机器学习入门之无监督学习(四)
本文主要介绍深度自动编码器(Deep Auto encoder),做的事情还是降维,不过降维的时候是使用神经网络。
自动编码器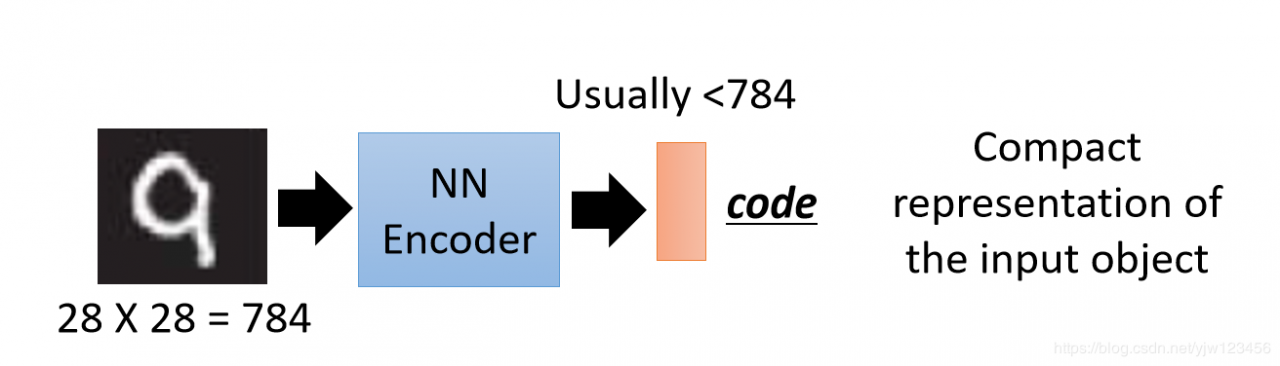
把很多隐藏层的神经网络当成编码器,输入一个图像后能得到一个编码。比如传入784维的手写数字,得到的编码通常会小于784维。
现在问题是我们如何得到这样一个编码器呢。要训练这个编码器我们需要同时训练一个解码器,能更加编码解码成原来的784维图像数据。

这件事情其实和PCA很像。
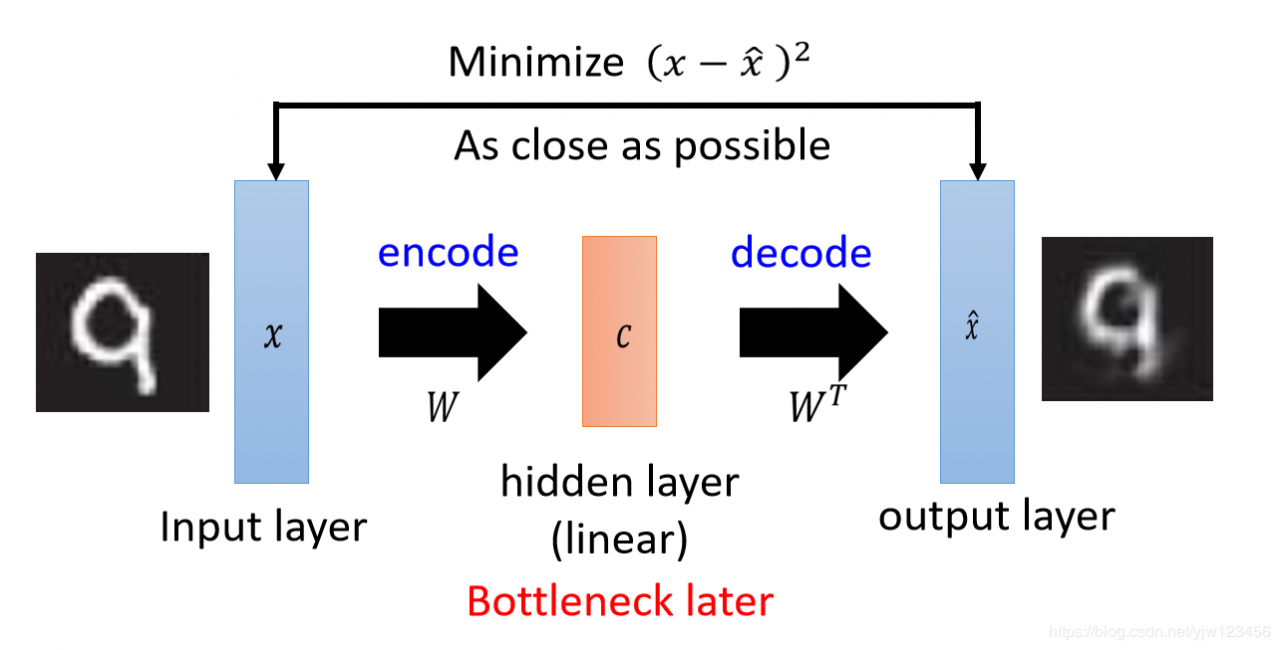
PCA做的事情是输入一个经过归一化的向量xxx然后乘上一个矩阵WWW得到一组编码ccc,再把这组编码ccc乘上同一组权重的转置WTW^TWT得到x^\hat{x}x^。
把这个结构看成NN的话,xxx就是输入层,ccc就是中间的隐藏层,x^\hat{x}x^就是输出层。我们把这里的隐藏层称之为瓶颈层(bottleneck layer)。从xxx到ccc的过程就是编码,从ccc到x^\hat{x}x^的过程就是解码。
深度自动编码器自动编码器的神经网络深一点就成了深度自动编码器。和PCA比起来就是多加了一些隐藏层而已。
