构详解及Keras实现方法 3.1 VGG16前面的博客已经对VGG16的思路进行了阐述,这里直接给出VGG16的网络结构图。

keras代码如下:
def build_vgg16_model(weight_decay, num_classes, x_shape,learning_rate, lr_decay):
# Build the network of vgg for 10 classes with massive dropout and weight decay as described in the paper.
print('start model')
model = Sequential()
# weight_decay = self.weight_decay
print('start 1st Conv2D')
#model.add(Conv2D(64, (3, 3), padding='same', input_shape=x_shape, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(64, (3, 3), padding='same', input_shape=x_shape, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.3))
print('start 2st Conv2D')
model.add(Conv2D(64, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
print('start 3st Conv2D')
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 4st Conv2D')
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
print('start 5st Conv2D')
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 6st Conv2D')
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 7st Conv2D')
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
print('start 8st Conv2D')
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 9st Conv2D')
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 10st Conv2D')
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
print('start 11st Conv2D')
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 12st Conv2D')
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
print('start 13st Conv2D')
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
print('start 14st Conv2D')
model.add(Flatten())
model.add(Dense(512, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
print('start 15st Conv2D')
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=learning_rate, decay=lr_decay, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
3.2 VGG16_bigConv
VGG16的基本思路是用若干个3x3的卷积层串联来模拟5x5或者7x7的感受野,同时降低网络的参数量。为了对比多个3x3卷积层串联与单个5x5,7x7的卷积层的效果。作者特意将VGG16中的3x3卷积核串联的层替换成了5x5,7x7的卷积层,以CIFAR10数据集对比识别的效果。
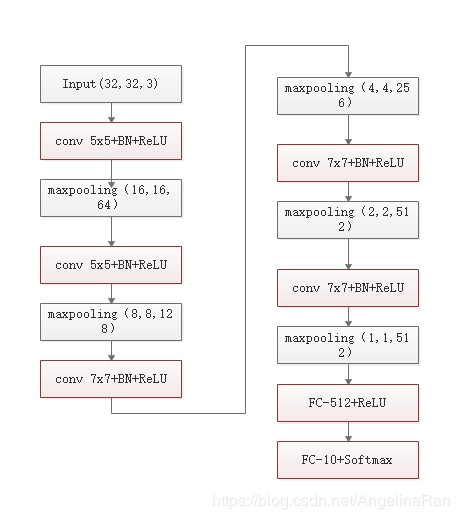
keras代码如下:
def build_vgg16_big_model(weight_decay, num_classes, x_shape,learning_rate, lr_decay):
# Build the network of vgg for 10 classes with massive dropout and weight decay as described in the paper.
model = Sequential()
model.add(Conv2D(64, (5, 5), padding='same',
