6-机器学习之KNN(K-近临算法)
tags: python,机器学习,KNN,matplotlib,pyplot,pandas,numpy,Series,DataFrame
文章目录一、 k-近邻算法原理二、k-近邻算法案例2.1. 使用步骤2.2. 预测电影类型2.3. 通过身高、体重、鞋子尺码数据预测性别2.4. 预测鸢尾花类型2.4.1. 常规机器学习步骤2.4.2. 机器学习结果可视化(获取knn分类的边界)2.5. 使用交叉表对预测结果进行可视化展示2.6. 对训练值、训练值标签、预测标签进行可视化展示2.7. k-近临算法用于回归对趋势进行预测三、其他知识补充3.1. 随机数种子3.2. 机器学习数据标准化四、`K近临回归算法`和`Lasso回归`在线性数据预测中的表现 一、 k-近邻算法原理存在一个样本数据集合,也称作训练样本集(一般在代码中用X_train和y_train表示),并且样本集中每个数据都存在标签(y_train存放标签数据),即我们知道样本集中每一数据(X_train中存放)与所属分类(y_train中存放)的对应关系。
输人没有标签的新数据(X_test中存放)后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。
一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
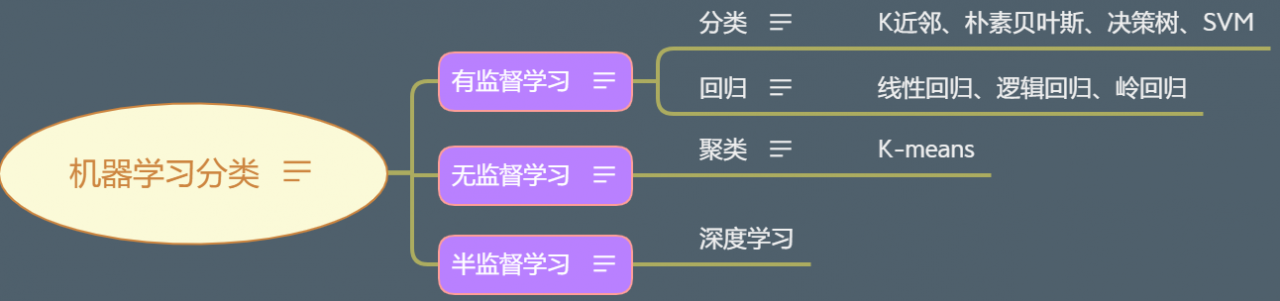
k-近邻算法属于有监督学习算法,即训练值中有对应的结果。机器学习的分类见上图。
通过统计每个电影中,接吻和打斗的次数,来区分电影是动作片还是爱情片。
目前有电影数据movie数据如下:
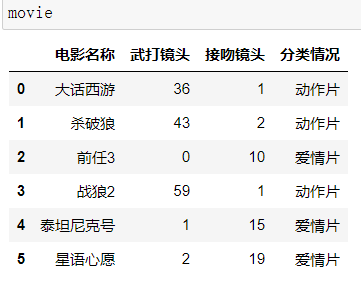
获取训练数据X_train和对应的标记y_train:
X_train = movie[['武打镜头', '接吻镜头']]
y_train = movie['分类情况']
将上面获取到的训练数据使用knn算法进行计算,但是在计算前,需要先导入使用到的模块:
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
# 训练数据必须是2维, 标记没有要求是几维的,一般是1维, 而且也没有要求必须是数字,
knn.fit(X_train, y_train)
训练数据必须是2维,
标记没有要求是几维的,一般是1维,而且也没有要求必须是数字。
现在有待预测的新数据:
# 预测数据
# 哪吒, 海王, 红海行动, 前任2,
X_test = np.array([[50, 0], [40, 2], [65, 0], [1, 20]])
使用上面的待预测数据X_test,调用训练好的模型,来预测其对应的分类结果:
knn.predict(X_test)
输出结果为array(['动作片', '动作片', '动作片', '爱情片'], dtype=object)
最后可以测试一下我们的模型预测的准确率:
y_test = ['动作片', '动作片', '动作片', '爱情片']
knn.score(X_test, y_test)
输出结果为1.0,即预测准确率为100%。
# 调包
from sklearn.neighbors import KNeighborsClassifier
# 准备数据
X_train = [[180, 180, 43], [170, 150, 39], [173, 128, 43], [170, 140, 39], [163, 90, 39], [164, 85, 36.5], [155, 75, 35], [172, 110, 41], [165, 114, 40], [175, 130, 43], [171, 135, 43], [160, 90, 36],[160, 90, 36], [158, 85, 36]]