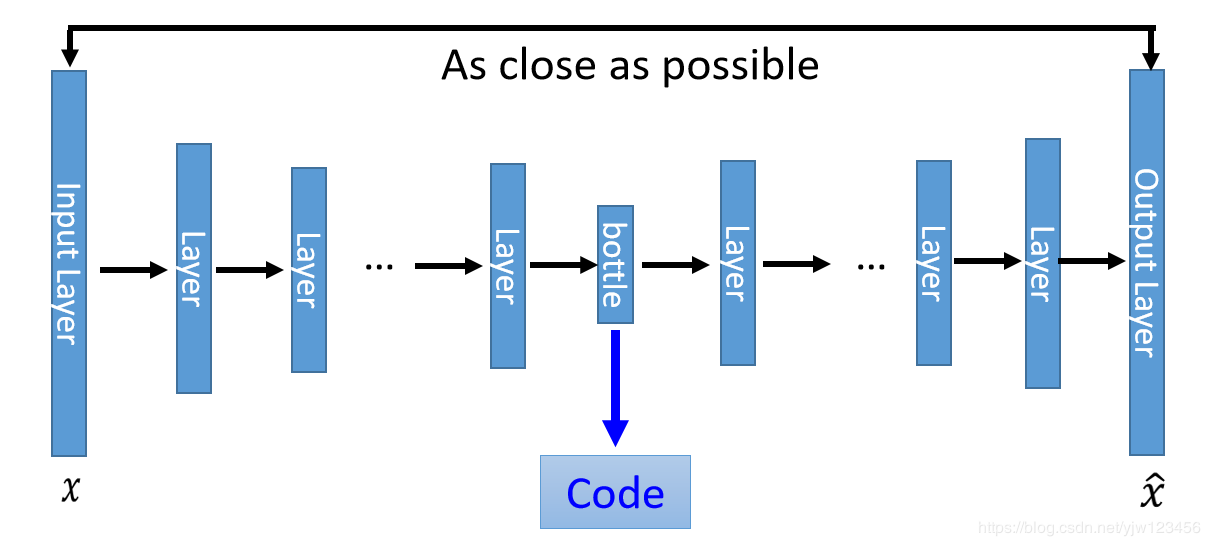
加了很多层隐藏层后得到bottele层就是编码,后面又经过很多隐藏层做的是解码,我们希望输入的xxx和最后输出的x^\hat{x}x^越接近越好。
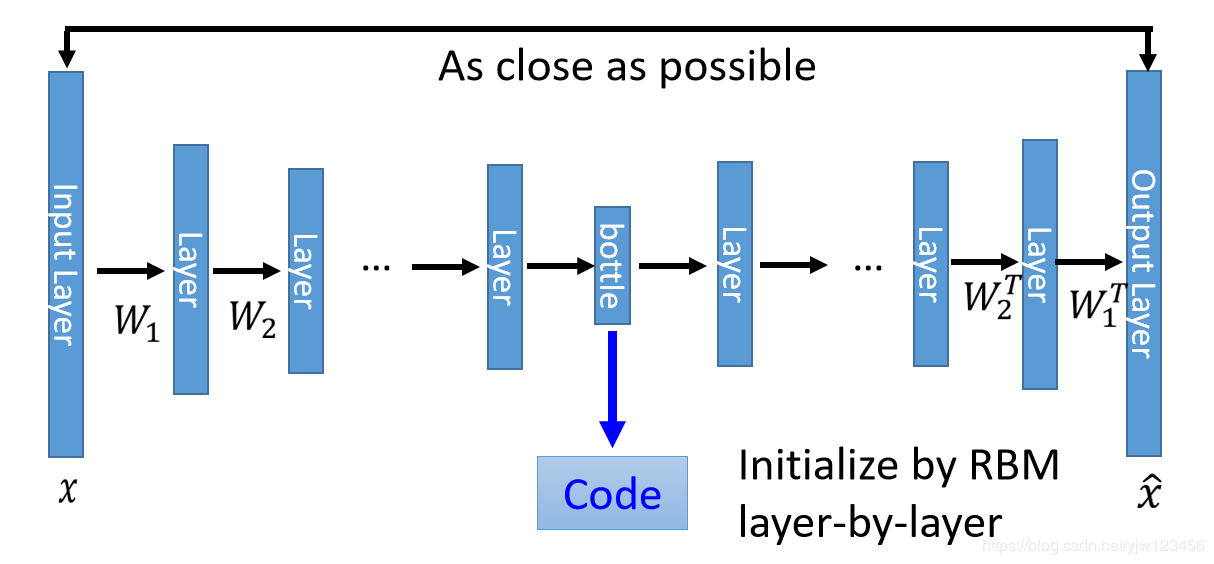
有时候我们会让这个编码器和解码器做一下参数的限制。上面说了,在做PCA时,编码和解码的参数互为转置,我们在做自动编码时也希望如此。
看下效果如何。
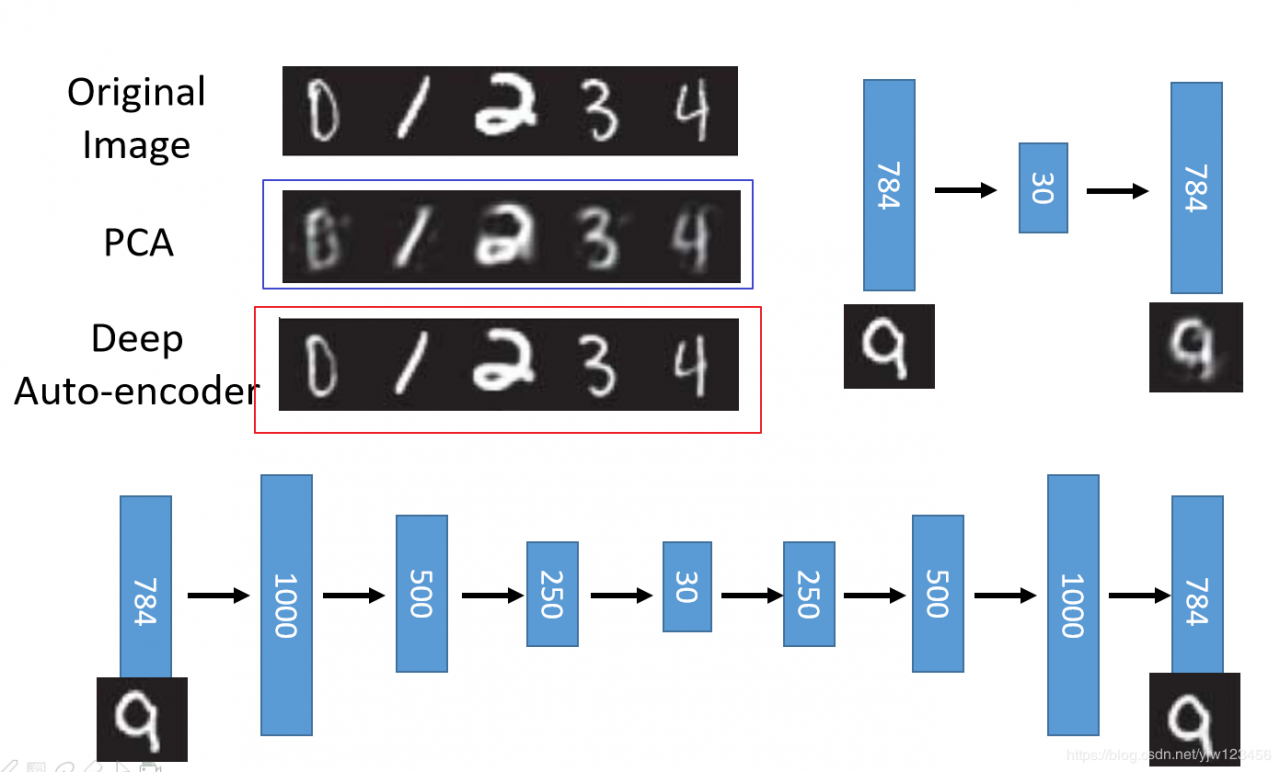
蓝框标出的是经过PCA编码后降成30维,再解码回来后的样子,会看到比原图(第一个数字图片)模糊了不少;而经过深度自动编码后的几乎和原图一样清晰。
但是这不是重点,重点是编码有多好。
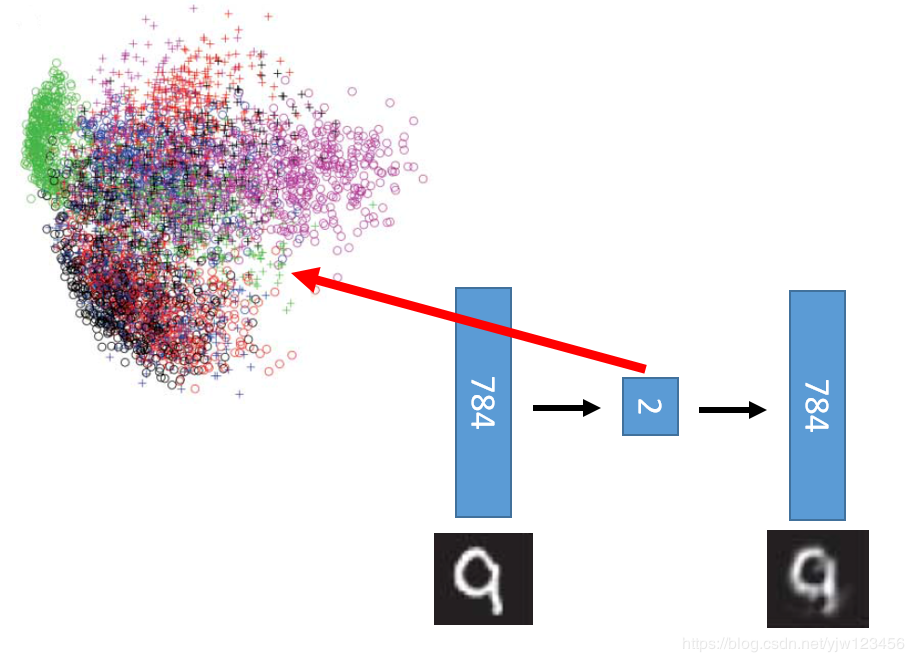
如果用PCA降到2维的话,结果可以看到很差,基本上都无法区分了。
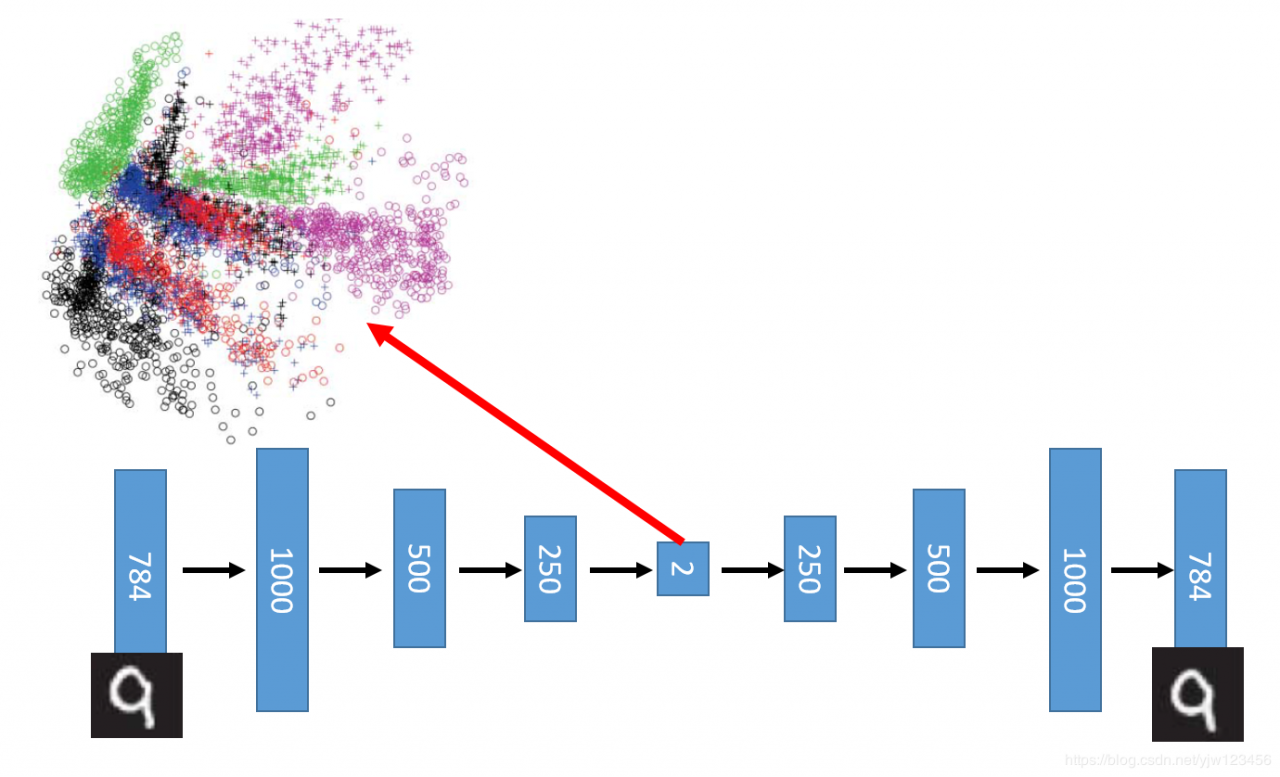
而用自动编码做到2维,得到的结果好得多。我们还可以通过去噪自动编码(de-noising auto-encoder)来使的自动编码训练的更好。
