机器学习代码实战——KMeans(聚类)
文章目录1.实验目的2.导入必要模块3.用pandas处理数据4.拟合+预测5.把预测结果合并到DF6.可视化聚类效果7.比较不同的簇数的均方误差8.对数据归一化处理
1.实验目的
作者:程旭员
1.使用sklearn库中的鸢尾花数据集,并尝试使用花瓣的宽度和长度特征来形成簇。
2. 为简单起见,删除其他两个特征。
3. 找出是否有任何预处理(例如缩放)可以帮助解决问题,绘制肘部曲线,从中得出k的最佳值
from sklearn.cluster import KMeans #从sklearn导入KMeans算法
import pandas as pd
from sklearn.preprocessing import MinMaxScaler #数据预处理中的缩放模块
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris #从sklearn导入iris数据
%matplotlib inline
3.用pandas处理数据
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names) #构建df
df.drop(['sepal length (cm)','sepal width (cm)'],axis = 'columns',inplace = True) #只取两个特征,故把另外两个特征drop掉
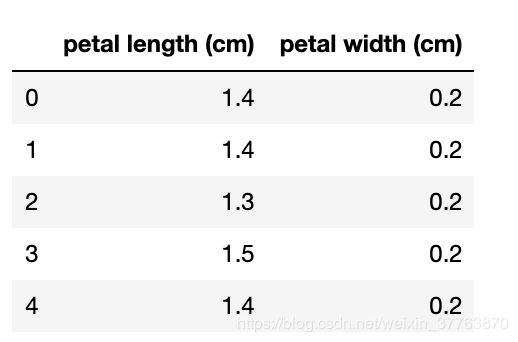
df.head() #打印前5条记录检验操作是否正确
km = KMeans(n_clusters=3) #设定超参数聚类数为3
y_predicted = km.fit_predict(df) #拟合+预测
y_predicted #打印聚类结果(0表示第1个簇,1表示第2个簇,2表示第3个簇)

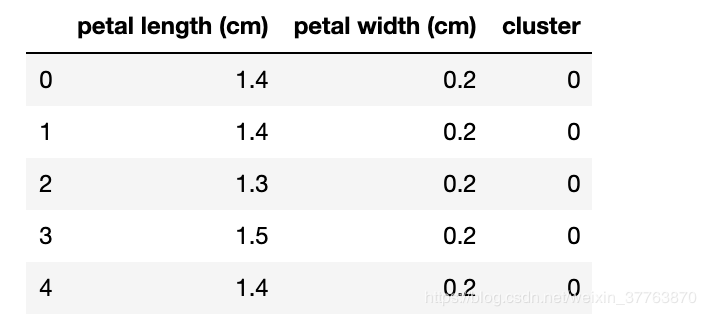
df['cluster'] = y_predicted
df.head()
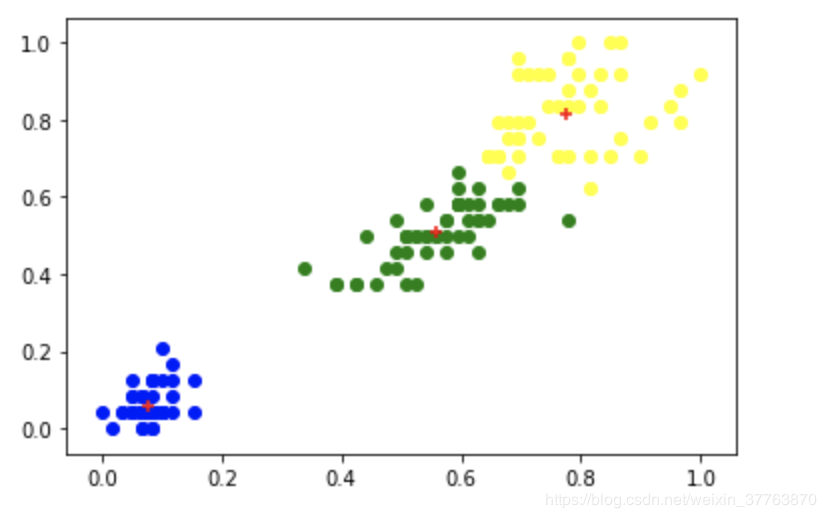
df1 = df[df.cluster==0] #过滤出簇0
df2 = df[df.cluster==1] #过滤出簇1
df3 = df[df.cluster==2] #过滤出簇2
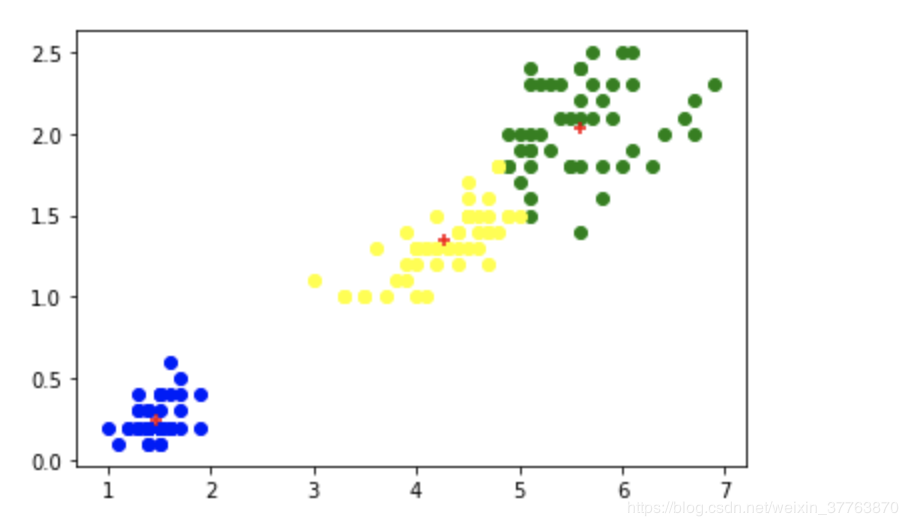