y_train = ['男', '男', '男','男', '男', '女', '女', '女', '男', '男', '男', '女', '女', '女']
# 建立训练模型并训练
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
# 对新数据进行预测
# 对应的实际结果为y_test = ['男', '男', '女', '女', '男', '女']
X_test = [[173, 118, 42], [173, 145, 41], [173, 120, 40], [165, 95, 40], [160, 120, 41], [158, 100, 36]]
knn.predict(X_test)
上面的代码的输出结果为:['男', '男', '男', '女', '男', '女']
使用上面训练好的模型对训练数据进行计算得分:
knn.score(X_train, y_train)
输出结果为:0.8571428571428571
对测试数据计算得分:
y_test = ['男', '男', '女', '女', '男', '女']
knn.score(X_test, y_test)
输出结果为:0.8333333333333334
先从sklearn数据库中获取鸢尾花的数据,代码如下:
from sklearn.datasets import load_iris
iris = load_iris()
把获取到的鸢尾花的数据保存到iris中,数据为字典的形式,其中key值为'data'的数据对应的值为鸢尾花的4个特征值,是一个二维数据。行为每一个花对应的数据,列为每一个特征对应的值。另外其中key值为'target'对应的值为'data'对应的值中每一行(代表一朵花)值代表的花的类型,也即是标记。
但是我们不能自己创造新的测试数据来对训练好的模型进行测试,所以为了验证模型的准确性,我们需要从iris中随机抽调训练值和测试值。
对此我们使用train_test_split模块,从已有的数据和其对应的标签中,随机切分出训练数据X_train、测试数据X_test、训练数据对应的标签y_train、测试数据对应的标签y_test。
模块导入代码:from sklearn.model_selection import train_test_split
准备数据:
data = iris['data']
target = iris['target']
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
建立模型,并进行训练:
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
使用训练数据测试模型的得分:
knn.score(X_train, y_train)
得分为:0.975
由于上面使用train_test_split切分是随机的,所以每次取到的数据都是不一样的,所以这里的得分一般不相同)
使用测试数据计算模型的得分:
knn.score(X_test, y_test)
2.4.2. 机器学习结果可视化(获取knn分类的边界)
由于上面的步骤最后只给了一个模型得分的结果,可视化不是很好,所以可以使用别的方式,将预测结果做的比较直观一些。
首先我们将所有鸢尾花的特征值画到一个线图中,以通过观察来选择用于可视化的特征参数。
df = DataFrame(data=data)
df.plot()
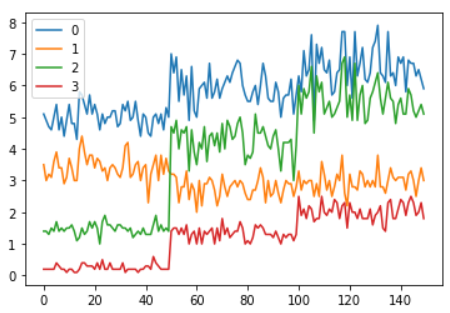
上面的图片中,每一个系列就是数据中的一列,也即是代表了鸢尾花的4个特征值中的一个。图片中所有的数据,每一列从开始到最后,代表了3种花,所以在图中可以看到曲线有跳跃的地方,有的曲线被很明显的分成了3段。
