个人学习笔记-计算机视觉篇-Faster R-CNN中的RPN(Region Proposal Network)
参考文献及资料:
https://blog.csdn.net/lanran2/article/details/54376126
https://blog.csdn.net/qq_35451572/article/details/80095628
https://blog.csdn.net/u014586602/article/details/92796317
http://arxiv.org/abs/1506.01497
RPN网络是一个小型的卷积网络,作用是标定出疑似识别目标的框体交由后续处理。
参考Faster R-CNN论文中的原图(图一)
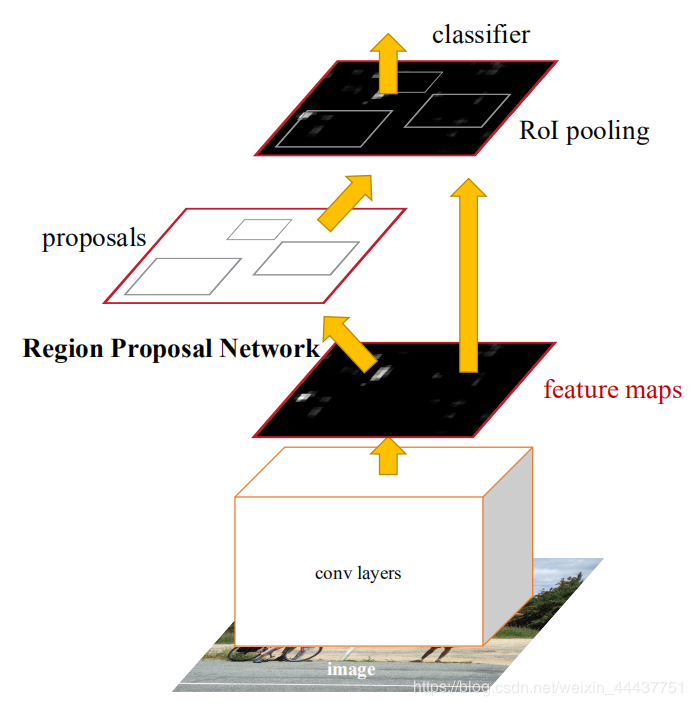
图一:Faster R-CNN流程
原始图像经历过一次CNN洗澡后,CNN洗完澡生成N×(W×H)的feature map;N我一般理解为通道数,W和H是feature map的长宽。这时就要进入RPN的节奏了。RPN是一个 卷积层(256维) +relu +左右两个层的(clc layer 和 reg layer)的小网络。RPN的主要功能类似于Fast R-CNN中的selective search 生成proposals过程,通过一个独立的小神经网络标记出候选的目标物体。
RPN通过256个n×n的卷积核将一个n×n区域内的图像转变为1×1×256的棍子型数据,整张图按这种思想提取,最后的输出是一个W×H×256的feature map;特征图中每个1×1×256的‘棍子’都代表公共feature map中n×n区域的信息。因为此时的特征图可以认为以1×1×256为单位切分成W×H份所以之后的clc layer 和 reg layer 都是以1×1大小的卷积核进行卷积。1 x 1卷积核卷积时,对各个通道都有不同的参数,因为输入又是1 x1的图片,所以相当于全连接的功能,相当于把 1 × 1 × 256展平成 256,然后进行全连接。
clc layer和reg layer作为两个全连接层分别负责给出当前特征块对应原图区域k个框体的前景背景判别(给出分数)和框体位置的确定(矩形的四个定点坐标)每个1×1×256的区块都对应了2k个评分(因为RPN是提候选框,还不用判断类别,所以只要求区分是不是物体就行,那么就有两个分数,前景(物体)的分数,和背景的分数)和4k个位置(针对原图的偏移坐标)
这样整个共享feture map就有H×W个结果,每个结果2k个评分加4k个位置。因为feture map 本身就是卷积后的图像,所以其上每一点对应原图一个区域(说框也行),比如说10×10,这里10是指原图和特征图的比例,所以这个并不是想要的框,那不妨把框的左上角或者框的中心作为锚点(Anchor),然后想象出一堆框,在RPN中这个框的个数对应的就是上面说的k(每个框对应一个评分和一个假设框体)。换句话说,H x W个点,每个点对应原图有K个框,那么就有H x W x k个框默默的在原图上,那RPN的结果其实就是判断这些框是不是物体以及他们的偏移;那么K个框到底有多大,长宽比是多少?这里是预先设定好的,共有9种组合,所以k等于9,最后我们的结果是针对这9种组合的,所以有H x W x 9个结果,也就是18个分数和36个坐标。这里可以参考图2
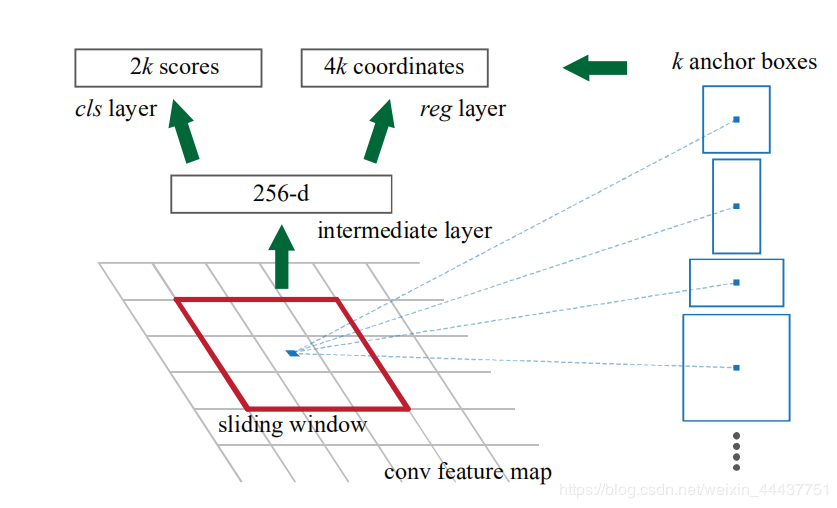
图二:特征图上每个输入区域对应九个预定好模式的框体
所有框体((H×W)×9)都会参与最后R-CNN的训练,但只有评分结果是前景的才会参与回归(工具框背景不配明显不配识别为物体);简而言之,只有前景才是proposal。这样就节约了大量的运算成本,后期更是对这些前景框体进行合并做NMS,比过去无头苍蝇型的NMS不知道高到哪里去。
OK
第一次写博客,想想还有点小激动。最近在学CV领域相关理论,预计后面还会看更多论文什么的。
这里是我个人的理解,其中理解不一定到位,后续也会继续学习。另外非常感谢参考文献中的几位大佬。原文论文实在是只能看懂单词,拼起来只能明白个大概。
作者:weixin_44437751