软件开发搞定计算机组成原理:组成篇
提供了对外连接的接口,也促使外部设备接口的统一。比如USB(Universal Serial Bus,通用串行总线)接口,使得 不同设备可以通过USB接口进行连接。

假设没有总线的计算机,当连接上外部设备时,如下图,线路会变得更加复杂。

当有了总线后:
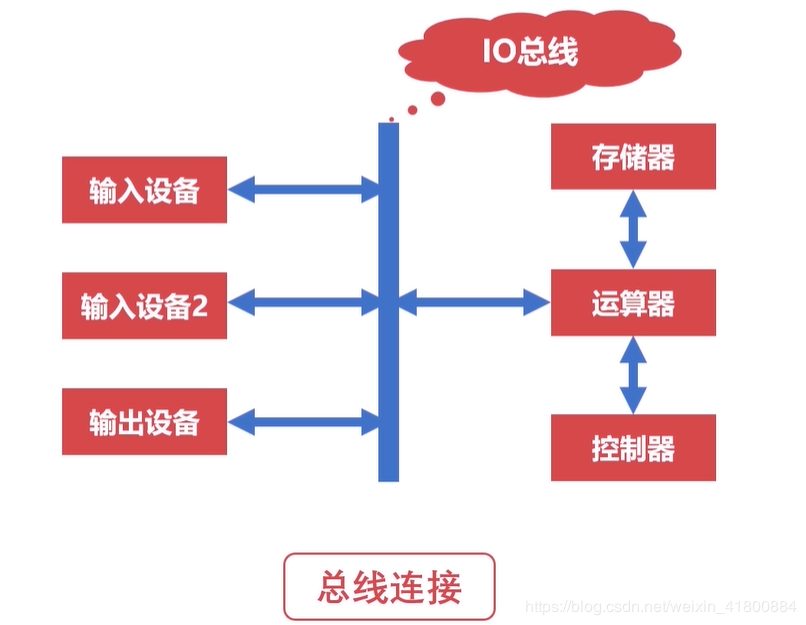
可分为片内总线和系统总线。
片内总线:芯片内部的总线,连接寄存器与寄存器,连接寄存器与控制器、运算器。比如CPU的内部。
2. 系统总线:是连接CPU、主内存、IO设备、各组件之间的信息传输线。