input_shape=x_shape, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (7, 7), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(512, (7, 7), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(512, (7, 7), padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.4))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512, kernel_regularizer=regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=learning_rate, decay=lr_decay, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
3.3 GoogLeNet_V3
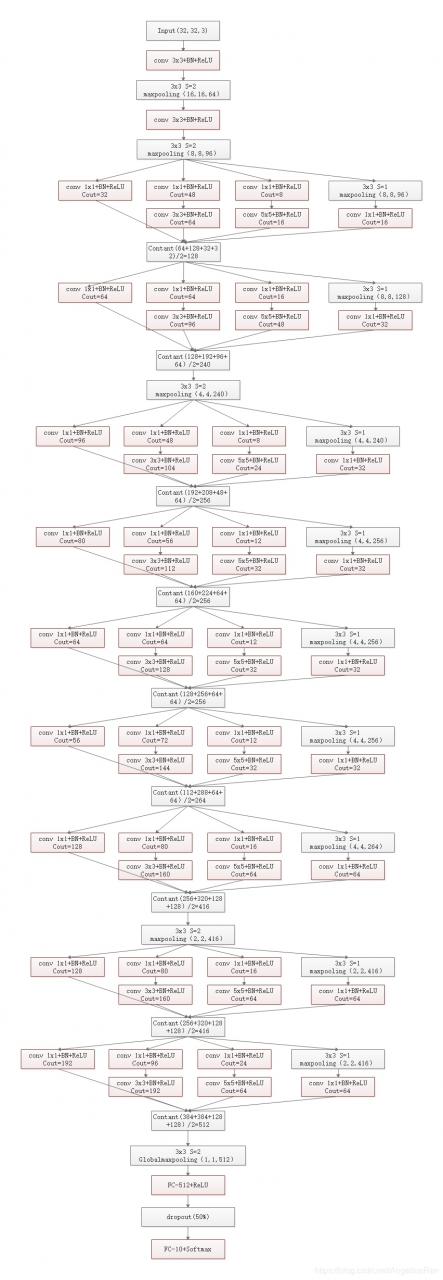
keras代码如下:
def GoogLeNet_submod(model,Co_array,weight_decay):
# Co_arry [0] conv1x1 [1] conv3x3reduce [2] conv3x3 [3] conv5x5reduce [4] conv5x5 maxpooling [6] conv1x1
x=model.output
x1=Conv2D(Co_array[0], (1, 1), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x)
x1=BatchNormalization()(x1)
x1=Activation('relu')(x1)
x2=Conv2D(Co_array[1], (1, 1), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x)
x2=BatchNormalization()(x2)
x2=Activation('relu')(x2)
x2=Conv2D(Co_array[2], (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x2)
x2=BatchNormalization()(x2)
x2=Activation('relu')(x2)
x3 = Conv2D(Co_array[3], (1, 1), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x)
x3=BatchNormalization()(x3)
x3=Activation('relu')(x3)
x3 = Conv2D(Co_array[4], (5, 5), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x3)
x3=BatchNormalization()(x3)
x3=Activation('relu')(x3)
x4= MaxPooling2D(pool_size=(2, 2), strides=1,padding='same')(x)
x4=Conv2D(Co_array[5], (1, 1), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x)
x4 = BatchNormalization()(x4)
x4 = Activation('relu')(x4)
xout=Concatenate(axis=-1)([x1,x2,x3,x4])
modelout = Model(inputs=model.input, outputs=xout)
return modelout
def build_inceptionV3_model(weight_decay, num_classes, x_shape,learning_rate, lr_decay):
input1=Input(x_shape)
x=Conv2D(64, (3, 3), padding='same',
input_shape=x_shape, kernel_regularizer=regularizers.l2(weight_decay))(input1)
x=BatchNormalization()(x)
x=Activation('relu')(x)
x=MaxPooling2D(pool_size=(3, 3), strides=2,padding='same')(x)
x=Conv2D(96, (5, 5), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x)
x=BatchNormalization()(x)
x=Activation('relu')(x)
#model.add(Dropout(0.4))
x=MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
model = Model(inputs=input1, outputs=x)
sgd = optimizers.SGD(lr=learning_rate, decay=lr_decay, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
Co_array=np.array([64,96,128,16,32,32],dtype=int)
Co_array=Co_array/2