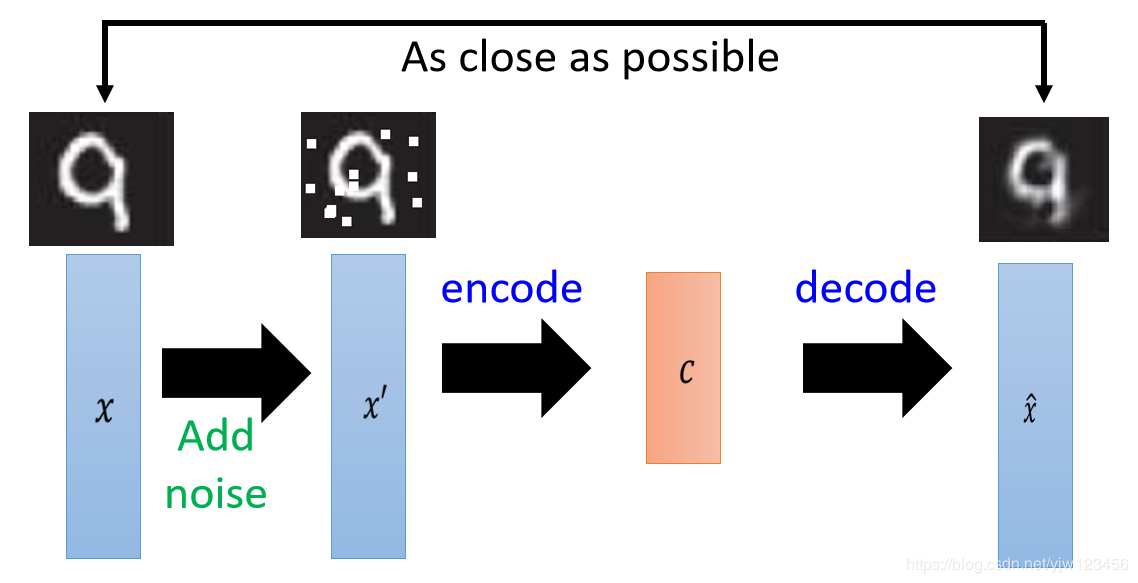
我们在原来输入xxx上面加上噪声,得到新的输入x′x^\primex′,这样不止需要做压缩,还需要把噪声去掉才能使得输出和原来的输入xxx接近。

这个图是上篇文章介绍的直接用像素点做t-SNE的结果,可以看到,4、9是区分不了的。

如果先用PCA降到32维,再做t-SNE的结果是这样,4和9只是稍微分开了一点,但是还是很接近。
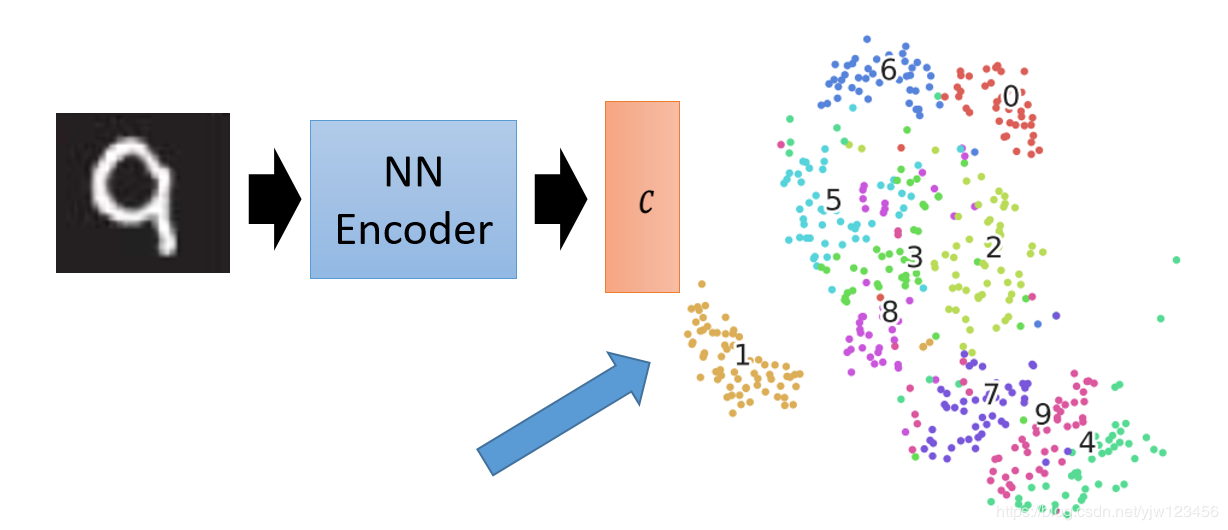
如果用自动编码来得到一个编码器后,然后我们用这个编码器来编码新的图片得到新的编码。上面的结果都是新的图片,是它在训练的时候没有见过的图片。可以看到不同颜色的数据点分得还是比较开的。
自动编码的其他应用 文本检索自动编码不仅可以用到图像上,还可以用于文本检索。比如输入一段文字,检索出来在哪些文章中出现过。
如何做文本检索呢,有个传统的方法叫向量空间模型(vector space model)。
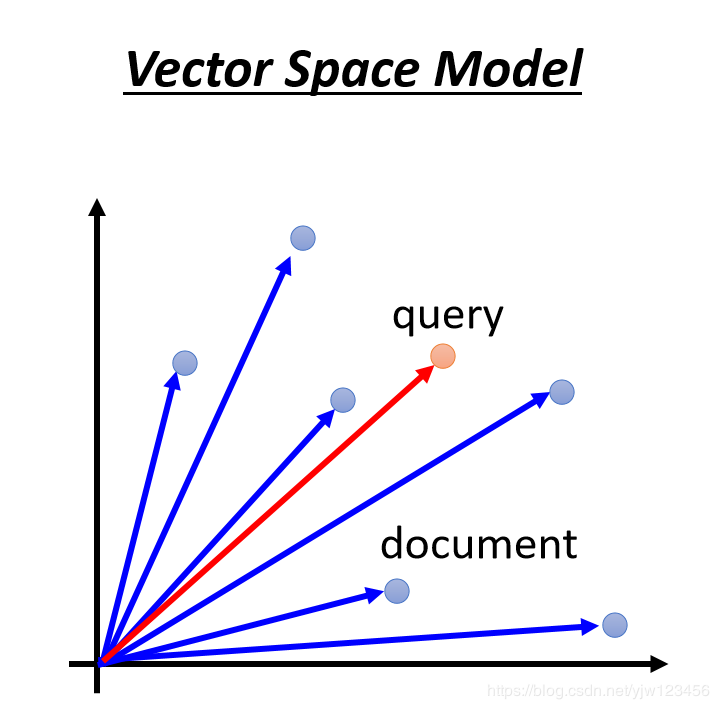
把每个文档(就是每篇文章)和检索的文本(query)都用一个向量表示。然后看这个query和哪些文档的相似度高。