系统总线还可以分为三类:
数据总线:双向传输各个部件的数据信息。数据总线的位数(总线宽度)是数据总线的重要参数,一般与CPU的位数相同(32位,64位)。 地址总线:指定源数据或目的数据在内存中的地址。地址总线的位数与存储单位有关,如果地址总线的位数位n,则寻找范围为:0~2^n。 控制总线:是用来发出各种控制信号的传输线,它可以监视不同组件之间的状态(就绪/未绪)。控制信号经由控制总线从一个组件发送给另一个组件。 1.3 总线仲裁假设主存要跟硬盘和IO设备交换数据,当硬盘和IO设备都处于就绪状态,此时的总线是要给硬盘使用呢?还是给IO设备使用?机器不知道,所以会造成冲突,类似线程中的死锁。所以需要仲裁器。
仲裁器:为了解决不同设备使用总线的优先顺序,或者说解决不同设备对总线使用权的问题。
1.4 总线冲裁的方法一共有3种方法:链式查询、计时器定时查询、独立请求。
链式查询:如图,3个设备连接总线并且连接一个仲裁控制器。假设设备2需要使用总线,那么会先发出信号,经由仲裁控制线到达仲裁控制器。仲裁控制器就会发出允许使用的信号,但该信号是首先通过设备1,检查设备1是否需要使用,不需要使用才到设备2。所以设备1总是比设备2有更高的优先使用权,即使不使用也会先去问它要不要用,可以想象同时使用设备1和设备2,但想要设备2的优先级高点是不可能的。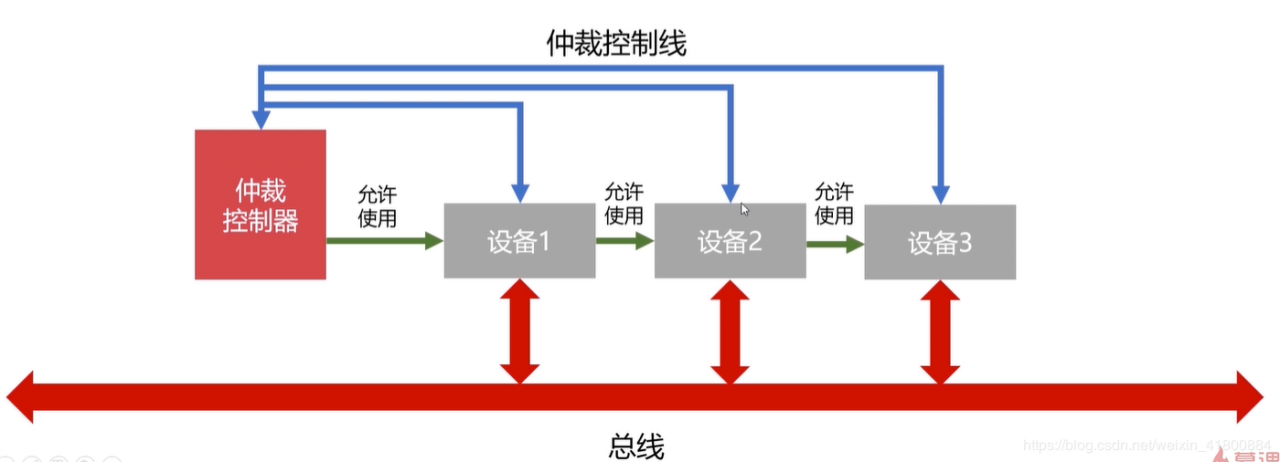
优点:电路复杂度低,仲裁方式简单。
缺点:优先级低的设备难以获得总线使用权,而且对电路故障敏感(一处坏了,其他设备都不能用了)。
计时器定时查询:仲裁控制器对设备编号并使用计数器累计计数,首先接收到仲裁信号后,往所有的设备发出计数值,然后一直增大计数值(要使用的),当计数值与设备编号一致,检查是否是该设备发出的信号,如果是则获得总线使用权。 当计数值到达最大编号时重新从0开始。刚开始计数器的值可以是从0开始,也可以是从上一次中止的编号开始(这称为循环优先级,使得每个设备获得使用权的机会都相同),还可以通过程序设置计数值(了解)。
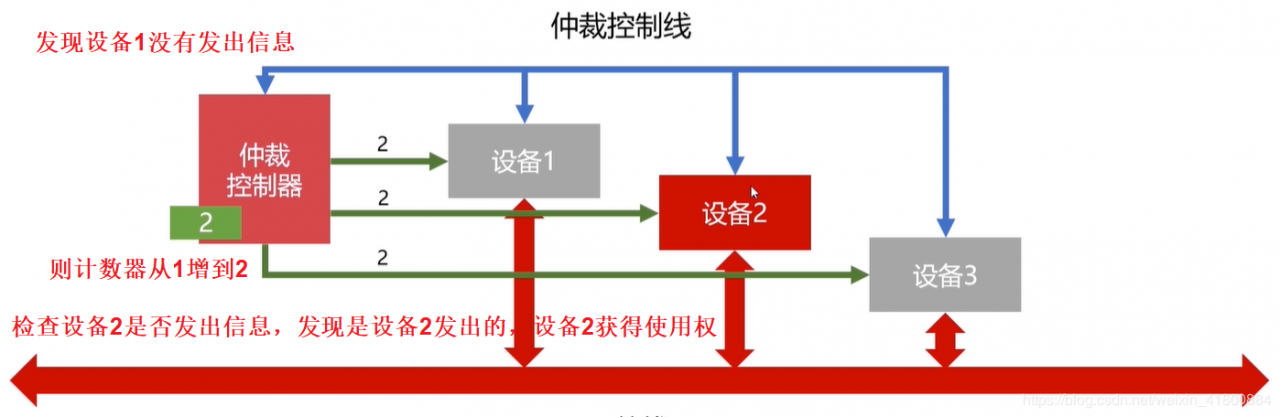
好处:相比链式查询,计时器定时查询不会因为某故障导致其他设备不能用,即对电路不敏感,可靠性高。
坏处:电路也比较复杂了,速度也不快(因为计数器和设备数量的原因)。
独立请求:每个设备均有总线独立连接仲裁器,所以设备可单独向仲裁器发送请求和接收请求。当同时收到多个信号时,使用权冲突问题主要是由仲裁器解决的”解释权归仲裁器所有“,可以按照时间先后,也可以按照优先级分配等的方法去解决。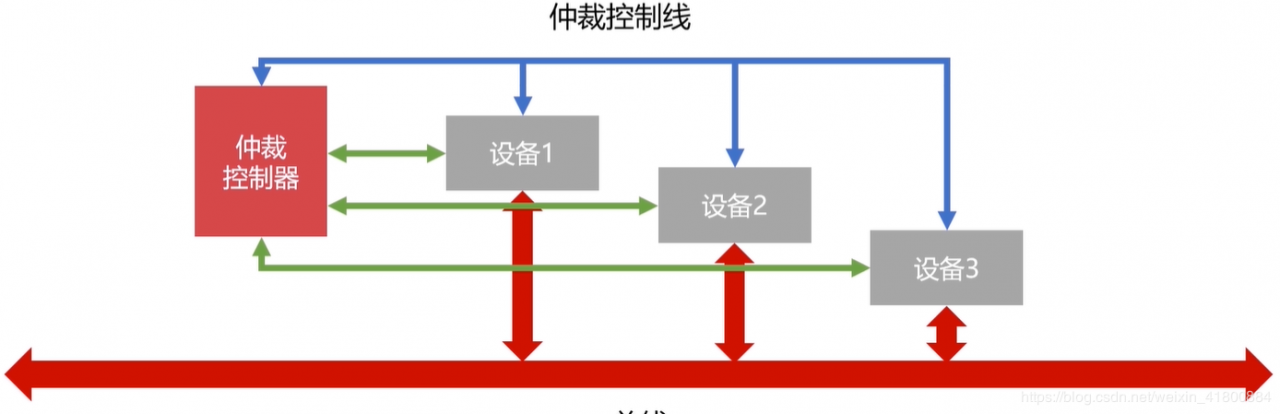
好处:响应速度快,优先顺序可动态变动。
坏处:设备连接多,总线控制复杂。
2. 输入输出设备 2.1 常见的输入设备可分为两种:字符输入设备和图形输入设备。
字符输入设备:键盘(薄膜键盘,机械键盘,电容键盘)

图形输入设备:鼠标,数位板,扫描仪。

比如显示器,打印机,投影仪。

额外的:硬盘即属于输入设备,又属于输出设备。
2.3 主机与IO设备的接口 数据线:是IO设备与主机之间进行数据交换的传送线。即可单向传输也可双向传输。 状态线:IO设备状态向主机报告的信号线。为了查询设备是否已经正常连接并就绪、也可以查询设备是否已经被占用。 命令线:CPU向设备发送命令的信号线。可发送读写信号和启动停止信号。 设备选择线:主机选择IO设备进行操作的信号线。对连在总线上的设备进行选择。 2.4 CPU与IO设备通信CPU的速度与IO设备的速度不一致,所以需要下面的方法。
2.4.1 程序中断当外部IO设备就绪时,向CPU发出中断信号,然后CPU就会停止当前执行的主程序,转去处理IO设备。待IO设备处理完,就会返回刚刚中断的位置,继续执行刚刚的主程序。
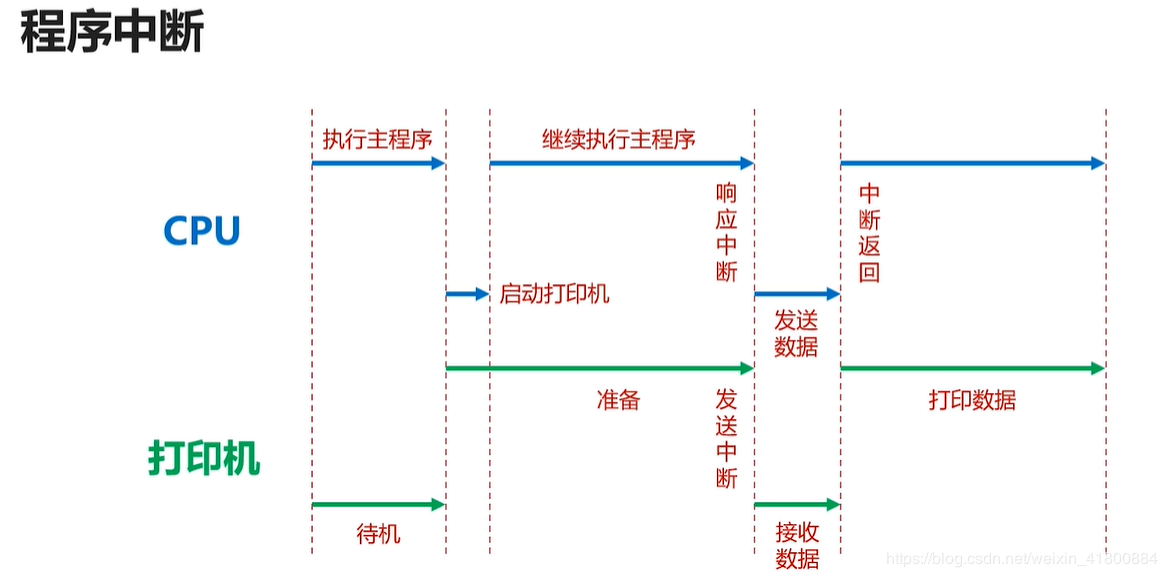
作用:提供低速设备通知CPU的一种异步方式,CPU可以高速运转同时兼顾低速设备的响应。
2.4.2 DMA(直接存储器访问)因为程序中断会降低CPU的使用效率,所以提供DMA设备,一般存在在硬盘、外置显卡中。
DMA直接连接主存与IO设备,当DMA工作时不需要CPU的参与。

