动手学深度学习 Task05 卷积神经网络基础;leNet;卷积神经网络进阶
【一】卷积神经网络基础
二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏置来得到输出。卷积层的模型参数包括卷积核和标量偏置。
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
互相关运算与卷积运算
卷积层得名于卷积运算,但卷积层中用到的并非卷积运算而是互相关运算。我们将核数组上下翻转、左右翻转,再与输入数组做互相关运算,这一过程就是卷积运算。由于卷积层的核数组是可学习的,所以使用互相关运算与使用卷积运算并无本质区别。
特征图与感受野
二维卷积层输出的二维数组可以看作是输入在空间维度(宽和高)上某一级的表征,也叫特征图(feature map)。影响元素 x 的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做 x 的感受野(receptive field)。
填充
填充(padding)是指在输入高和宽的两侧填充元素(通常是0元素)
步幅
在互相关运算中,卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)。
多输入通道
卷积层的输入可以包含多个通道,图4展示了一个含2个输入通道的二维互相关计算的例子。
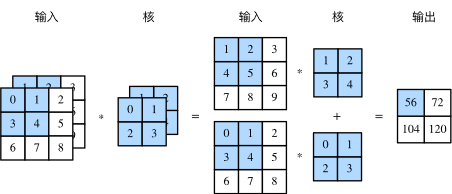
假设输入数据的通道数为 ci ,卷积核形状为 kh×kw ,我们为每个输入通道各分配一个形状为kh×kwk_h×k_wkh×kw 的核数组,将cic_ici 个互相关运算的二维输出按通道相加,得到一个二维数组作为输出。我们把cic_ici 个核数组在通道维上连结,即得到一个形状为 ci×kh×kwc_i×k_h×k_wci×kh×kw 的卷积核。
多输出通道
卷积层的输出也可以包含多个通道,设卷积核输入通道数和输出通道数分别为cic_ici 和 coc_oco ,高和宽分别为khk_hkh和 kwk_wkw 。如果希望得到含多个通道的输出,我们可以为每个输出通道分别创建形状为 ci×kh×kwc_i×k_h×k_wci×kh×kw 的核数组,将它们在输出通道维上连结,卷积核的形状即 ci×kh×kwc_i×k_h×k_wci×kh×kw 。
对于输出通道的卷积核,我们提供这样一种理解,一个 ci×kh×kwc_i×k_h×k_wci×kh×kw 的核数组可以提取某种局部特征,但是输入可能具有相当丰富的特征,我们需要有多个这样的 ci×kh×kwc_i×k_h×k_wci×kh×kw的核数组,不同的核数组提取的是不同的特征。
池化层的简洁实现
我们使用Pytorch中的nn.MaxPool2d实现最大池化层,关注以下构造函数参数:
forward函数的参数为一个四维张量,形状为(N,C,Hin,Win)(N, C, H_{in}, W_{in})(N,C,Hin,Win),返回值也是一个四维张量,形状为 (N,C,Hout,Wout)(N, C, H_{out}, W_{out})(N,C,Hout,Wout),其中 NNN 是批量大小,C,H,WC,H,WC,H,W 分别表示通道数、高度、宽度。
代码讲解
X = torch.arange(32, dtype=torch.float32).view(1, 2, 4, 4)
pool2d = nn.MaxPool2d(kernel_size=3, padding=1, stride=(2, 1))
Y = pool2d(X)
print(X)
print(Y)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.]]]])
tensor([[[[ 5., 6., 7., 7.],
[13., 14., 15., 15.]],
[[21., 22., 23., 23.],
[29., 30., 31., 31.]]]])