最简单的做法是通过词袋(bag-of-word)的方法,它会开一个很高维的空间,它的维度就是现在它能观察到的所有的词汇。假设英文共有10万个词汇,那它的维度就是10万维。每个维度对应到一个词汇。
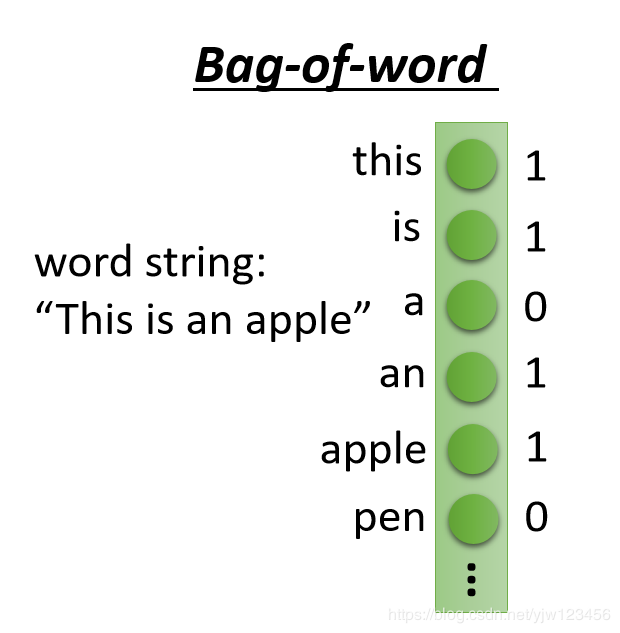
以"This is an apple"为例,“this”(经过了大小写转换)出现在这个句子中,它对应的维度值就是1,没有出现的词汇维度就是0。上面就是描述这句话的一个向量。
这种方法虽然很简单,但是没有考虑到语义,同义词无法体现在这个模型中。
一种改进方法是加一个自动编码器,把2000维的词袋降成2维。
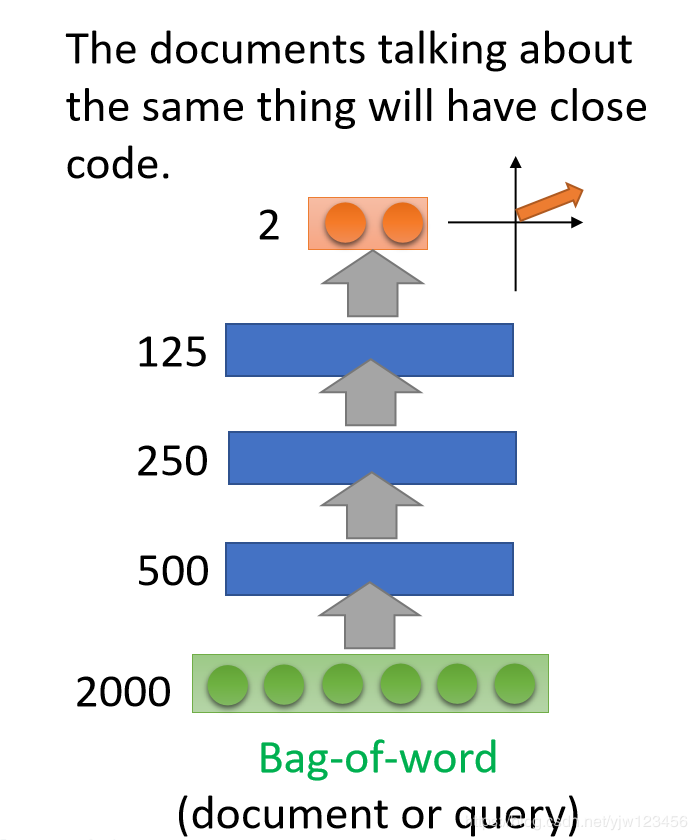
如果可视化这些2维点的话,就是下面这样子。
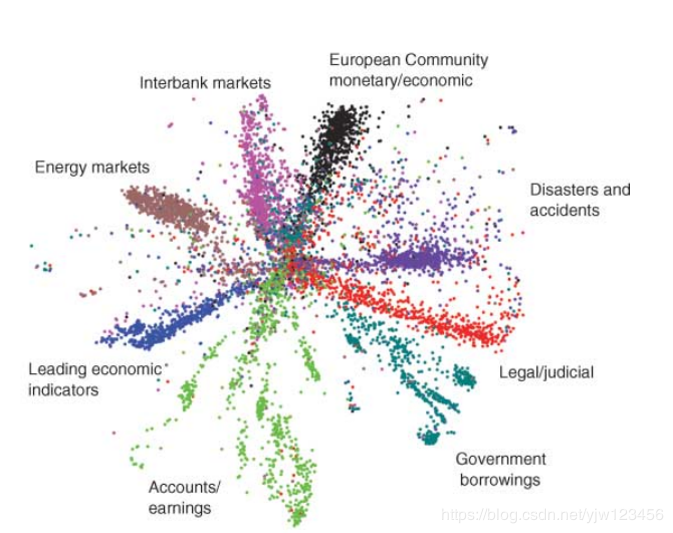
它的分布像一朵花一样,不同类别的文章就是一个花瓣。

然后搜索的时候,输入一个查询(query),落到红点的地方,就可以找到这个类别所有的文章。
虽然在这个类别的文章中,某些文章可能没有和你查询一样的词汇,但是通过自动编码降维后,机器可以把同类的文章找出来。
如果使用传统的线性LSA方法得到的结果会很差。

图片搜索就是检索相似图片,以图找图。