我们可以通过散点图的形式,选取4个特征中的两个,来观察三种花在这两种特征值中的分布情况。由于我们要区分不同的花,所以特征值中数据最好不要有重叠,我们可以将上面的4个特征值之间所有的散点图画出来,见下代码:
plt.figure(figsize=(3*5,2*4))
c = 1
for i in range(3):
for j in range(i+1,4):
plt.subplot(2,3,c,title='{}-{}'.format(i,j), facecolor='c')
plt.scatter(data[:,i],data[:,j],c=target)
c += 1
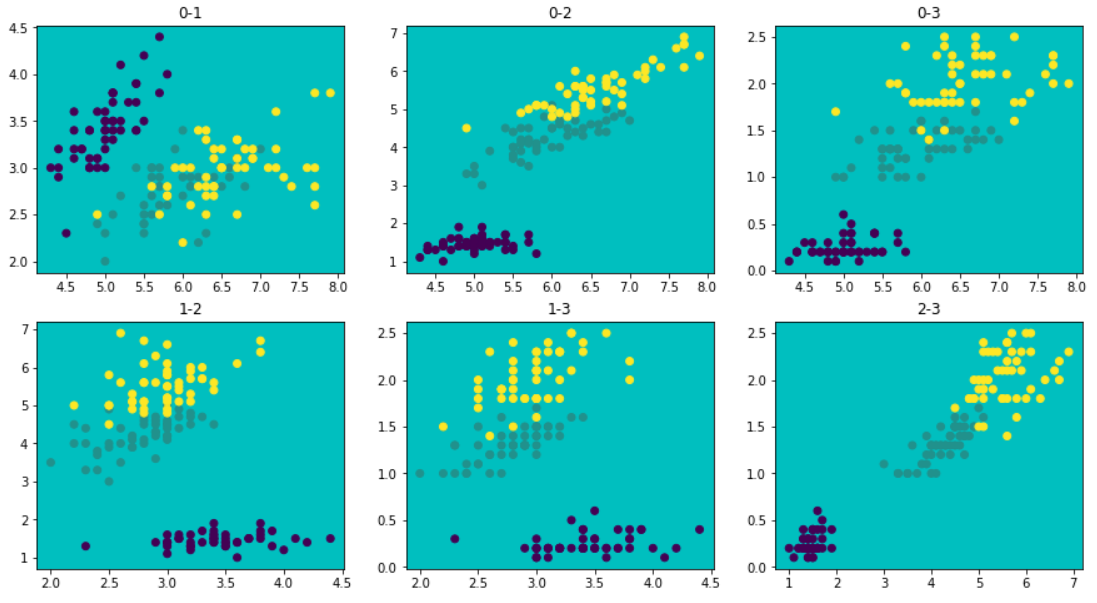
通过上面的图片,可以看出使用特征值0和1、1和3画散点图时会有重叠,其余的数据分布还可以,所以这里我们使用0和3进行画图。
接下来我们在特征0和特征3所组成的平面中,将3种不同的鸢尾花在该平面上的分布画出来。
具体步骤为:取两组特征值组成的平面的x、y轴最小值和最大值,然后在该范围内进行划分,如果每个轴划分1000份,则可以形成1000*1000个点。接着使用特征0和特征3中的值进行训练。将划分后的点代入模型中进行预测,然后获取所有点对应的花的种类,最后将种类作为颜色,画在平面上。代码如下:
# 先生成两个线段上的范围
x, y = np.linspace(data[:,0].min(), data[:,0].max(), 1000), np.linspace(data[:,3].min(), data[:,3].max(), 1000)
# 范围拉起来形成2维平面
X, Y = np.meshgrid(x,y)
# 两个平面上相交的点
XY = np.c_[X.ravel(), Y.ravel()]
# 使用特征0和3中的数据进行训练
knn = KNeighborsClassifier()
knn.fit(data[:,(0,3)], target)
# 将划分好的所有点代入模型中进行种类预测
# y_中为每个点对应的种类
y_ = knn.predict(XY)
# 将数据展示出来
plt.pcolormesh(X, Y, y_.reshape(1000,1000))
plt.scatter(data[:,0],data[:,3],c=target,cmap='rainbow')
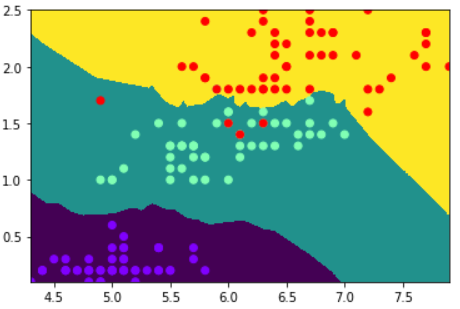
步骤总结:
当前有癌症数据,其有32列,第0列和第1列分别为患者的id和癌症的最终检测结果(分为良性B和恶性的M),剩下的30列为判断癌症良性或恶性的特征数据,我们分别取出从第二列到最后列所有的数据作为特征数据,第一列为对应的标签。由于我们不能自己生成测试数据和标签,所以需要对原始数据使用train_test_split进行随机切分。
from sklearn.model_selection import train_test_split
data = cancer.iloc[:, 2:]
target = cancer.Diagnosis
# 数据切分
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=69)
# 模型建立与训练
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
# 数据预测
y_ = knn.predict(X_test)
# 模型得分
knn.score(X_train, y_train)
knn.score(X_test, y_test)
由于上面的模型中,特征值过多,如果只选取其中两个画散点图进行可视化展示,效果不好。这里可以使用交叉表的形式,直接在表中展示预测结果和对应真实结果,这样比直接给模型的得分更加直观。