平均池化层使用的是nn.AvgPool2d,使用方法与nn.MaxPool2d相同。
【二】leNet
LeNet 模型
LeNet分为卷积层块和全连接层块两个部分
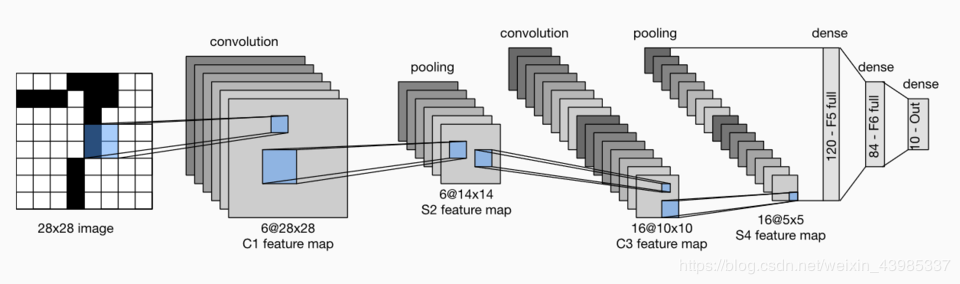 卷积层块里的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的平均池化层则用来降低卷积层对位置的敏感性。
卷积层块里的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的平均池化层则用来降低卷积层对位置的敏感性。
卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用 5×5 的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
下面通过Sequential类来实现LeNet模型。
#import
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
import torch
import torch.nn as nn
import torch.optim as optim
import time
#net
class Flatten(torch.nn.Module): #展平操作
def forward(self, x):
return x.view(x.shape[0], -1)
class Reshape(torch.nn.Module): #将图像大小重定型
def forward(self, x):
return x.view(-1,1,28,28) #(B x C x H x W)
net = torch.nn.Sequential( #Lelet
Reshape(),
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), #b*1*28*28 =>b*6*28*28
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*6*28*28 =>b*6*14*14
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), #b*6*14*14 =>b*16*10*10
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*16*10*10 => b*16*5*5
Flatten(), #b*16*5*5 => b*400
nn.Linear(in_features=16*5*5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
【三】卷积神经网络进阶
使用重复元素的网络(VGG)
VGG:通过重复使⽤简单的基础块来构建深度模型。
Block:数个相同的填充为1、窗口形状为 3×3 的卷积层,接上一个步幅为2、窗口形状为 2×2 的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半。
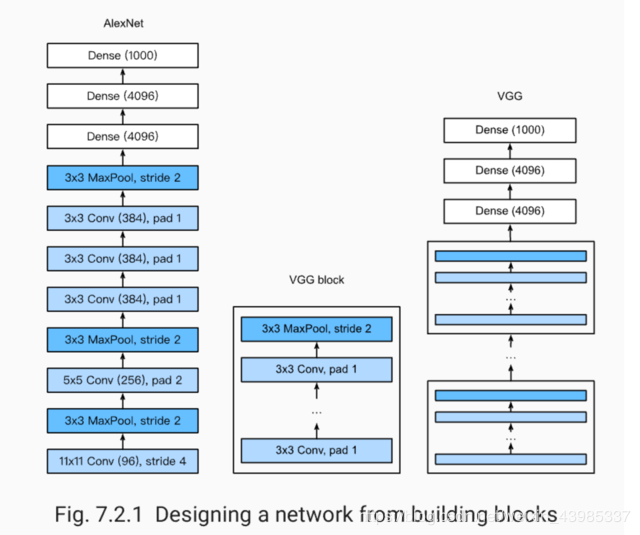
VGG11的简单实现
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
net = vgg(conv_arch, fc_features, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
vgg_block_1 output shape: torch.Size([1, 64, 112, 112])
vgg_block_2 output shape: torch.Size([1, 128, 56, 56])
vgg_block_3 output shape: torch.Size([1, 256, 28, 28])
vgg_block_4 output shape: torch.Size([1, 512, 14, 14])
vgg_block_5 output shape: torch.Size([1, 512, 7, 7])
fc output shape: torch.Size([1, 10])
ratio = 8
small_conv_arch = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio), (2, 128//ratio, 256//ratio),
(2, 256//ratio, 512//ratio), (2, 512//ratio, 512//ratio)]
net = vgg(small_conv_arch, fc_features // ratio, fc_hidden_units // ratio)
print(net)
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
batchsize=16
#batch_size = 64
# 如出现“out of memory”的报错信息,可减小batch_size或resize
# train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
⽹络中的⽹络(NiN)
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取 空间特征,再以由全连接层构成的模块来输出分类结果。
NiN:串联多个由卷积层和“全连接”层构成的小⽹络来构建⼀个深层⽹络。
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。
1×1卷积核作用
1.放缩通道数:通过控制卷积核的数量达到通道数的放缩。
2.增加非线性。1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
3.计算参数少
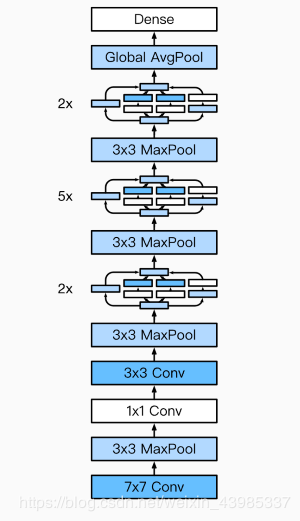
GoogLeNet
GoogLeNet模型
完整模型结构
作者:周周儿_zHoU