比如要搜索迈克尔·杰克逊的图片,如果使用欧几里得距离计算像素点的距离,机器会与图片库中的所有图片进行距离计算,越小说明越相似。得到的结果是后面这些,可以看出来很不准确。
如果使用自动编码器的话,需要训练一个编码器,把图片丢到这个编码器后,经过很多层的转换后变成256维度的编码,然后再把它解码成原来的图像。
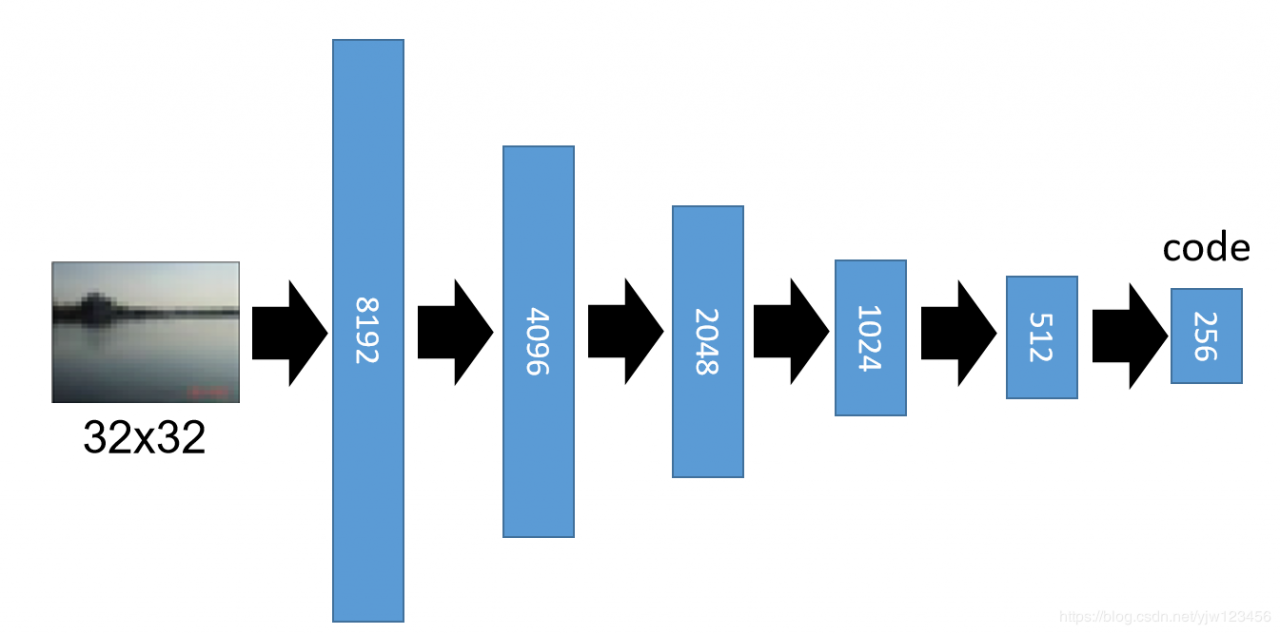
然后解码后的图像是后面这样子的。

虽然解码后很模糊,但这不是重点,重点是我们可以拿那个编码做相似度计算。

我们把它编码到256维后,进行相似搜索得到的图片是上面的样子,虽然还是很不像,因为迈克尔的头发比较长,甚至返回的图片都是女性,但是至少返回的都是人脸了。不像上个图片,啥都有。
用CNN来做自动编码上面讲的做自动编码的神经网络都是全连接的,
如果处理的是图像的话,完全可以用CNN(卷积神经网络)来做。
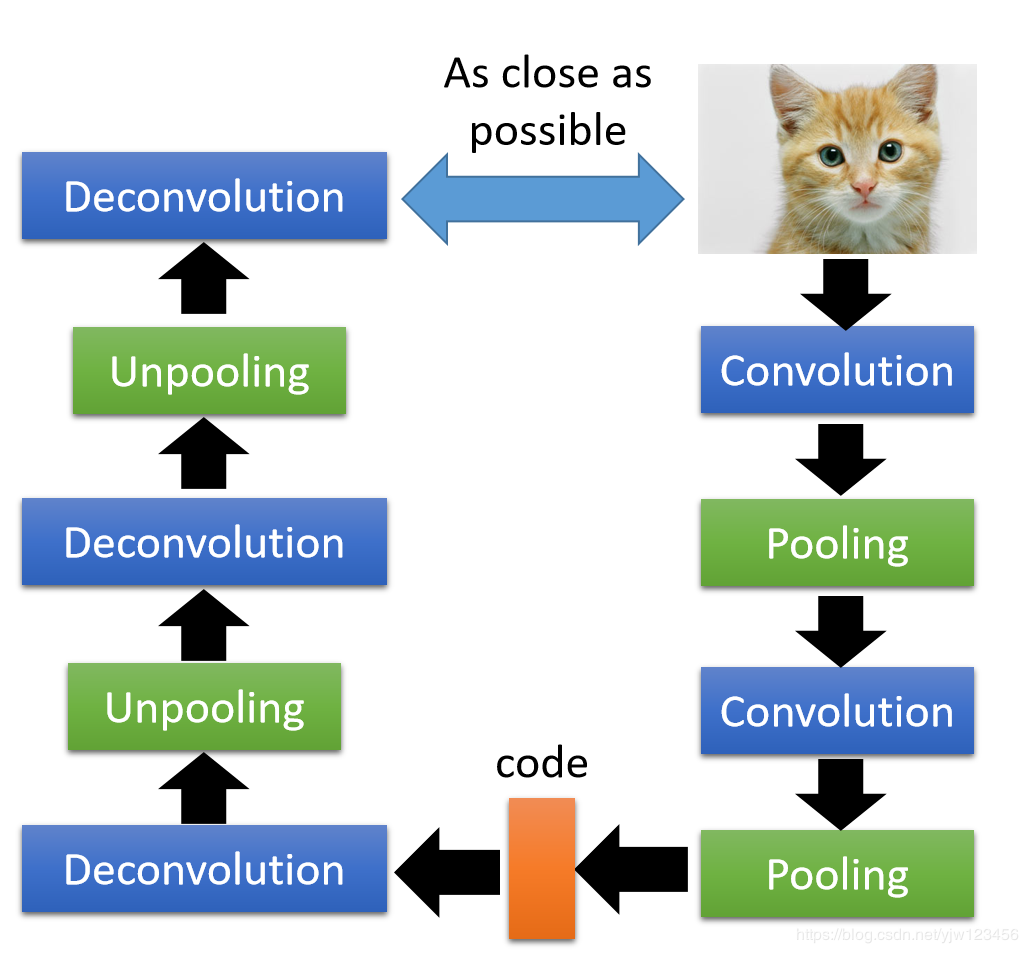
拿到一幅图像,把它做Convolution,然后再做Pooling,再做Convolution,再做Pooling就得到编码;解码的话做Deconvolution和Unpooling。最终使得输出的图像和原图越接近越好。
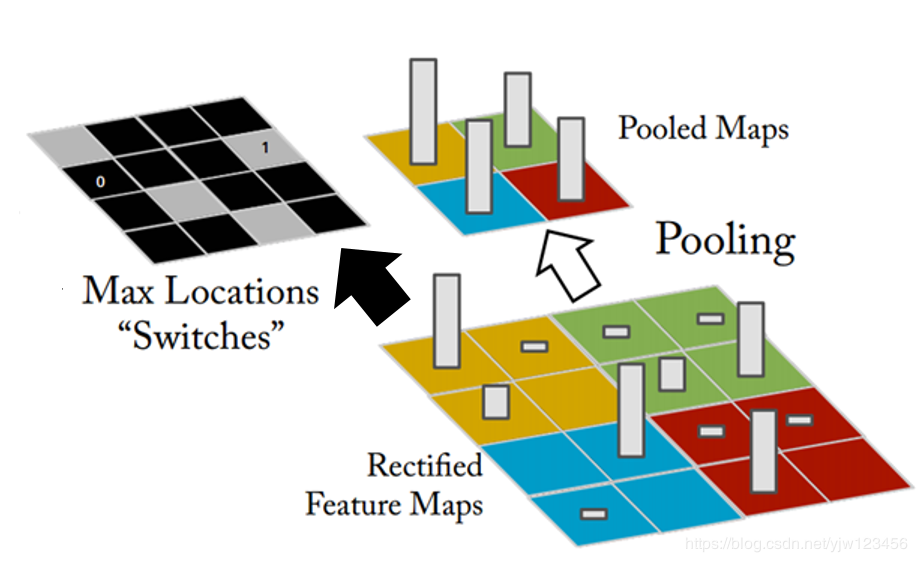