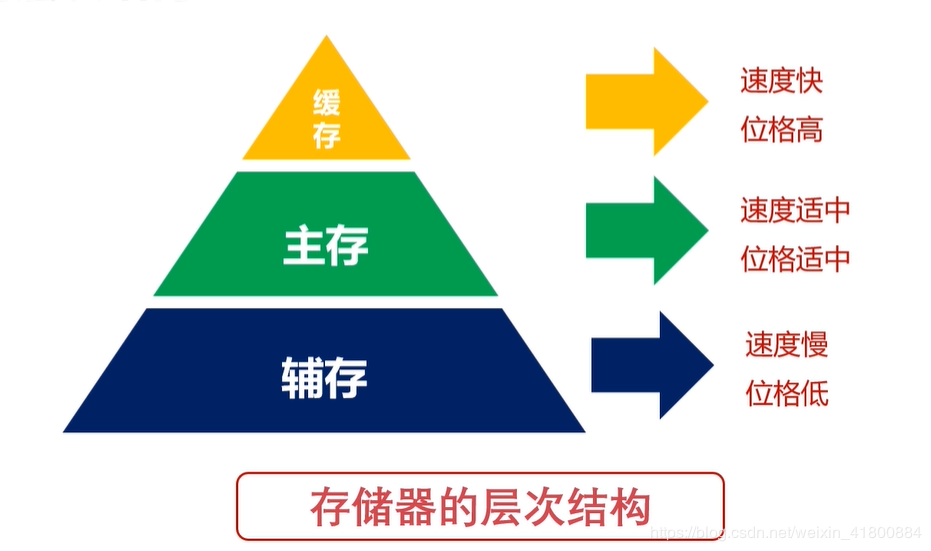
如图:
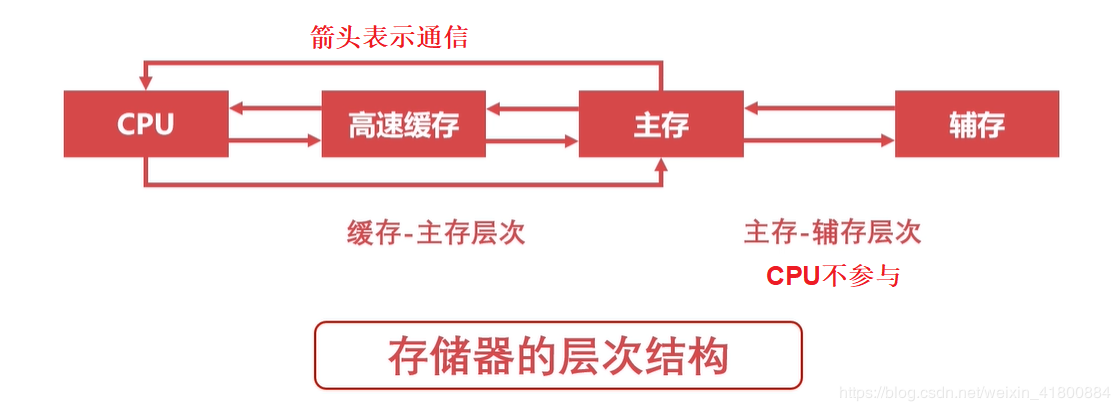
缓存:CPU中的寄存器、高速缓存(现在焊接在CPU中,里面有一级缓存L1、二级缓存L2、三级缓存L3,不信可以打开任务管理器,点击性能,点击CPU,就可以看到L1、L2、L3)。 主存:计算机中的内存。我们常说的内存条(DRAM,动态随机存取存储器)。 辅存:计算机的外部存储设备,比如U盘,磁盘,移动硬盘。也可以按下面的图来表示层次结构,其主要思想是:存储器层次结构的思想是上一层次的存储器是低一层次的高速缓存。 比如一级缓存是二级缓存的高速缓存,二级缓存是三级缓存的高速缓存,三级缓存是主存的高速缓存,主存是辅存的高速缓存。因为辅存的速度是最慢的,所以我们要避免CPU访问辅存取数据,所以交给主存利用DMA去跟辅存打交道(搬运数据到内存),需要什么数据还是得由CPU来控制。
局部性原理:可分为时间局部性、空间局部性、顺序(算法)局部性。百度百科
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。(比如程序循环、堆栈等) 顺序局部性(Order Locality):在典型程序中,除转移类指令外,大部分指令是顺序进行的。(比如指令的顺序执行、数组的连续存放) 空间局部性(Spatial Locality):结合顺序局部性,在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的,也称为预存。所以有了局部性原理,保证了CPU能高速工作,当我们第一次打开某个程序时,可能会比较慢,过一段时间第二次重新打开时(不是关机重启),发现变快了。因为第一次的时候,程序的相关链接库没有加载进内存,需要从磁盘读取,所以慢,第二次打开因为链接库在内存里面(内存也属于经常访问的),所以快。这里的打开慢,我们只考虑链接库,因为打开慢的原因可能有很多(比如CPU正在忙,内存不够等),而且对于一台牛逼的电脑(高级的CPU, 固态硬盘,内存条等)第一次打开可能感受不到慢。
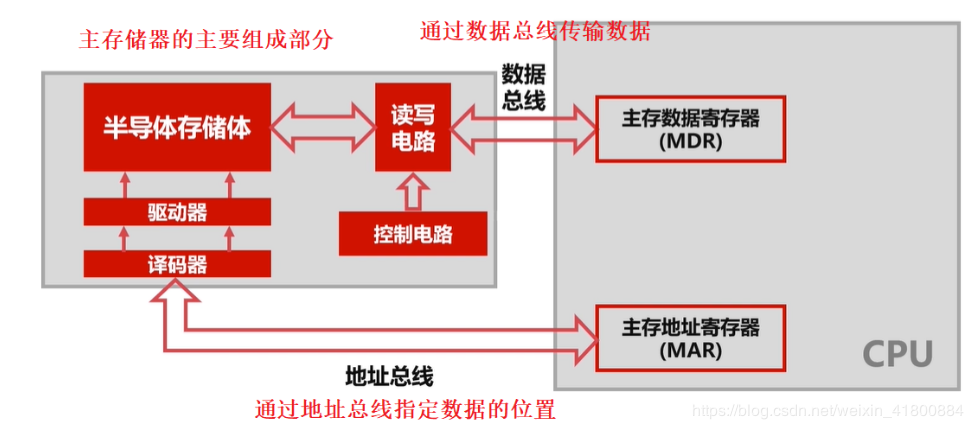
3.3 主存储器
主存储器也就是我们的内存条,英文名为:RAM(随机存取存储器,Random Access Memory),更准确的说应该称为:DRAM(动态随机存取存储器)。DRAM通过电容存储数据,必须隔一段时间刷新一次,所以一旦掉电(漏电),那么一段时间内后将丢失数据。
DRAM(动态随机存取存储器):每个存储单元所需的场效应管较少,常见的有4管,3管和单管型DRAM。因此它的集成度较高,功耗也较低,但缺点是保存在DRAM中的信息不是永久的,如果掉电,那么一段时间后将丢失数据。
