AI03过拟合欠拟合;梯度消失、梯度爆炸;卷积神经网络基础
训练误差:模型在训练数据集上表现出的误差
泛化误差:模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。
机器学习模型应关注降低泛化误差。
预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取一小部分作为验证集,而将剩余部分作为真正的训练集。
K折交叉验证把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
过拟合和欠拟合欠拟合(underfitting):模型无法得到较低的训练误差
过拟合(overfitting):模型的训练误差远小于它在测试数据集上的误差
两个因素:模型复杂度和训练数据集大小。
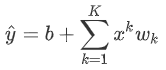
给定训练数据集,模型复杂度和误差之间的关系:
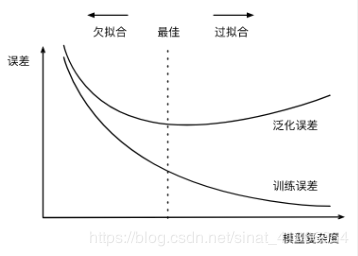
一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
课后练习 测试数据集不可以用来调整模型参数,如果使用测试数据集调整模型参数,可能在测试数据集上发生一定程度的过拟合,此时将不能用测试误差来近似泛化误差。 过拟合是指训练误差达到一个较低的水平,而泛化误差依然较大。欠拟合是指训练误差和泛化误差都不能达到一个较低的水平。
发生欠拟合的时候在训练集上训练误差不能达到一个比较低的水平,所以过拟合和欠拟合不可能同时发生。 梯度消失、梯度爆炸以及Kaggle房价预测 梯度消失和梯度爆炸
深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。
当神经网络的层数较多时,模型的数值稳定性容易变差。
PyTorch的默认随机初始化:
随机初始化模型参数的方法有很多。在线性回归的简洁实现中,我们使用torch.nn.init.normal_()使模型net的权重参数采用正态分布的随机初始化方式。不过,PyTorch中nn.Module的模块参数都采取了较为合理的初始化策略
Xavier随机初始化:
假设某全连接层的输入个数为 a ,输出个数为 b ,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布,它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。
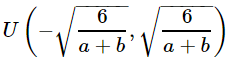
虽然输入的分布可能随时间而改变,但是标记函数,即条件分布P(y∣x)不会改变。
eg:我们的训练数据使用的是猫和狗的真实的照片,但是在测试时,我们被要求对猫和狗的卡通图片进行分类。
当我们认为导致偏移的是标签P(y)上的边缘分布的变化,但类条件分布是不变的P(x∣y)时,就会出现相反的问题。当我们认为y导致x时,标签偏移是一个合理的假设。例如,通常我们希望根据其表现来预测诊断结果。
概念偏移标签本身的定义发生变化。
课后练习 在激活函数的选择的地方讲过,在深层网络中尽量避免选择sigmoid和tanh激活函数,原因是这两个激活函数会把元素转换到[0, 1]和[-1, 1]之间,会加剧梯度消失的现象。 一个在冬季部署的物品推荐系统在夏季的物品推荐列表中出现了圣诞礼物,我们可以推断该系统没有考虑到:协变量偏移解释:可以理解为在夏季的物品推荐系统与冬季相比,时间或者说季节发生了变化,导致了夏季推荐圣诞礼物的不合理的现象,这个现象是由于协变量时间发生了变化造成的。 模型训练实战顺序:
获取数据集
数据预处理
模型设计
模型验证和模型调整(调参)
模型预测及提交 如果数据量足够的情况下,确保训练数据集和测试集中的数据取自同一个数据集,可以防止协变量偏移和标签偏移是正确的。如果数据量很少,少到测试集中存在训练集中未包含的标签,就会发生标签偏移。 卷积神经网络基础
卷积层和池化层,填充、步幅、输入通道和输出通道。
二维卷积层本节介绍最常见的二维卷积层,常用于处理图像数据
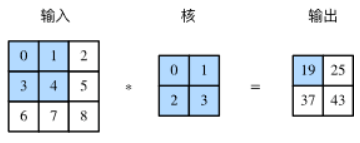
二维互相关运算二维互相关(cross-correlation)运算的输入是一个二维输入数组和一个二维核(kernel)数组,输出也是一个二维数组,其中核数组通常称为卷积核或过滤器(filter)。卷积核的尺寸通常小于输入数组,卷积核在输入数组上滑动
