机器学习基础概念:查准率、查全率、ROC、混淆矩阵、F1-Score 机器学习实战:分类器
机器学习:基础概念查准率、查全率F1-Score、ROC、混淆矩阵机器学习实战:分类器性能考核方法:使用交叉验证测量精度性能考核方法:混淆矩阵精度和召回率ROC曲线训练一个随机森林分类器,并计算ROC和ROC AUC分数
查准率、查全率
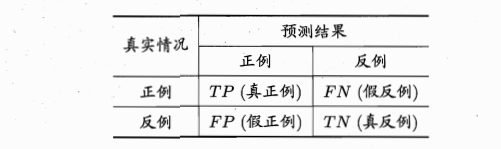
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例TP、假正例FP、真反例TN、假反例FN四种,令TP、FP、TN、FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数,分类结果的“混淆矩阵”为:
查准率P:
p=TPTP+FP
p=\frac{TP}{TP+FP}
p=TP+FPTP
查全率R:
R=TPTP+FN
R=\frac{TP}{TP+FN}
R=TP+FNTP
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
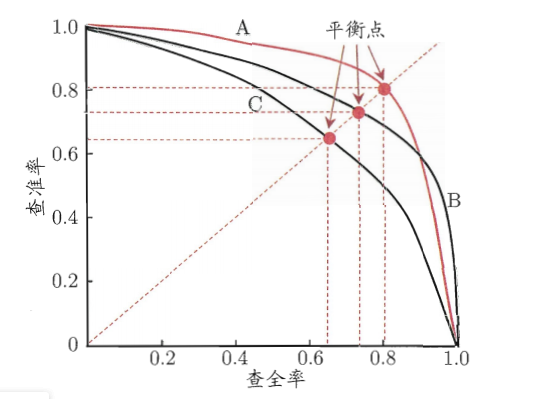
我们可以根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本,排在最后的是学习器认为“最不可能”是正例的样本,按此顺序逐个将样本作为正例进行预测,则每次都可以计算出当前的查全率、查准率。以查准率为纵轴,查全率为横轴作图就得到了“P-R曲线”,下面给出P-R曲线与平衡点的示意图:
 原创文章 14获赞 27访问量 1284
关注
私信
展开阅读全文
原创文章 14获赞 27访问量 1284
关注
私信
展开阅读全文
作者:混混度日的咸鱼