SRAM(静态随机存取存储器):工作速度快,只要电源不撤除,写入SRAM的信息就不会消失,不需要刷新电路,同时在读出时不破坏原来存放的信息,一经写入可多次读出,但集成度较低,功耗较大。一般作为高速缓冲存储器(Cache)。
主要区别DRAM需要刷新地储存数据,SRAM不需要刷新地储存数据;相同的是一旦关机或断电,DRAM和SRAM数据都没有了。
对于不同位数的系统对内存容量的支持是不一样的:
32位的系统:实际最大只能支持:2^32B = 4 * 2^30B = 4GB 64位的系统:这里是理论上最大能支持:2^64B = 2^24 * 2^30 * 2^30B = 16777216TB。win10家庭版64位可以最大可支持128GB,win10的其他64位版(Pro,Enterprise等)最大可支持2T的内存。像我的笔记本只能最多加到32G,台式可以更高。电脑的最大内存容量不仅仅看系统,还得看主板的内存卡槽和CPU支持的内存频速(DDR4 2666、DDR4 3200等)等(了解就行反正我不是专业配电脑的)。小技巧:打开CMD,输入:wmic memphysical get maxcapacity
出现一个数字,该数字的单位为KB,需要除两次1024得出电脑可以支持的最大内存容量。
用其他软件也可以看。
3.4 辅助存储器这里只谈磁盘。断电后数据还会保持在磁盘中。
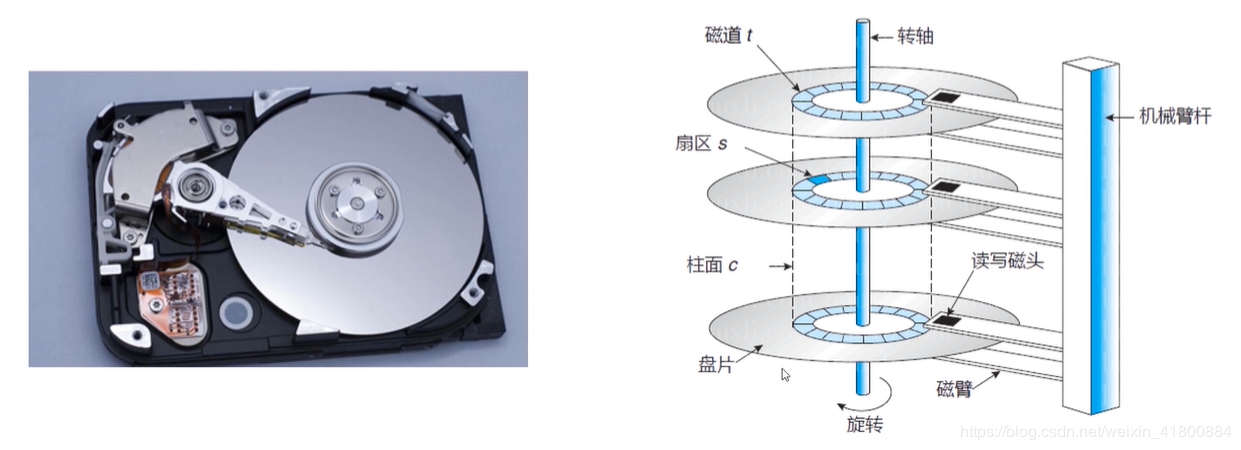
磁臂控制磁头在磁道上移动,磁头读写数据。
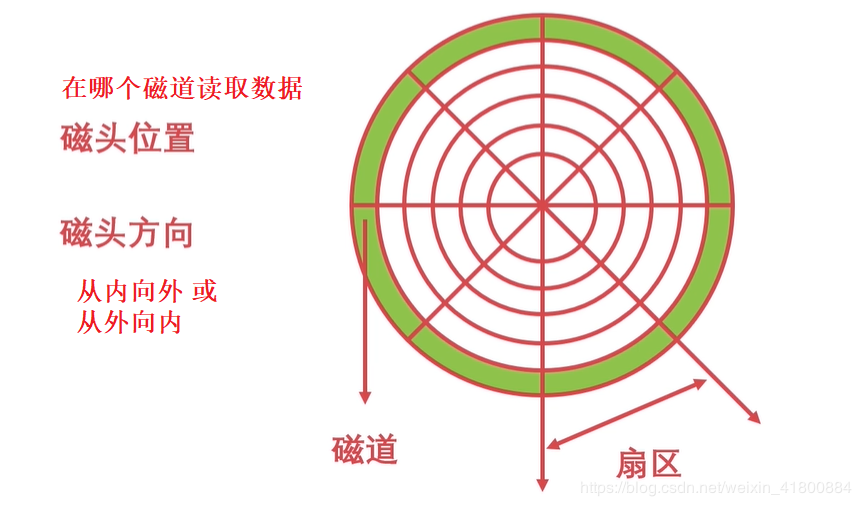
磁盘的调度算法:(操作系统的重要内容)
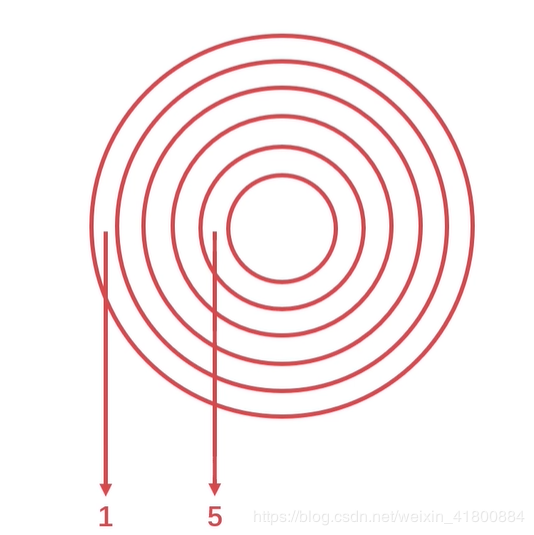
先来先服务算法:根据进程对磁道的请求序列(读取磁道)移动磁头。简单,公平,但效率不高,可能移动的磁头一会最外一会最内,增加了服务时间,对机械也不利。 最短寻道时间算法:根据进程对磁道的请求序列,每次移动到离它当前磁头位置最近的磁道。性能比“先来先服务”好,但是会造成饥饿的现象(某些访问请求长期等待得不到服务。)。 扫描算法(电梯算法):根据进程对磁道的请求序列和当前磁道方向,从当前磁道方向开始移动,到最外圈或最内圈后,再从刚刚初始磁道位置移动到最内圈或最外圈。( 最外圈最内圈 )。寻道性能较好,可避免“饥饿”现象,但是不利于远离磁头一端的访问请求。 循环扫描算法:跟扫描算法不同的是:从当前磁道方向开始移动,到最外圈或最内圈后,再从相反方向移动到初始位置。( 最内圈<-最外圈最内圈->最外圈 类似一个环)相比于扫描算法,循环扫描算法消除了对两端磁道请求的不公平。举个例子理解:假设现在磁头在磁道3,磁头方向向外,磁道有1到5。现在读取磁道的序列:1 4 2 3 1 5
理解完,来一道标准问题试试:因为typora的表格功能不能合并单元格所以截图吧。