import torch
import torch.nn as nn
def corr2d(X, K):
H, W = X.shape
h, w = K.shape
Y = torch.zeros(H - h + 1, W - w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
构造上图中的输入数组X、核数组K来验证二维互相关运算的输出。
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
K = torch.tensor([[0, 1], [2, 3]])
Y = corr2d(X, K)
print(Y)
二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏置来得到输出。卷积层的模型参数包括卷积核和标量偏置。
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
下面我们看一个例子,我们构造一张 6×8 的图像,中间4列为黑(0),其余为白(1),希望检测到颜色边缘。我们的标签是一个 6×7 的二维数组,第2列是1(从1到0的边缘),第6列是-1(从0到1的边缘)。
X = torch.ones(6, 8)
Y = torch.zeros(6, 7)
X[:, 2: 6] = 0
Y[:, 1] = 1
Y[:, 5] = -1
print(X)
print(Y)
我们希望学习一个 1×2 卷积层,通过卷积层来检测颜色边缘。
conv2d = Conv2D(kernel_size=(1, 2))
step = 30
lr = 0.01
for i in range(step):
Y_hat = conv2d(X)
l = ((Y_hat - Y) ** 2).sum()
l.backward()
# 梯度下降
conv2d.weight.data -= lr * conv2d.weight.grad
conv2d.bias.data -= lr * conv2d.bias.grad
# 梯度清零
conv2d.weight.grad.zero_()
conv2d.bias.grad.zero_()
if (i + 1) % 5 == 0:
print('Step %d, loss %.3f' % (i + 1, l.item()))
print(conv2d.weight.data)
print(conv2d.bias.data)
Step 5, loss 4.569
Step 10, loss 0.949
Step 15, loss 0.228
Step 20, loss 0.060
Step 25, loss 0.016
Step 30, loss 0.004
tensor([[ 1.0161, -1.0177]])
tensor([0.0009])
互相关运算与卷积运算
卷积运算,反映了事物的相互作用,并且这种相互作用受制于同一个影响因子。
相关运算,在于反应已有事物的内在关联,并不是事物之间的相互影响。
卷积层得名于卷积运算,但卷积层中用到的并非卷积运算而是互相关运算。我们将核数组上下翻转、左右翻转,再与输入数组做互相关运算,这一过程就是卷积运算。由于卷积层的核数组是可学习的,所以使用互相关运算与使用卷积运算并无本质区别。
二维卷积层输出的二维数组可以看作是输入在空间维度(宽和高)上某一级的表征,也叫特征图(feature map)。影响元素 x 的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做 x 的感受野(receptive field)。
仍以上图为例,输入中阴影部分的四个元素是输出中阴影部分元素的感受野。我们将图中形状为 2×2 的输出记为 Y ,将 Y 与另一个形状为 2×2 的核数组做互相关运算,输出单个元素 z 。那么, z 在 Y 上的感受野包括 Y 的全部四个元素,在输入上的感受野包括其中全部9个元素。可见,我们可以通过更深的卷积神经网络使特征图中单个元素的感受野变得更加广阔,从而捕捉输入上更大尺寸的特征。
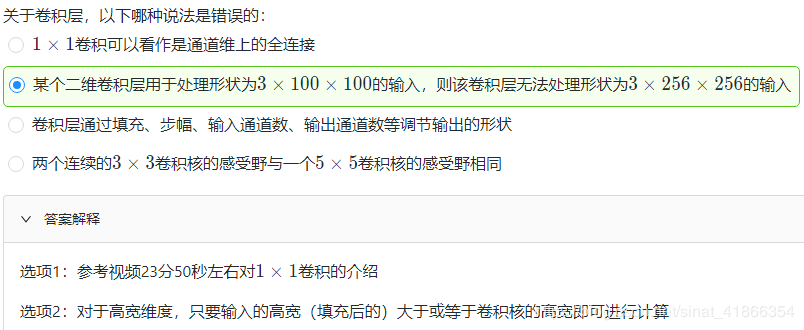
卷积层的两个超参数,即填充和步幅,它们可以对给定形状的输入和卷积核改变输出形状。
填充填充(padding)是指在输入高和宽的两侧填充元素(通常是0元素)