做Max Pooling的时候,我们把Filter的输出,四个一组,选一个最大的,就得到右上角那个Pooled Map。同时左上角那个图片说的是记录哪个位置是最大的。
在做Unpooling的时候就是,有张比较小的图片,我们要把每个像素点扩展成四个。
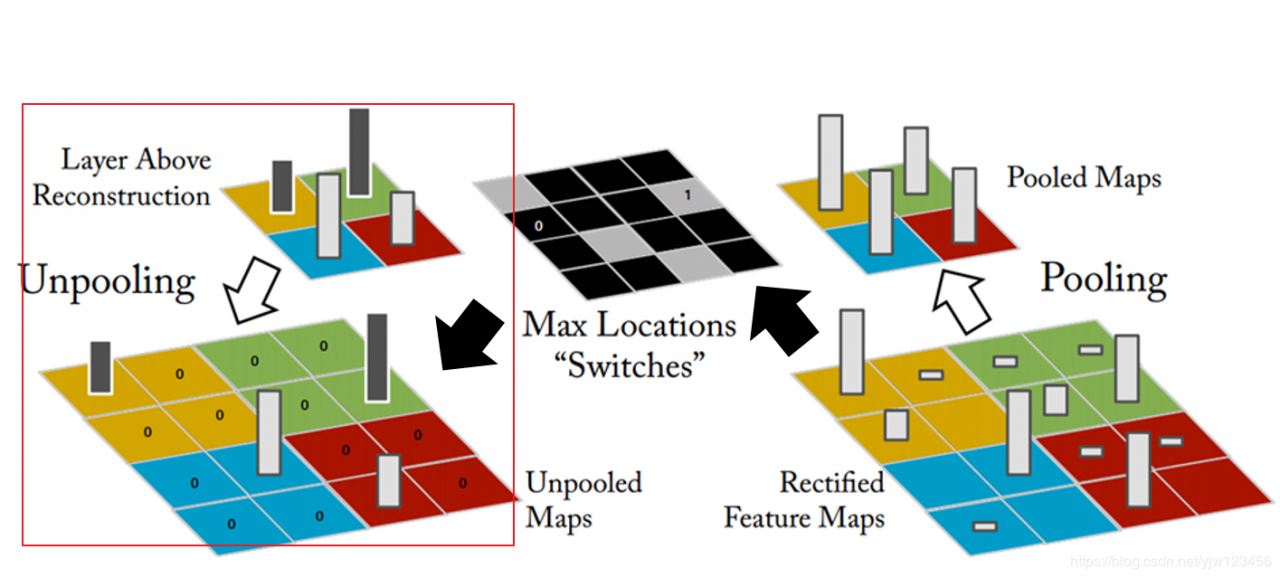
我们仔细的看黄色的部分,本来Max Pooling取Max的时候是从左上角取,因此,就把原来的黄色像素点放到左上角。剩下的三个点通通补0。
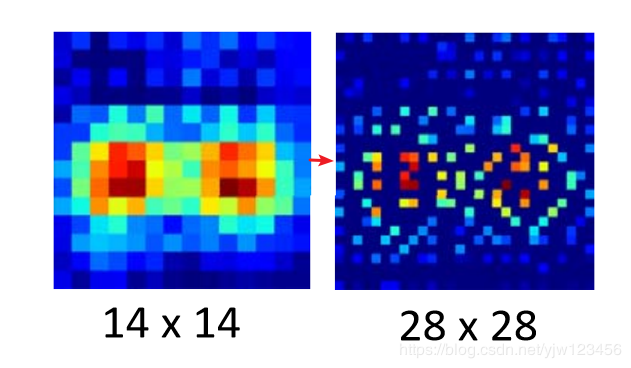
本来原来的图片是14*14,在做Unpooling后会变大,变成原来的两倍。
那Deconvolution怎么做的呢?
Deconvolution事实上Deconvolution就是Convolution。
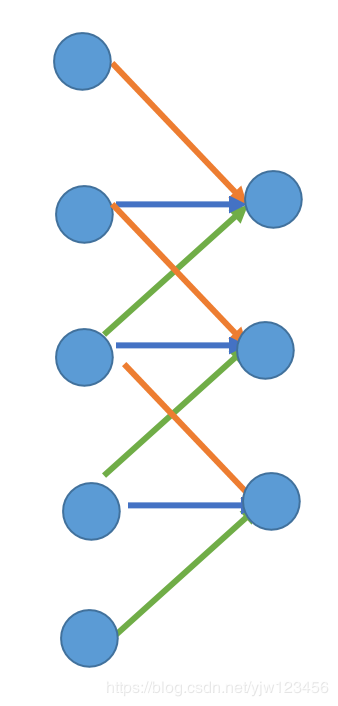
我们做Convolution的时候,我们把一个区域里面的数据乘上Filter中的3个参数得到一个输出,再移动Filter,乘以同样的参数,得到新的输出。
Deconvolution顾名思义就是反向操作,就是一个值乘上三个不同的权重,得到三个值。