Co_array=Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) #intercept 3a
Co_array = np.array([128,128,192,32,96,64])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 3b
#model.add(MaxPooling2D(pool_size=(3, 3), strides=2, padding='same'))
x=MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(model.output)
model = Model(inputs=input1, outputs=x)
Co_array = np.array([192, 96, 208, 16, 48, 64])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 4a
Co_array = np.array([160, 112, 224, 24, 64, 64])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 4b
Co_array = np.array([128, 128, 256, 24, 64, 64])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 4c
Co_array = np.array([112, 144, 288, 32, 64, 64])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 4d
Co_array = np.array([256, 160, 320, 32, 128, 128])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 4e
#model.add(MaxPooling2D(pool_size=(3, 3), strides=2, padding='same'))
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(model.output)
model = Model(inputs=input1, outputs=x)
Co_array = np.array([256, 160, 320, 32, 128, 128])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 5a
Co_array = np.array([384, 192, 384, 48, 128, 128])
Co_array=Co_array/2
Co_array = Co_array.astype(np.int32)
print(Co_array)
model = GoogLeNet_submod(model, Co_array, weight_decay) # intercept 5b
x=GlobalMaxPooling2D()(model.output)
#x=Flatten()(x)
x=Dense(512, kernel_regularizer=regularizers.l2(weight_decay))(x)
x=BatchNormalization()(x)
x=Activation('relu')(x)
x=Dropout(0.5)(x)
x=Dense(num_classes)(x)
x=Activation('softmax')(x)
model = Model(inputs=input1, outputs=x)
return model
3.4 ResNet18

keras代码如下:
def build_resnet_block(model, Cout, Stride, weight_decay):
x=model.output
x1=Conv2D(Cout, (3, 3), padding='same', strides=Stride, kernel_regularizer=regularizers.l2(weight_decay))(x)
x1=BatchNormalization()(x1)
x1=Activation('relu')(x1)
x1=Conv2D(Cout, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x1)
x1=BatchNormalization()(x1)
if Stride:
x2=Conv2D(Cout, (1, 1), padding='same', strides=Stride, kernel_regularizer=regularizers.l2(weight_decay))(x)
x2=BatchNormalization()(x2)
else:
x2=x
x1=Add()([x1,x2])
x=Activation('relu')(x1)
x1=Conv2D(Cout, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x)
x1=BatchNormalization()(x1)
x1=Activation('relu')(x1)
x1=Conv2D(Cout, (3, 3), padding='same', kernel_regularizer=regularizers.l2(weight_decay))(x1)