# 对于这种不太好进行可视化展示的数据,我们可以使用交叉表.
pd.crosstab(index=y_test, columns=y_, rownames=['真实值'], colnames=['预测值'], margins=True)
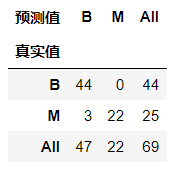
上面的交叉表中,我们行index使用了测试数据的真实标签,所以交叉表的每一行都是真实数据;而列columns我们使用了预测值,最后margins=True表示在交叉表中显示汇总数据。
具体看法,先看行,B有44个真实结果,M有25个真实结果。然后看列,模型预测了47个B和22个M。最后看对角线,其为预测正确的数据,即B预测正确44个,M预测正确22个,也即是B都预测正确了,但是M有3个预测成了B。
数据情况:
当前有手写数字测试数据,数字从0到9,每个数字有标号为1到500的图片,总共500张,每个图片都是黑白图片。我们把图片读取出来,其读取的数据为二维数据。
训练思路:
对与此数据集,每张图片都是一个二维数据,但是这个二维数据只能看做一个特征值,由于在knn中,单个训练数据只能是一维的,所以需要把这个数据转化为一维数据。同时记录该数据对应的实际数字值,此即该测试数据的测试标签。将所有的数据都读出来,并以列表的形式存储,则总共有500*10=5000个数据,每个数据对应一个数字,也即是训练数据标签,由于图片是二维的,所以最后存储的数据是3维的,而knn对与总训练数据集要求是2维的,所以要把最后的两维合并为一维,最代入进行训练。
同样由于不能自己创造测试数据和对应的标签,所以需要使用train_test_split进行切分。
data = []
target = []
for i in range(10):
for j in range(1,501):
bmp_path = './data/data/{}/{}_{}.bmp'.format(i,i,j)
temp = plt.imread(bmp_path)
data.append(temp)
target.append(i)
# 使用数组方便读取数据,转化为ndarray方便对维度进行转换
data = np.array(data)
data = data.reshape(5000,-1)
target = np.array(target)
# 切分训练数据及标签和测试数据及标签
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
y_ = knn.predict(X_test)
对上面的数据进行机器学习之后,可以抽取部分数据进行可视化。由于切分时选择的大小为test_size=0.2,而总样本个数为5000,所以测试数据个数为5000*0.2=1000。可以从这1000个测试数据中,每隔10个选择一个测试数据,画图其对应的图片,并在图片上标示对应的实际数字和预测数字。