思考再看答案:
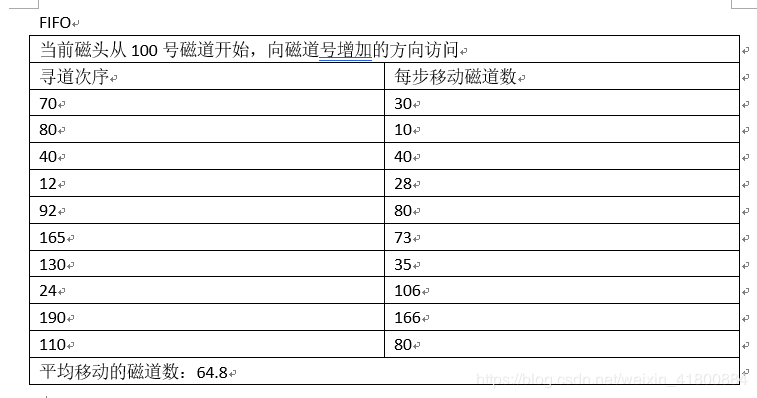
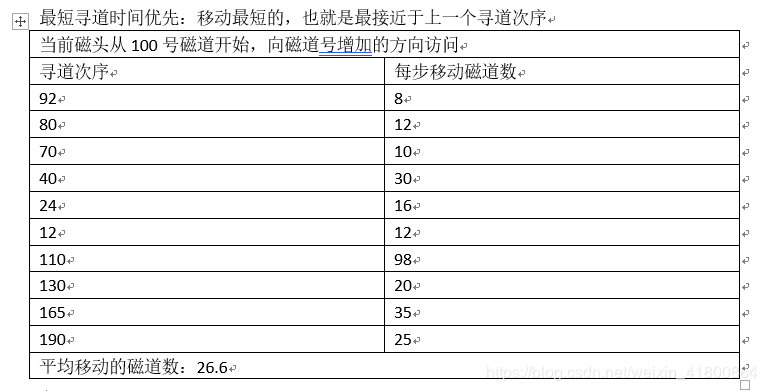