x1=BatchNormalization()(x1)
x1=Add()([x1,x])
x1=Activation('relu')(x1)
modelout = Model(inputs=model.input, outputs=x1)
return modelout
def build_ResNet18_model(weight_decay, num_classes, x_shape,learning_rate, lr_decay):
input1=Input(x_shape)
x=Conv2D(64, (3, 3), padding='same',
input_shape=x_shape, kernel_regularizer=regularizers.l2(weight_decay))(input1)
x=BatchNormalization()(x)
x=Activation('relu')(x)
x=MaxPooling2D(pool_size=(3, 3), strides=2,padding='same')(x)
model = Model(inputs=input1, outputs=x)
sgd = optimizers.SGD(lr=learning_rate, decay=lr_decay, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model=build_resnet_block(model, 64, 1,weight_decay)
model=build_resnet_block(model, 128, 2,weight_decay)
model=build_resnet_block(model, 256, 2,weight_decay)
model=build_resnet_block(model, 512, 2,weight_decay)
x=model.output
x=GlobalMaxPooling2D()(x)
x=Dense(512, kernel_regularizer=regularizers.l2(weight_decay))(x)
x=BatchNormalization()(x)
x=Activation('relu')(x)
x=Dropout(0.5)(x)
x=Dense(num_classes)(x)
x=Activation('softmax')(x)
model = Model(inputs=input1, outputs=x)
sgd = optimizers.SGD(lr=learning_rate, decay=lr_decay, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
3.5 模型对比
3.5.1 模型训练过程中的收敛情况对比
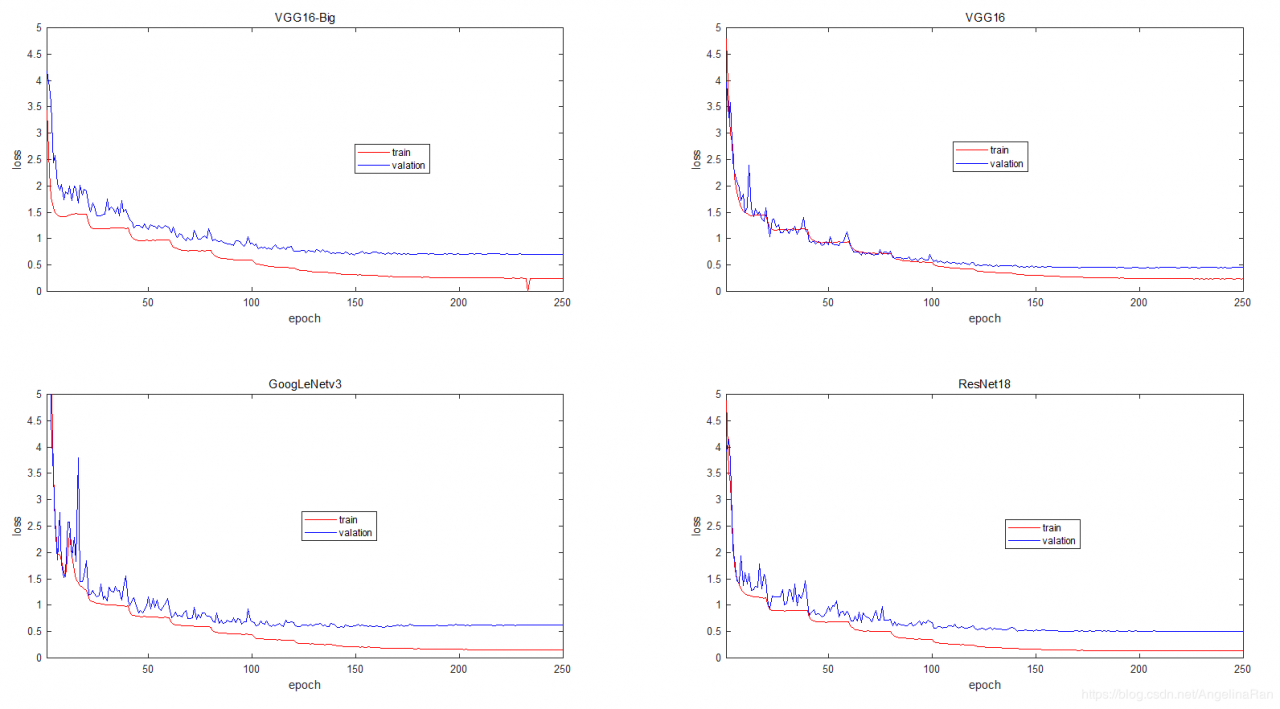
下图展示了训练过程中Loss函数值的变化情况。
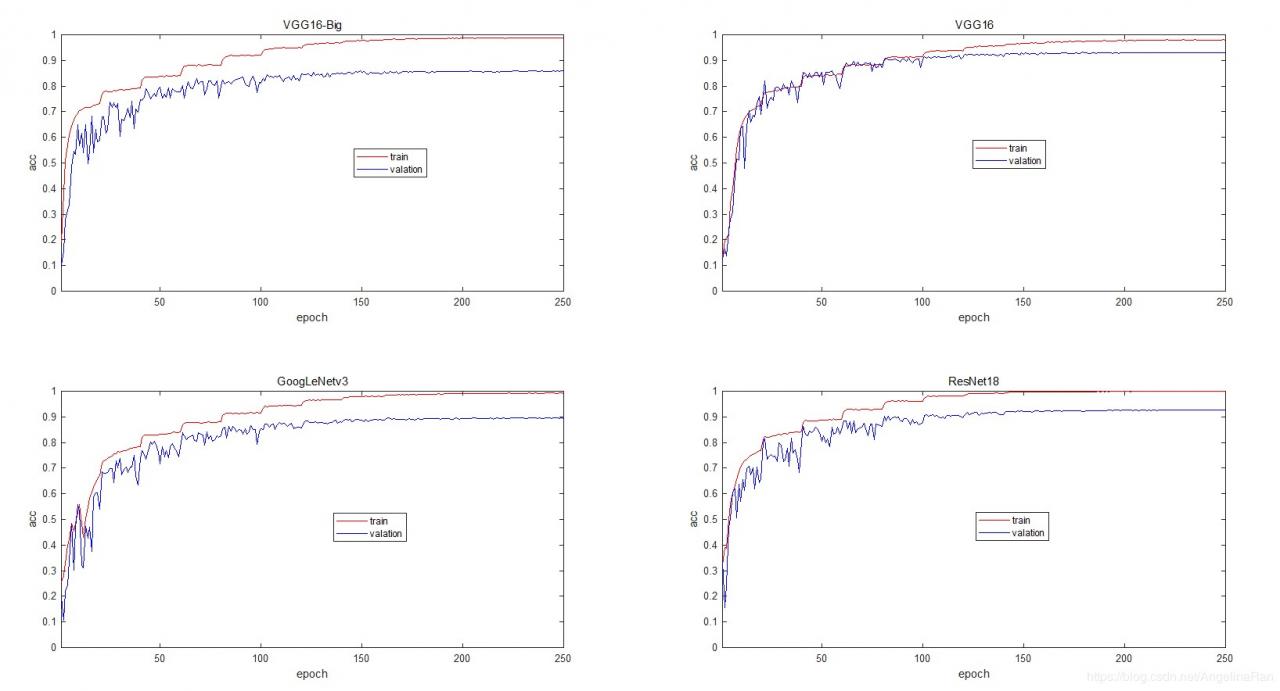
下图展示了训练过程中分类精度的变化情况:
下表展现了4种模型的完成训练后的分类精度比较:
| model | accuracy (train) (%) | accuracy (valation) (%) | epoch |
|---|---|---|---|
| VGG16 | 97.93 | 93.04 | 100左右 |
| VGG16-big | 98.84 | 85.91 | 100左右 |
| GoogLeNetv3 | 99.24 | 89.46 | 150左右 |
| ResNet18 | 99.90 | 92.70 | 150左右 |
从训练过程看,VGG16和VGG16-big的模型复杂度较低,训练过程收敛速度较快。但采用较大感受野后的模型精度下降了好7个点左右,估计层数降低之后,模型的表达能力还是降低了不少。博主有时间的时候会进一步在不同的数据集上进行测试。
GoogLeNet和ResNet模型的复杂度较大,模型训练的时间相对较长,模型的精度也有所提高。但GoogLeNet的模型出现了比较大的过拟合,在训练集上达到了99.24%,但验证集上只能到89.46%。而ResNet的网络在训练集上达到99.9%,而验证集上的分类精度为:92.7%。
笔者在执行的过程中,没有加入参数的正则化。下一篇博客,笔者将详细讨论参数正则化对模型精度和训练过程的影响。
如果你的 targets 是 one-hot 编码,用 categorical_crossentropy
one-hot 编码:[0, 0, 1], [1, 0, 0], [0, 1, 0]
如果你的 tagets 是 数字编码 ,用 sparse_categorical_crossentropy
数字编码:2, 0, 1
简单来说,就是fit支持能放进RAM的小规模的数据集训练,fit_generator支持大规模的数据集,且支持一个数据增强的训练数据生成器,而train_on_batch则支持任意大小的(不一定要满足batch_size)的数据的训练。
详细内容可参考博客如何使用Keras fit和fit_generator(动手教程)
问题:完成第一遍设计的时候,一个VGG16在CIFAR10上跑了三天的训练,受不了了,赶紧想办法。后来发现是keras没有调用GPU进行训练。
解决方法:把tensorflow卸载,重新装成tensorflow-gpu版本,解决了。
作者:AngelinaRan