注意会有重叠,我们把重叠的地方加起来。
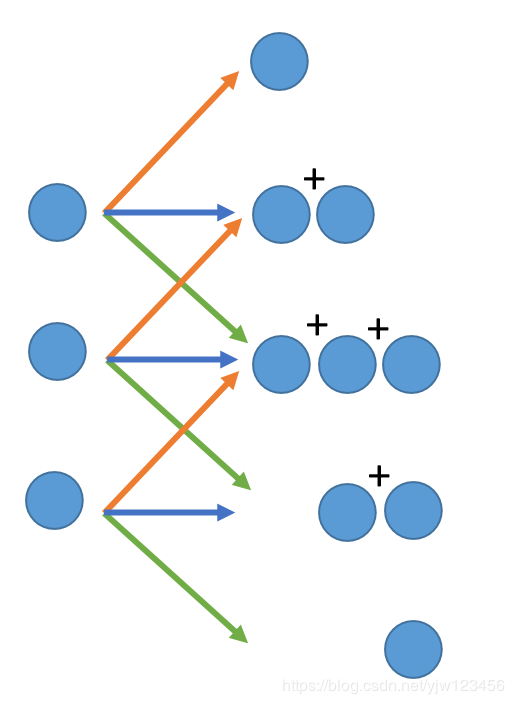
其实这件事情等同于,把其他地方补很多0(等式右边灰色的就是0)。
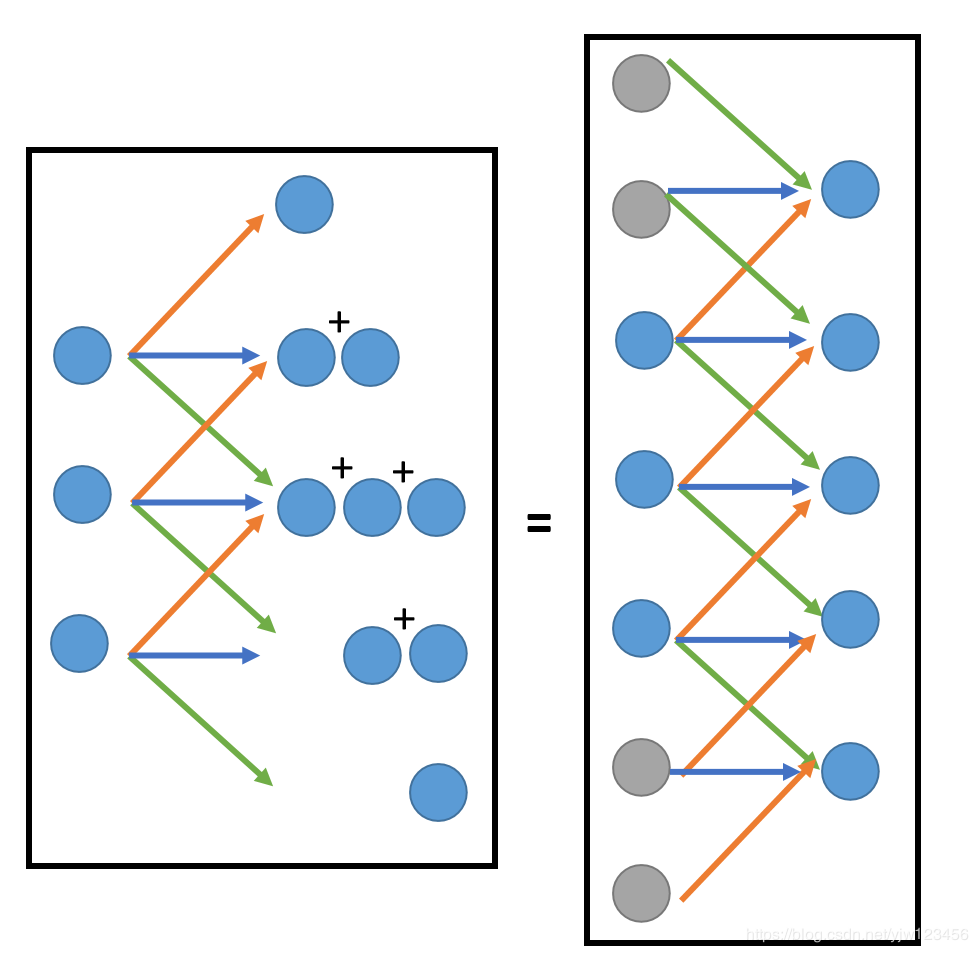
看右边的图片会发现和Convolution是一样的,只不过多了一些0而已。
预训练DNN自动编码还可以和监督学习的方法结合,可以用于深度神经网络的预训练(Pre-training)。
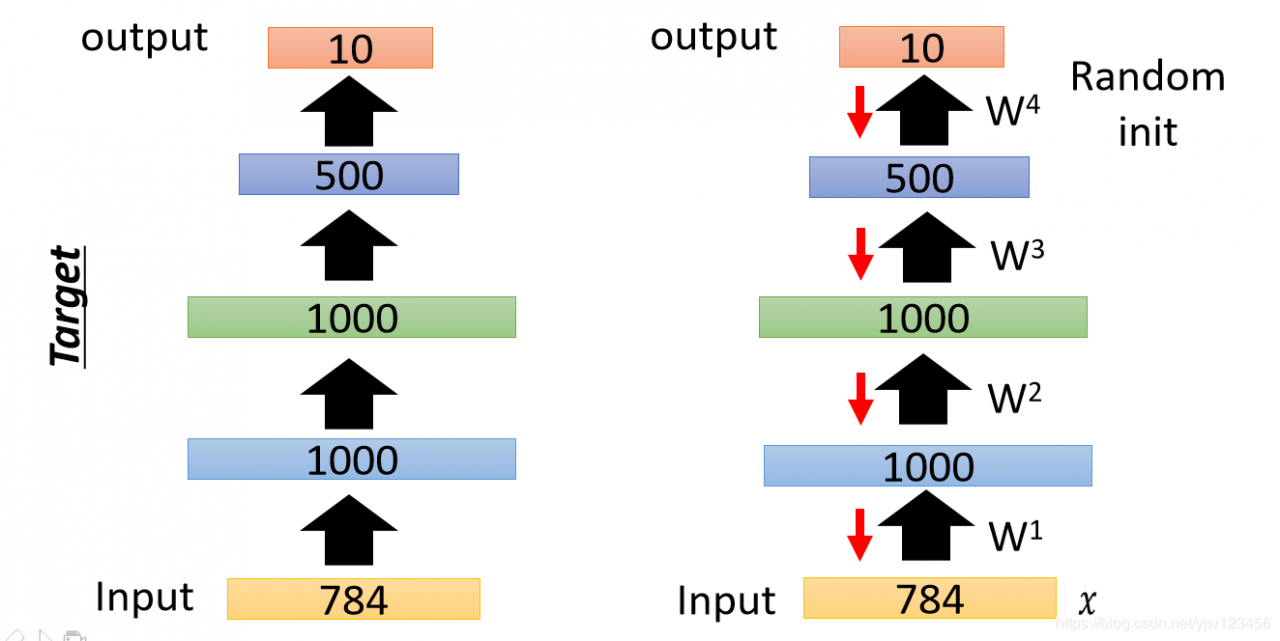
比如要做手写数字识别,最终是要把784维的图像转换到10维(哪个维度是1就说明是哪个数字,可以参考手写数字识别)。
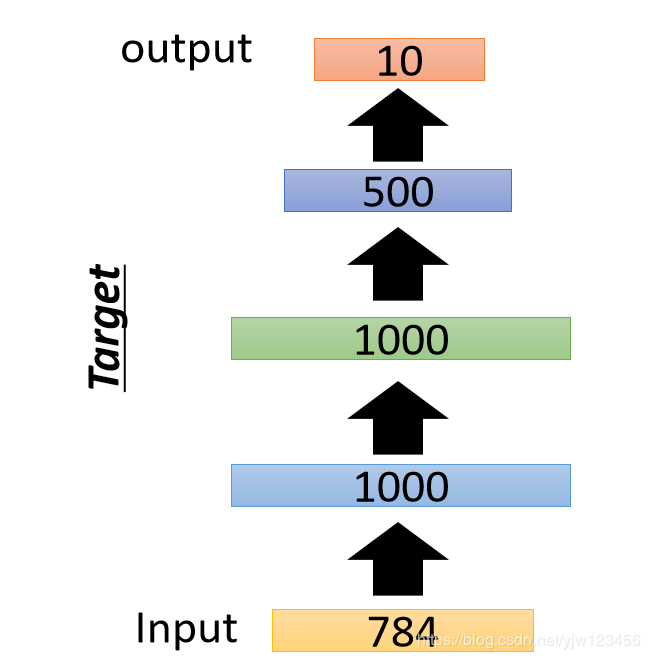
我可以预训练一个自动编码器,它是无监督的方法。
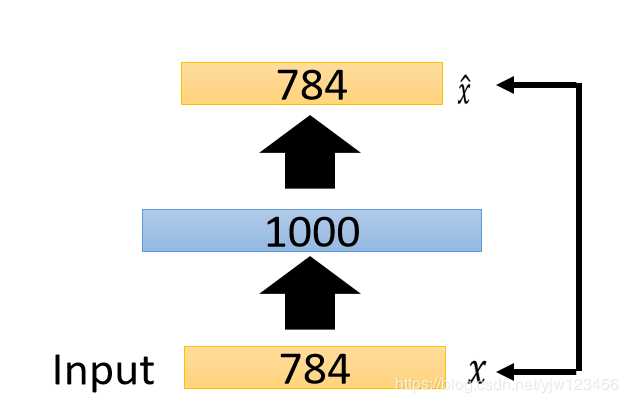
可以训练一个编码器,它中间的隐藏层是1000维,输出是784维的x^\hat{x}x^。这里的1000维和DNN的中1000维对应,输出的784维和DNN中输入的维度对应。为了训练好这样一个自动编码器,如何增加一些噪声,做去噪自动编码,这样才会得到比较好的结果,避免它直接把输入抛出来。