我们在卷积神经网络中使用奇数高宽的核,比如 3×3 , 5×5 的卷积核,对于高度(或宽度)为大小为 2k+1 的核,令步幅为1,在高(或宽)两侧选择大小为 k 的填充,便可保持输入与输出尺寸相同。
在互相关运算中,卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)
多输入通道和多输出通道之前的输入和输出都是二维数组,但真实数据的维度经常更高。例如,彩色图像在高和宽2个维度外还有RGB(红、绿、蓝)3个颜色通道。假设彩色图像的高和宽分别是 h 和 w (像素),那么它可以表示为一个 3×h×w 的多维数组,我们将大小为3的这一维称为通道(channel)维。
多输入通道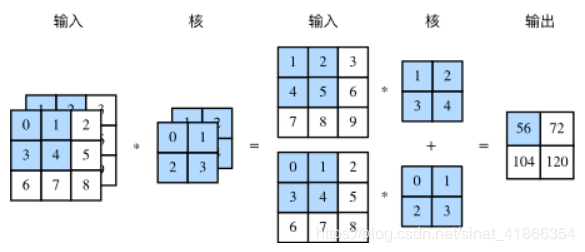
二维卷积层经常用于处理图像,与此前的全连接层相比,它主要有两个优势:
一是全连接层把图像展平成一个向量,在输入图像上相邻的元素可能因为展平操作不再相邻,网络难以捕捉局部信息。而卷积层的设计,天然地具有提取局部信息的能力。
二是卷积层的参数量更少。不考虑偏置的情况下,一个形状为 (ci,co,h,w) 的卷积核的参数量是 ci×co×h×w ,与输入图像的宽高无关。假如一个卷积层的输入和输出形状分别是 (c1,h1,w1) 和 (c2,h2,w2) ,如果要用全连接层进行连接,参数数量就是 c1×c2×h1×w1×h2×w2 。使用卷积层可以以较少的参数数量来处理更大的图像。
使用Pytorch中的nn.Conv2d类来实现二维卷积层
X = torch.rand(4, 2, 3, 5)
print(X.shape)
conv2d = nn.Conv2d(in_channels=2, out_channels=3, kernel_size=(3, 5), stride=1, padding=(1, 2))
Y = conv2d(X)
print('Y.shape: ', Y.shape)
print('weight.shape: ', conv2d.weight.shape)
print('bias.shape: ', conv2d.bias.shape)
torch.Size([4, 2, 3, 5])
Y.shape: torch.Size([4, 3, 3, 5])
weight.shape: torch.Size([3, 2, 3, 5])
bias.shape: torch.Size([3])
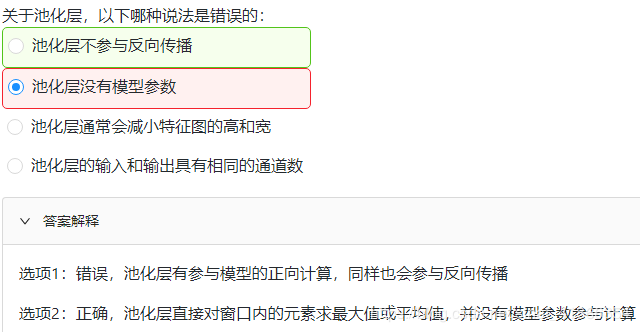
池化
池化层主要用于缓解卷积层对位置的过度敏感性。同卷积层一样,池化层每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算输出,池化层直接计算池化窗口内元素的最大值或者平均值,该运算也分别叫做最大池化或平均池化。如下图展示了池化窗口形状为 2×2 的最大池化。
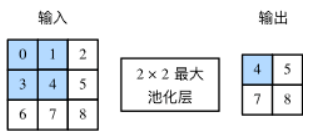
在处理多通道输入数据时,池化层对每个输入通道分别池化,但不会像卷积层那样将各通道的结果按通道相加。这意味着池化层的输出通道数与输入通道数相等。
使用Pytorch中的nn.MaxPool2d实现最大池化层
平均池化层使用的是nn.AvgPool2d,使用方法与nn.MaxPool2d相同。
X = torch.arange(32, dtype=torch.float32).view(1, 2, 4, 4)
pool2d = nn.MaxPool2d(kernel_size=3, padding=1, stride=(2, 1))
Y = pool2d(X)
print(X)
print(Y)
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[16., 17., 18., 19.],
[20., 21., 22., 23.],
[24., 25., 26., 27.],
[28., 29., 30., 31.]]]])
tensor([[[[ 5., 6., 7., 7.],
[13., 14., 15., 15.]],
[[21., 22., 23., 23.],
[29., 30., 31., 31.]]]])
课后练习
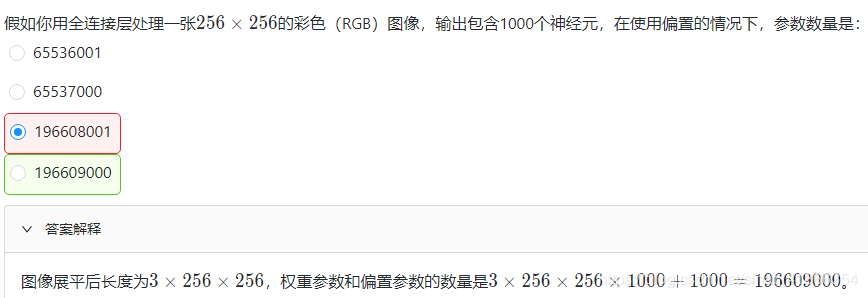
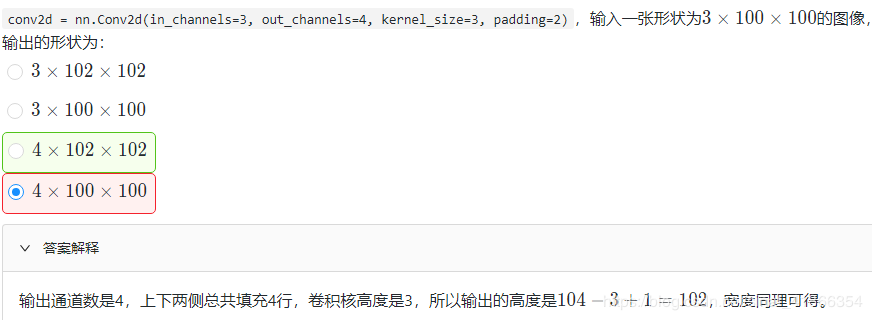
作者:fassbloom