先了解主存的一些概念:
字:是指放在一个存储单元中的二进制代码组合。一个字可表示一个指令/一个数据/一个字符串。一个字中的二进制位的位数称为字长,字长可以是8位、16位、32位等。 字块:存储在连续的存储单元中而被看作是一个单元的一组字。就是一个块包含几个字。
那么如何寻址:通过字的地址。
字的地址包含两部分:
前m位指定字块的地址 后b位指定字在字块中的地址
跟主存有这样的关系:
2m=M
2^m=M
2m=M
2b=B 2^b = B 2b=B
例子:

答案:
4G=4096M
4G = 4096M
4G=4096M
字块数:4096/4=1024 字块数:4096 / 4 = 1024 字块数:4096/4=1024
字块地址m:log21024=10 字块地址m:log_21024=10 字块地址m:log21024=10
块内字数:4M/32bit=1048576 块内字数:4M/32bit = 1048576 块内字数:4M/32bit=1048576
块内地址b:log21048576=20 块内地址b:log_21048576 = 20 块内地址b:log21048576=20
结果:m>=10;b>=20 结果:m >= 10; b >= 20 结果:m>=10;b>=20
了解了主存的字和字块,来到高速缓存中也有跟上面一样的概念,运算都是一样的。但是主存的容量远大于高速缓存的容量,而且缓存中存储的数据其实来自于主存中的数据。
因为CPU需要的数据如果在缓存中那么工作效率高,如果需要的数据不在缓存中,则需要去主存拿,但我们不希望让CPU去主存拿,而是让缓存去拿,所以需要一个指标来表明CPU从高速缓存中取得需要的数据成功的几率,称为命中率。
高速缓存的工作原理:使用命中率来衡量缓存的性能指标。理论上CPU每次都能从高速缓存中存取数据的时候,命中率为1(100%)。但是我们知道高速缓存的容量远小于主存容量,所以永远不可能为1。因此使用两个参数:访问主存次数和访问Cache次数来计算命中率。

除了命中率,还有一个指标也可以来衡量缓存的性能:访问效率。以下是运算:

例子:

答:
命中率:h=NcNc+Nm=20002000+50=0.97
命中率:h = \frac{N_c}{N_c + N_m} = \frac{2000}{2000 + 50} = 0.97
命中率:h=Nc+NmNc=2000+502000=0.97
访问效率:e=tch∗tc+(1−h)∗tm=500.97∗50+(1−0.97)∗200=0.917=91.7% 访问效率:e = \frac{t_c}{h*t_c + (1-h)*t_m} = \frac{50}{0.97*50 + (1-0.97)*200} = 0.917 = 91.7\% 访问效率:e=h∗tc+(1−h)∗tmtc=0.97∗50+(1−0.97)∗20050=0.917=91.7%
平均访问时间:平均访问时间:ta=h∗tc+(1−h)∗tm=0.97∗50+(1−0.97)∗200=54.5ns 平均访问时间:平均访问时间:t_a = h*t_c + (1-h)*t_m = 0.97*50 + (1-0.97)*200 = 54.5ns 平均访问时间:平均访问时间:ta=h∗tc+(1−h)∗tm=0.97∗50+(1−0.97)∗200=54.5ns
为了让命中率高些,也就是让CPU每次能在缓存中取得数据的成功率高点,所以需要性能良好的高速缓存替换策略,使得高速缓存中的数据都是CPU需要的数据。
高速缓存替换策略的触发时机:当CPU所需要的数据不在高速缓存中,此时就触发置换策略,这时高速缓存就会去主存把需要的数据加入道高速缓存中,可能也会把高速缓存不需要数据置换掉。
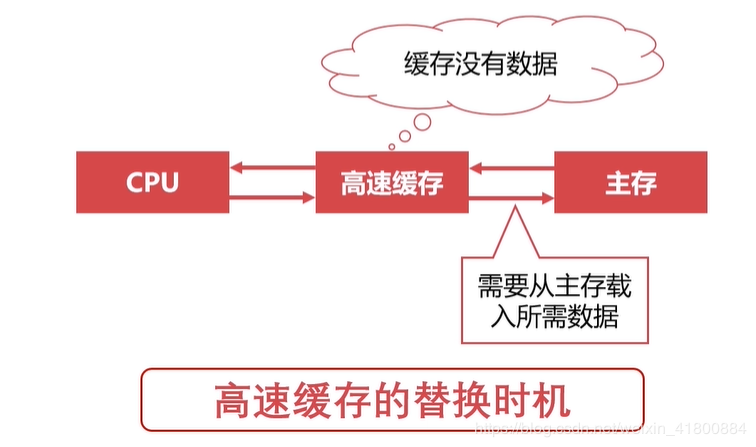
高速缓存替换策略有几种:(也就是算法)
随机算法:每一次需要替换时,随机选取高速缓存中的位置,把该位置的数据替换道需要的数据即可。速度快,但效率低。 先进先出算法(FIFO):顾名思义,类似队列,优先移除最先进入队列的字块,后来的再添加到队尾。 最不经常使用算法(LFU):优先淘汰(移除)掉最不经常使用的字块。所以需要额外的空间来记录字块的访问次数。 最近最少使用算法(LRU):优先淘汰一段时间内没有使用的字块,有多种实现方法,一般使用双向链表。每次使用的字块都会被拉到链表前(保证链表头是最近使用的),太久没使用的最终会被放到最后,然后当链表满了要添加数据时就会把链表尾的淘汰掉。图解算法:
随机算法就不说了,我也不知道它随机选择的位置。 先进先出算法(FIFO):假设高速缓存最多缓存8个字块,目前已经满了,如果此时再来一个字块,那么需要把最先进去的移除,把新来的添加道末尾。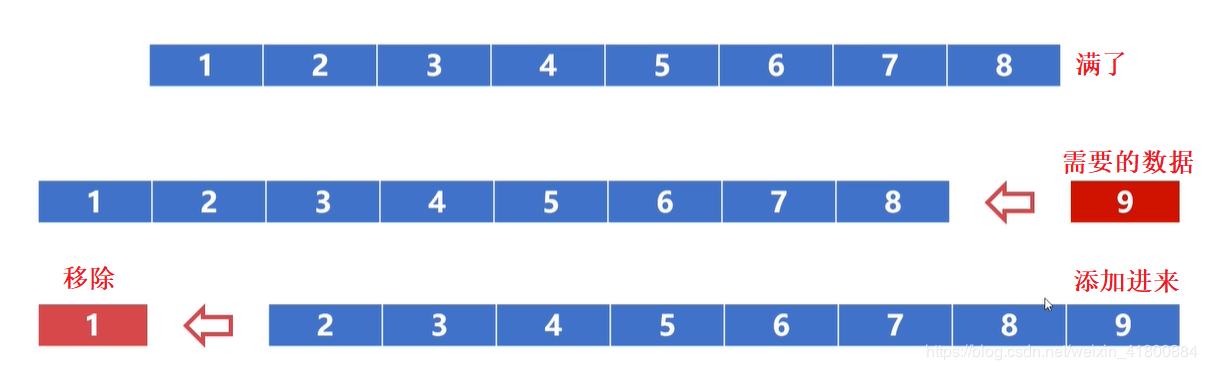
最不经常使用算法(LFU):
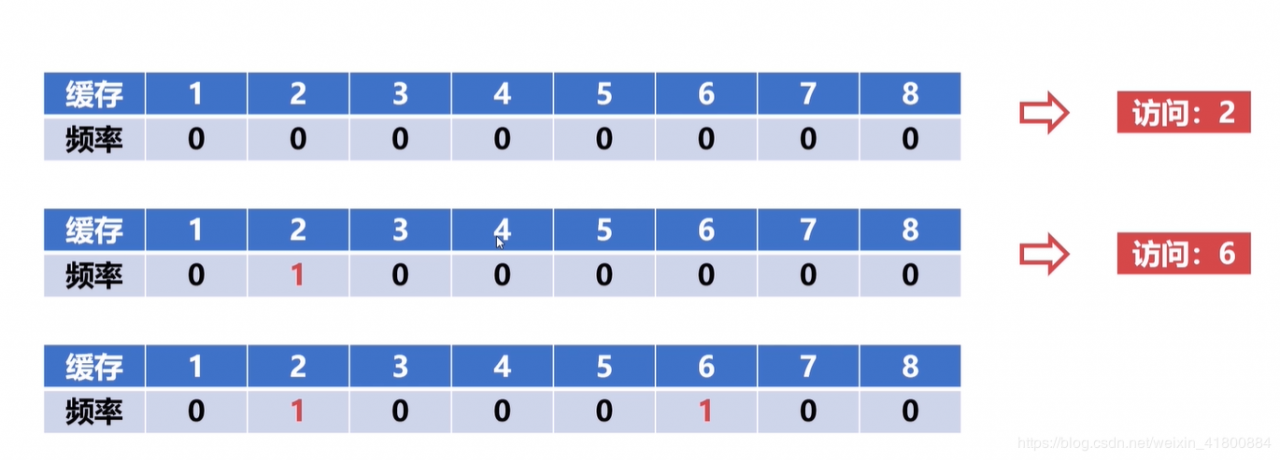