plt.scatter(df1['petal length (cm)'],df1['petal width (cm)'],color='blue') #画簇0的散点图
plt.scatter(df2['petal length (cm)'],df2['petal width (cm)'],color='green') #画簇1的散点图
plt.scatter(df3['petal length (cm)'],df3['petal width (cm)'],color='yellow') #画簇2的散点图
plt.scatter(km.cluster_centers_[:,0],km.cluster_centers_[:,1],color='red',marker='+',label='centroid') #画每个簇的中心
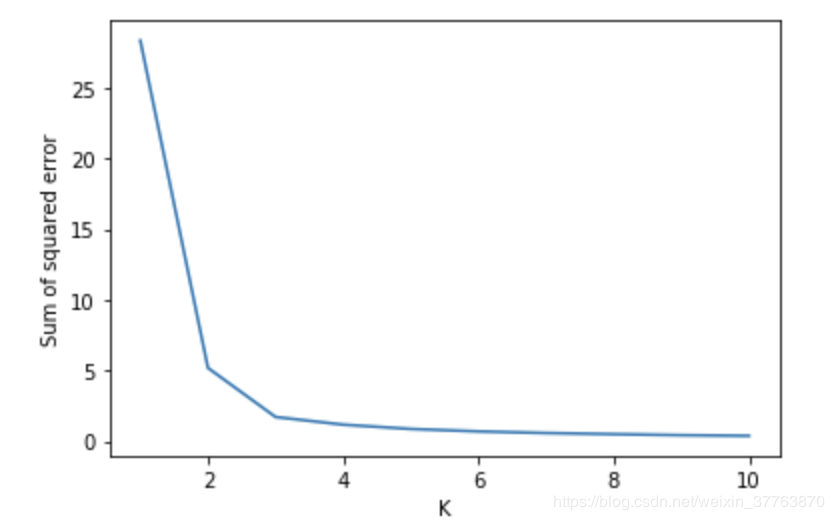
distance = []
for k in range(1,11):
km = KMeans(n_clusters=k)
km.fit(df[['petal length (cm)','petal width (cm)']])
distance.append(km.inertia_)
plt.xlabel('K')
plt.ylabel('Sum of squared error')
plt.plot(range(1,11),distance)
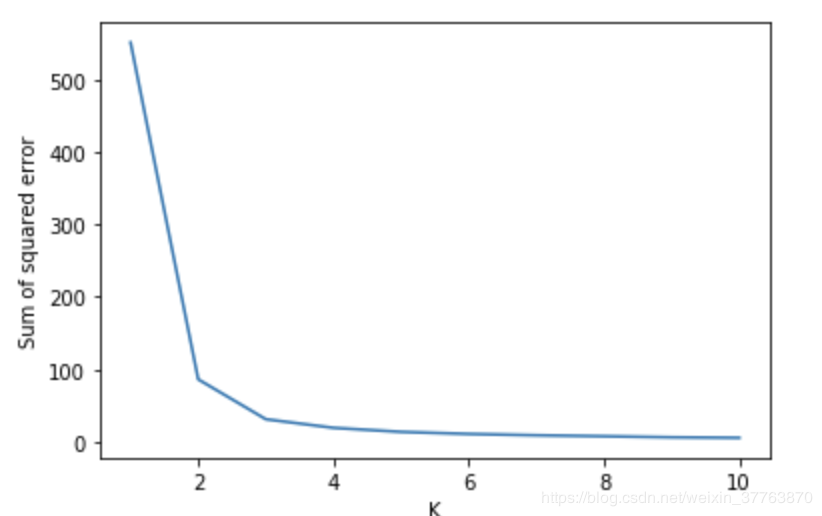
效果如图:均方误差图形像一个手臂,一般在肘部为k的最佳值。
有时,由于数据的取值范围不同会影响聚类的效果,因此在拟合数据前,我们最好对数据进行归一化。只需在步骤4前加如下代码。
scaler = MinMaxScaler()
scaler.fit(df[['petal length (cm)']]) #计算用于以后缩放的最小值和最大值
df['petal length (cm)'] = scaler.transform(df[['petal length (cm)']]) #根据feature_range缩放X的特征
scaler.fit(df[['petal width (cm)']])
df['petal width (cm)'] = scaler.transform(df[['petal width (cm)']])
效果:
作者:程旭员