plt.figure(figsize=(10*2, 10*3))
for i in range(100):
axes = plt.subplot(10,10,i+1)
# 测试数据X_test是2维的,需要将其中的每一个数据转为2维的。
axes.imshow(X_test[i*10].reshape(28,28), cmap='gray')
axes.axis('off')
if y_test[i*10] != y_[i*10]:
axes.set_title('True:{}\nPredict:{}'.format(y_test[i*10], y_[i*10]),fontdict=dict(color='red'))
axes.set_title('True:{}\nPredict:{}'.format(y_test[i*10], y_[i*10]))

首先生成用于训练的数据:
x = np.random.rand(100) * 10
y = np.sin(x)
plt.scatter(x,y)
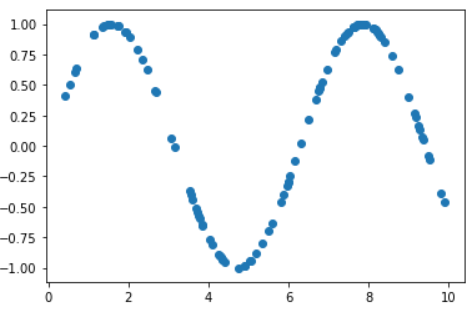
使用rand生成[0-1)之间的随机数,然后放大10倍作为训练数据X_train。然后生成对应的标签,使用sin生成。
由于上面的趋势过于明显,所以需要增加一些噪点:
# 加点噪声
y[::4] += np.random.randn(25) * 0.3
plt.scatter(x,y)
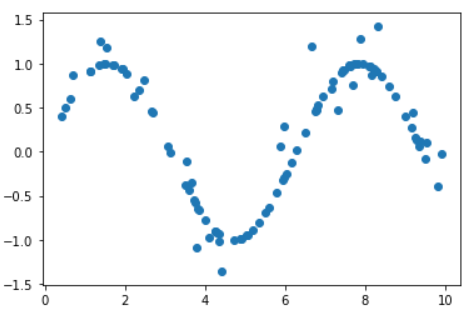
从训练数据中每4个获取一个来增加噪点,使用randn生成[-3,3]之间的标准正态分布,由于测试数据在[-1,1]之间,所以将噪点进行缩小
由于需要对趋势进行预测,这种机器学习模式区别于之前的情况,之前的训练数据的标签是不连续的,比如标签为男或者女,或标签为3种花的一种,但是现在的请是预测趋势,是连续的,所以这里不能使用之前的模型。
这里使用k-近临回归模型,使用的模块为KNeighborsRegressor。
# 导入模块
from sklearn.neighbors import KNeighborsRegressor
# 建立模型并训练
knn = KNeighborsRegressor()
knn.fit(x.reshape(-1,1), y)
# 建立测试数据
X_test = np.linspace(0, 10, 1000).reshape(-1,1)
# 对测试数据进行预测
y_ = knn.predict(X_test)
# 将原始数据和测试数据与预测结果画出来
plt.scatter(x,y)
plt.plot(X_test, y_, c='r')
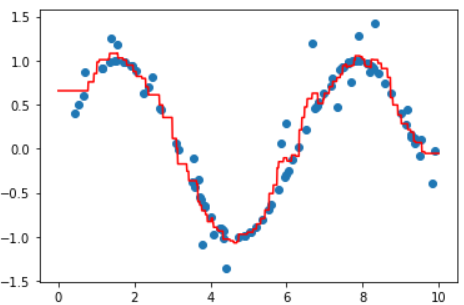
步骤总结:
在上面的章节中,使用到了模块train_test_split,该模块会根据指定的test_size参数来选择不同比例的测试数据大小和训练数据大小,而且每次都是随机选取。
