手把手教学Android用jsoup解析html实例
1.jsoup介绍
很多时候,我们需要从各种网页上面抓取数据,而jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup官方文档:https://jsoup.org/cookbook/
2.使用场景
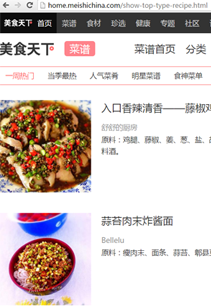
下面是一张关于美食的截图,可以留意到这是一个html网页,当我们想要抓取里面的数据的时候,jsoup就能帮到我们很多。
接下来开始手把手教学
首先,也是很重要的一步,就是下载jar包,丢到libs里面
jar包下载地址:http://jsoup.org/download
Android studio玩家可以不下载jar包,在Gradle里面加入
dependencies {
compile 'org.jsoup:jsoup:1.9.2'
}
然后,找到你心仪的网页去抓取数据
这里我们我继续使用美食的网页,然后右键查看网页源码,或者按F12,接下来可以看到一大堆标签:

找到需要的,例如上图这个 “美食天下” ,可以看到 “美食天下” 是放在以 <div class="top-bar" id="J_top_bar"> 为节点的 <a title="美食天下" 中,要获取这个“美食天下”,代码可以这样写:
try {
//从一个URL加载一个Document对象。
Document doc = Jsoup.connect("http://home.meishichina.com/show-top-type-recipe.html").get();
//选择“美食天下”所在节点
Elements elements = doc.select("div.top-bar");
//打印 <a>标签里面的title
Log.i("mytag",elements.select("a").attr("title"));
}catch(Exception e) {
Log.i("mytag", e.toString());
}
接下来看一下打印出来的结果:
![]()
Jsoup.connect(String url)方法从一个URL加载一个Document对象。如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理。
一旦拥有了一个Document,你就可以使用Document中适当的方法或它父类 Element和Node中的方法来取得相关数据。
public class Element extends Node
public class Document extends Element
很多文章都是说一大堆原理然后放出一个简单的例子,就跟我上面简单的打了一个log一样,然后发现用起来的时候是没那么简单的。为了大家能不看文档也可以直接使用(并且看不懂那一大堆标签也可以用),我决定再举一个例子(其实也就是比上面多打几个log):
下图红色框框是我们要获取的数据,可以看到他们对应的节点就是蓝色圆圈里面的<div class="xxx">

废话不多说上代码
try {
//还是一样先从一个URL加载一个Document对象。
Document doc = Jsoup.connect("http://home.meishichina.com/show-top-type-recipe.html").get();
//“椒麻鸡”和它对应的图片都在<div class="pic">中
Elements titleAndPic = doc.select("div.pic");
//使用Element.select(String selector)查找元素,使用Node.attr(String key)方法取得一个属性的值
Log.i("mytag", "title:" + titleAndPic.get(1).select("a").attr("title") + "pic:" + titleAndPic.get(1).select("a").select("img").attr("data-src"));
//所需链接在<div class="detail">中的<a>标签里面
Elements url = doc.select("div.detail").select("a");
Log.i("mytag", "url:" + url.get(i).attr("href"));
//原料在<p class="subcontent">中
Elements burden = doc.select("p.subcontent");
//对于一个元素中的文本,可以使用Element.text()方法
Log.i("mytag", "burden:" + burden.get(1).text());
}catch(Exception e) {
Log.i("mytag", e.toString());
}
大功告成,接下来看看log

没有问题!那么教学可以结束了!
注意:
Jsoup.connect(String url)方法不能运行在主线程,否则会报NetworkOnMainThreadException
最后上一张应用在项目的效果图:
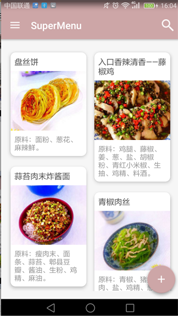
有没有发现熟悉的椒麻鸡?很酷炫有木有!
小结
整堂课分几步:
1.下载jar包并丢到libs(或者在gradle)
2.找到心仪的网页
3.用Jsoup.connect()获取网页的document
4.查看网页源码,对准你想要的地方,给他来一个Element.select(String selector)
5.用Node.attr(String key)或者Element.text()方法把数据抽出来
6.没有6了就是这么简单!