最近最少使用算法(LRU):

机器指令主要由两个部分组成:操作码和地址码。

操作码:指明指令所需完成的操作,它的位数反映了机器的操作种类。比如操作码为8位时,可以完成2^8(256)种操作。
地址码:给出操作数(操作数:规定了指令中进行数字运算的量)或操作数的地址。地址码可分为三地址码指令、二地址码指令、一地址码指令,还有零地址指令。



零地址指令:在机器指令中无地址码,比如空操作,停机操作,中断返回操作等。
4.2 机器指令的操作类型(了解) 数据传输类型:可发生在寄存器与寄存器之间,寄存器与存储器之间,存储器与存储器之间。比如数据读写、交换地址数据、清零置一等操作。 算术逻辑操作类型:操作数之间的加减乘除运算、操作数的与或非等逻辑运算。 移位操作类型:数据左移(乘2)、数据右移(除2)。 控制指令类型:等待指令、停机指令、空指令、中断指令等。 4.3 机器指令的寻址方式指令寻址:
顺序寻址:在一段连续的地址读取指令。 跳跃寻址:在某一地址突然跳到另一个不相邻的地址。数据寻址:
立即寻址:指令直接获得操作数,无需访问存储器。
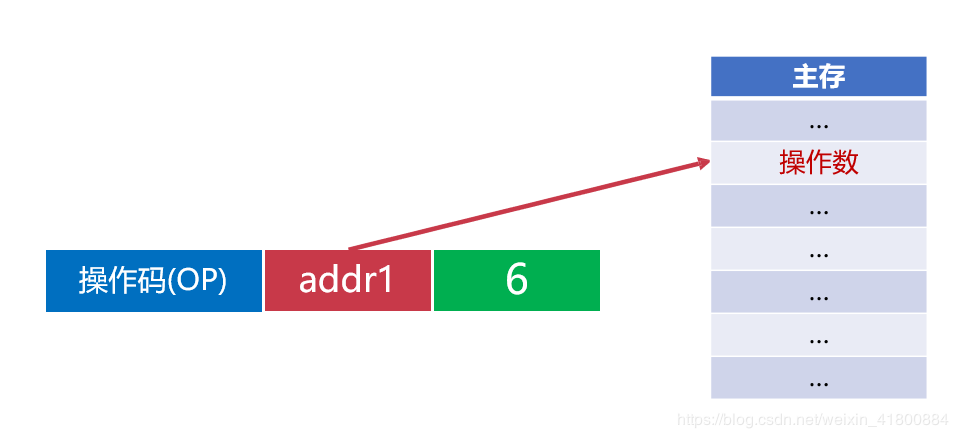
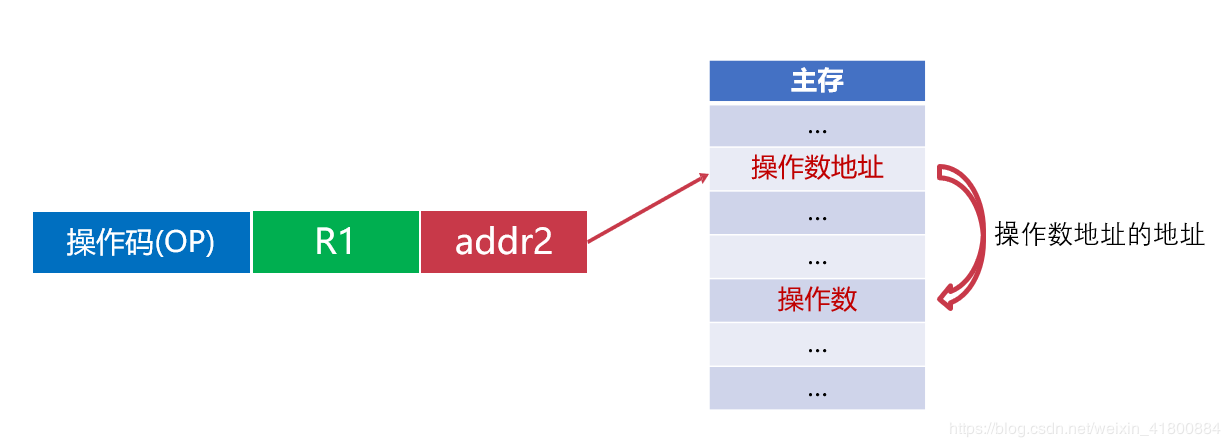
三种操作的对比:

控制器是协调和控制计算机运行的。
控制器的组成:
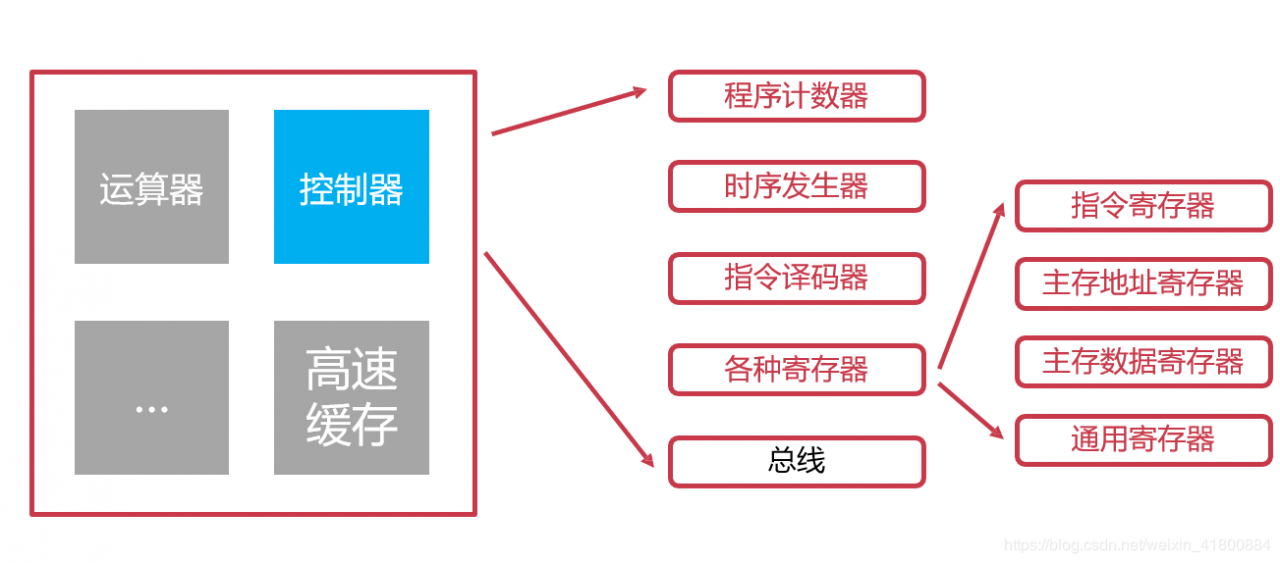
程序计数器(PC):
程序计数器用来存储下一条指令的地址。 循环从程序计数器中拿出指令。 当指令被拿出时,指向下一条指令。时序发生器:
电气工程领域,用于发送时序脉冲。 CPU依据不同的时序脉冲有节奏的进行工作。指令译码器:
指令译码器是控制器的主要部件之一。 计算机指令由操作码和地址码组成。 翻译操作码对应的操作以及控制传输地址码对应的数据。指令寄存器:
指令寄存器也是控制器的主要部件之一。 从主存或高速缓存取计算机指令。主存地址寄存器:
保存当前CPU正要访问的内存单元的地址。主存数据寄存器:
保存当前CPU正要读或写的主存数据。通用寄存器:
用于暂时存放或传送数据或指令。 可保存ALU(算术逻辑单元)的运算中间结果。 容量比一般专用寄存器要大。 6. 运算器运算器是用来进行数据运算加工的。
运算器的组成:
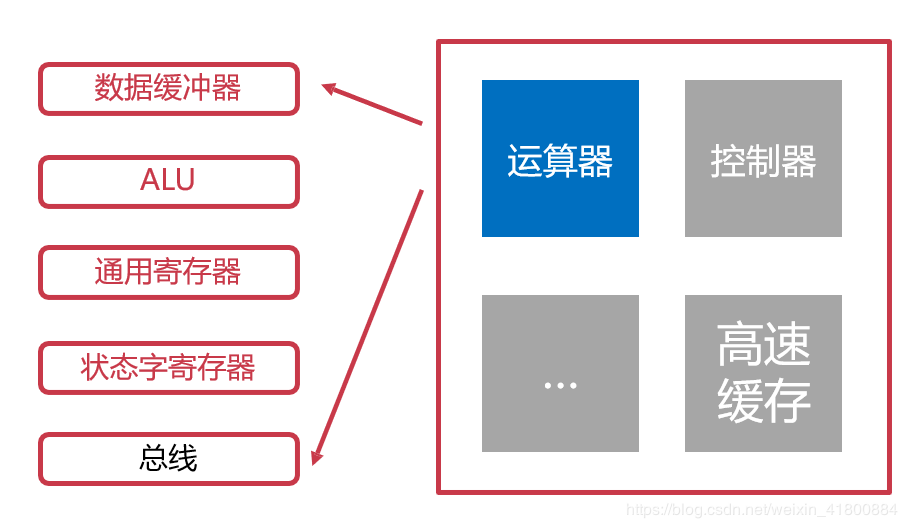
数据缓冲器:
分为输入缓冲和输出缓冲。
输入缓冲暂时存放外设送过来的数据。
输出缓冲暂时存放送往外设的数据。
ALU:(重要)
ALU:算术逻辑单元,是运算器的主要组成。
常见的位运算(左右移、与或非等)。
算术运算(加减乘除等)。
状态字寄存器:
存放运算状态(条件码、进位、溢出、结果正负等)。 存放运算控制信息(调试跟踪标记位、允许中断位等)。通用寄存器:
用于暂时存放或传送数据或指令。 可保存ALU的运算中间结果。 容量比一般专用寄存器要大。 7. 计算机指令执行的过程
可以看出,如果按照上面的执行过程,可得控制器和运算器不能同时工作,这就导致了CPU的综合利用率不高,所以提出了CPU的流水线设计,直接看图:

作者:FLUNGGG