但是有些时候,可能需要对整个模型进行优化,如果每次选取的训练数据不相同时,会造成优化前后的模型无法对比优劣。所以可以在其中指定随机种子。
对与随机数而言,如果不主动指定随机种子,则系统会把计算机当前的时间戳作为随机种子,而如果我们指定了随机种子,则每次生成随机数时,系统会根据该种子计算随机数。如果随机种子一样,则每次生成的随机数也是一样的。
如代码:
np.random.seed(1)
np.random.rand(1)
# 指定了随机种子之后每次随机结果都一样
输出结果为:array([0.417022])
所以为了即满足随机获取样本片段的寻求且片段一致,可以在模块train_test_split中设置随机种子参数random_state,这样每次获取的片段都是一样的。
在一些样本数据中,如果数据的特征值分布过于分散,则可能会导致训练好的模型预测数据时不准确。
此时可以将其中所有的特征值进行标准化,将所有的值更改为0-1之间的数据,这样会使得数据分布更加集中一些。
标准化的方法是,取出该列的所有数据,获取其中的最大值c_max和最小值c_min,然后将该列所有的数据v进行以下计算:(v - c_min) / (c_max - c_min),并将计算好的值赋值给原数据位置。
为此有两种实现思路:
.transform()函数,函数中传入定义好的子函数,然后将计算好的结果赋值给该列。
.transform()函数一般为对数据某一列进行操作,其会将调用该函数的数据全部传入进来。与之相似的.map()函数,他是将调用该函数的数据逐个传入进来。
所以在.transform()函数中传入的自定义函数,可以是对调用.transform()函数的所有数据进行操作,比如求最值、平均等,而.map()函数则不可以,因为其是逐个传入数据,其没有一下子获取所有数据,所以不能对调用自己的数据求最值、平均等操作。
思路一实现代码(data_new_change中存有所有要标准化的数据,数据大小为32561 rows × 9 columns):
for col in data_new_change.columns:
c_max = data_new_change[col].max()
c_min = data_new_change[col].min()
for i in range(len(data_new_change[col])):
v = data_new_change[col][i]
data_new_change[col][i] = (v-c_min)/(c_max - c_min)
思路二实现代码 #E91E63(data_new_change2中存有所有要标准化的数据,数据大小为32561 rows × 9 columns):
def normalized(x):
return (x - x.min()) / (x.max() - x.min())
for col in data_new_change2.columns:
data_new_change2[col] = data_new_change2[col].transform(normalized)
上面两个代码数据是一样的。
对两种代码的执行时间进行测试,结果如下:
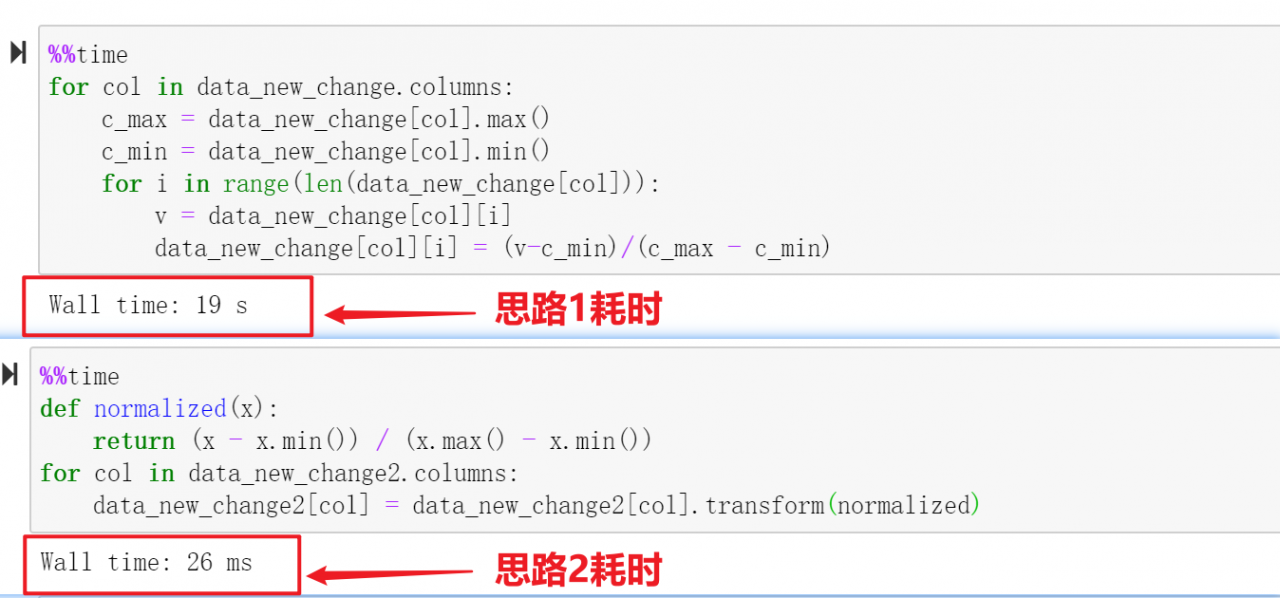
从上面的计算结果可以看到,两种代码耗时差距巨大,所以以后这种情况,建议使用思路2对应的代码。
K近临回归算法和Lasso回归在线性数据预测中的表现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import Lasso
np.random.seed(1)
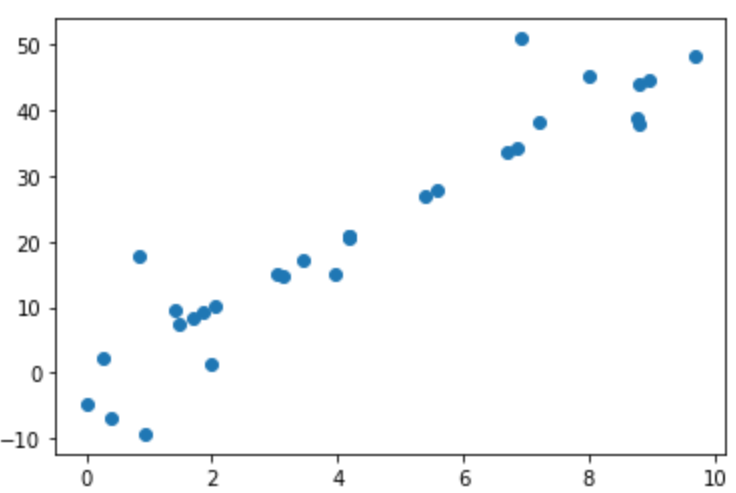
X = np.random.rand(30) * 10
y = 5 * X
index = np.arange(30)
np.random.shuffle(index,)
y[index[:15]] += np.random.randn(15) * 8
plt.scatter(X,y)
上面的代码生成的测试数据散点图如下:
对上面的数据分别使用knn中的回归算法和lasso线性算法进行训练:
x_ = np.linspace(0, 10,100).reshape(-1,1)
knn = KNeighborsRegressor()
knn.fit(X.reshape(-1,1),y)
score_knn = knn.score(X.reshape(-1,1),y)
y_knn = knn.predict(x_)
lasso = Lasso()
lasso.fit(X.reshape(-1,1),y)
score_lasso = lasso.score(X.reshape(-1,1),y)
# 计算斜率
coef_lasso = lasso.coef_
y_lasso = lasso.predict(x_)
使用两种训练好的模型对测试值进行预测,并画出预测值的图像:
plt.figure(figsize=(8,6))
plt.scatter(X,y,label='train data')
plt.plot(x_,y_lasso,c='r', label='Lasso predict(score: {:.4f}, coef: {:.2f})'.format(score_lasso,coef_lasso[0]))
plt.plot(x_,y_knn,c='g',label='Knr predict(score: {:.4f})'.format(score_knn))
plt.legend()
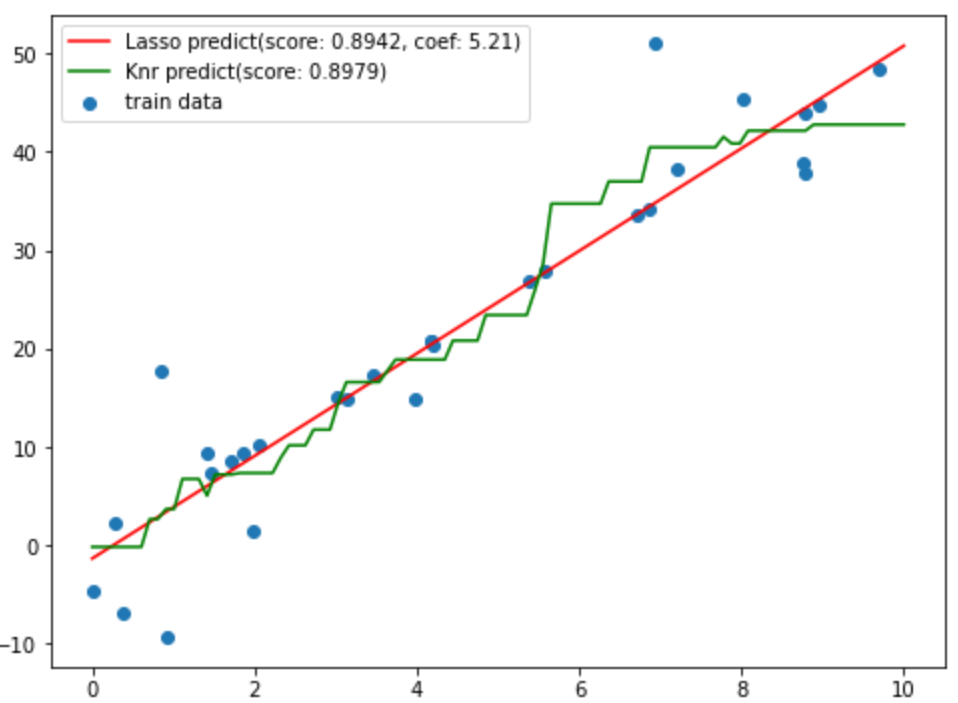
 g11023225
g11023225
 原创文章 7获赞 1访问量 48
关注
私信
展开阅读全文
原创文章 7获赞 1访问量 48
关注
私信
展开阅读全文
作者:g11023225