我们先训练一个自动编码器,得到权重w1w^1w1和W1′W^{1\prime}W1′。
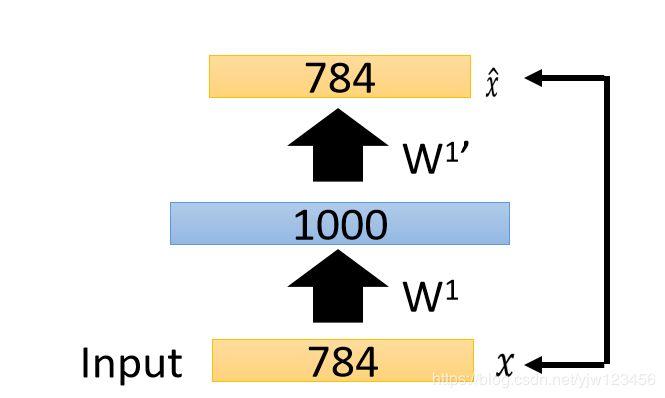
保留W1W^1W1,接下来把所有的xxx都用W1W^1W1转成一个新的特征,叫做a1a^1a1。
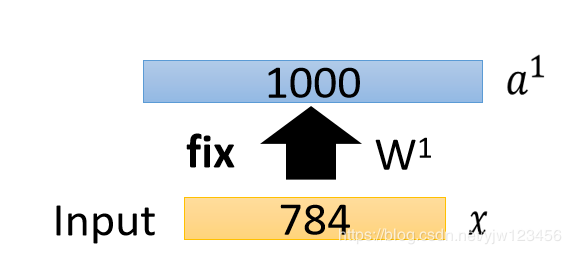
接下来再训练另一个自动编码器,把1000维变成编码,再转回来得到a^1\hat{a}^1a^1,得到权重W2W^2W2。
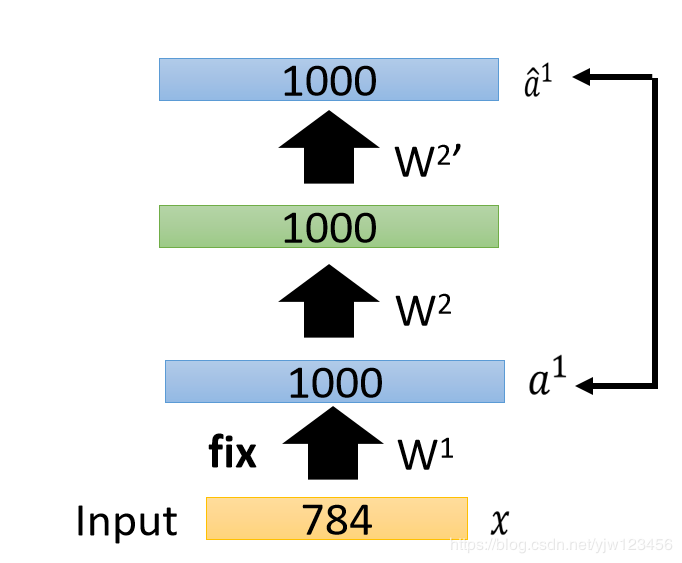
接下来把所有的xxx通过W1W^1W1和W2W^2W2得到a2a^2a2。
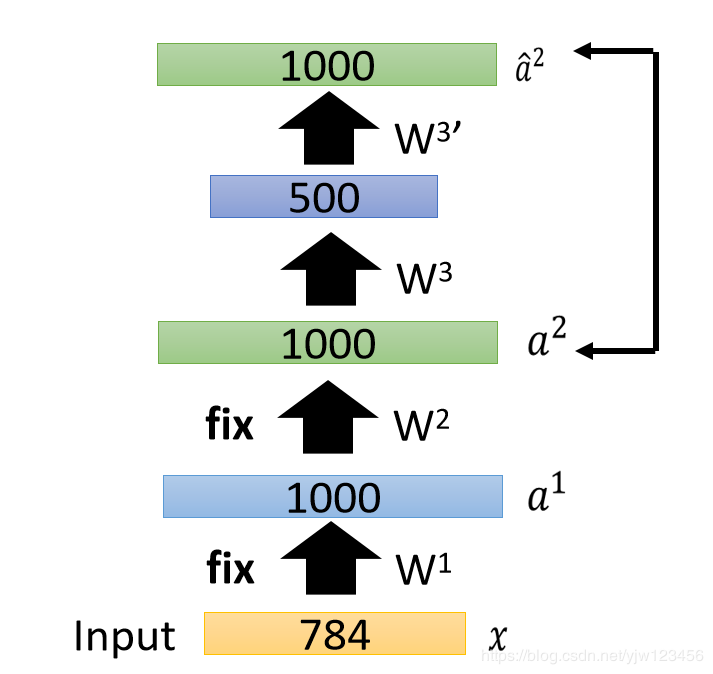
接下来再训练第三个自动编码器,得到W3W^3W3。
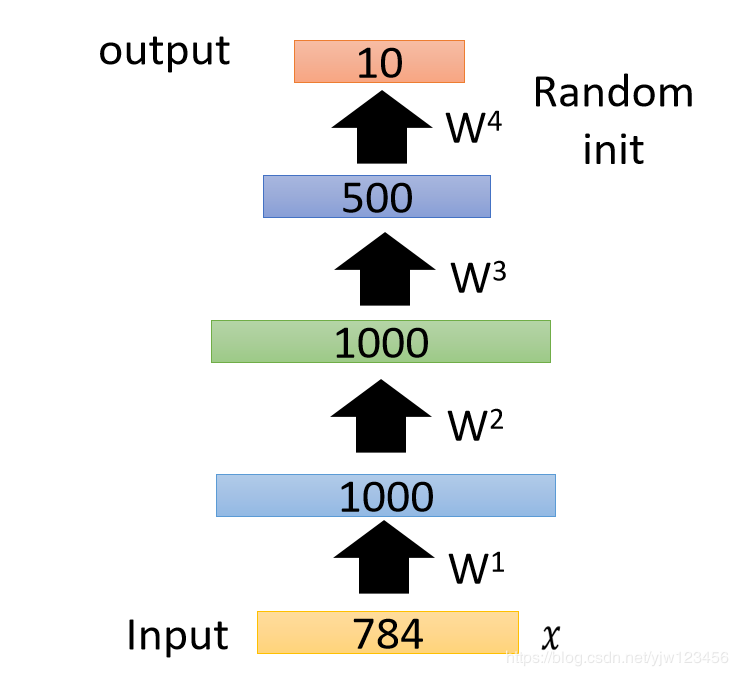
接下来把W1,W2,W3W^1,W^2,W^3W1,W2,W3当做神经网络的初始参数,把最后的输出层接上去,输出层做随机初始就好。
最后用反向传播算法来微调所有的参数。这样就可以用自动编码器来预训练一个比较深的网络。
1.李宏毅机器学习
作者:愤怒的可乐