#机器学习--第1章:EDA数据探索性分析
#机器学习--第1章:EDA数据探索性分析一、序言二、EDA的意义三、EDA的流程
一、序言
二、EDA的意义
作者:投笔丶从戎
本系列博客包含:数据分析、特征工程、模型训练等通用流程。将会一步一步引领大家完成一次完整的机器学习案例。点击下载 本系列博客所用数据集,提取码: r6m6。本系列使用工具:Pycharm+Python3.7.6
数据相关字段解释:
| 项目 | Value |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuel | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| createDate | 汽车上线时间,即开始售卖时间 |
| price | 二手车交易价格(预测目标) |
| v系列特征 | 匿名特征,包含v0-14在内15个匿名特征 |
在拿到数据后,首先要进行的是数据探索性分析(Exploratory Data Analysis),它可以有效的帮助我们熟悉数据集、了解数据集。初步分析变量间的相互关系以及变量与预测值之间的关系,并且对数据进行初步处理,如:数据的异常和缺失处理等,以便使数据集的结构和特征让接下来的预测问题更加可靠。
三、EDA的流程1、载入数据并简略观察数据
import numpy as np
import pandas as pd
import seaborn as sns
import missingno as msno
import scipy.stats as st
import matplotlib.pyplot as plt
train_data = pd.read_csv("二手车交易价格预测/used_car_train_20200313.csv", ' ')
# 因为 SaleID 是明显无用特征,直接筛去
del train_data['SaleID']
在Pycharm的科学计算模式下,直接点击查看train_data。
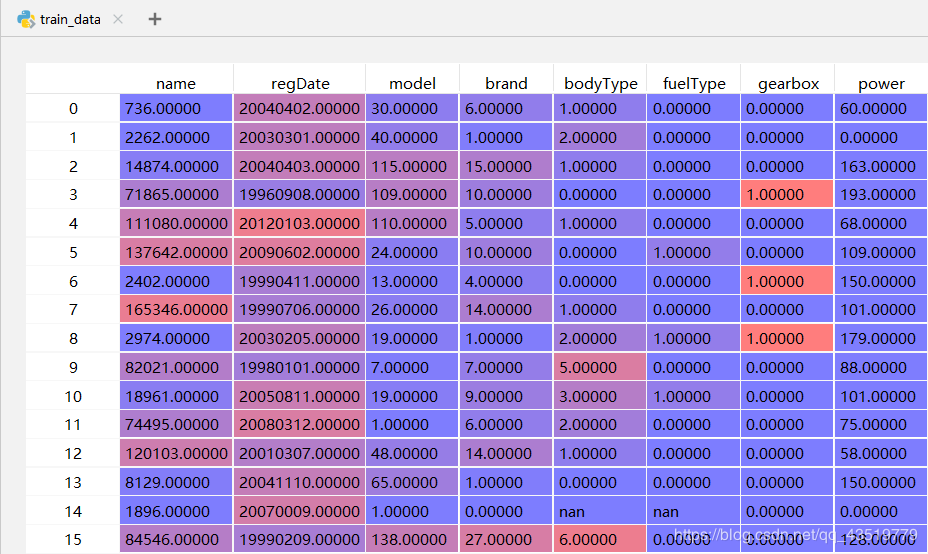
2、总览数据概况
- 在 describe 中有每一列的统计量、均值、标准差、最小值、中位数25% 50% 75%以及最大值。可以帮助我们快速掌握数据的大概范围和数据的异常判断。
- 通过 info 来了解每列的 type 有助于了解是否存在除 Nan 以外的符号异常
- 通过 isnull().sum() 查看每列缺失情况,nan 可以使用如众数、均值等进行填充,但若某一列存在过多 nan 就可以考虑将此列删除。
# 通过 info 查看数据类型
print(train_data.info())
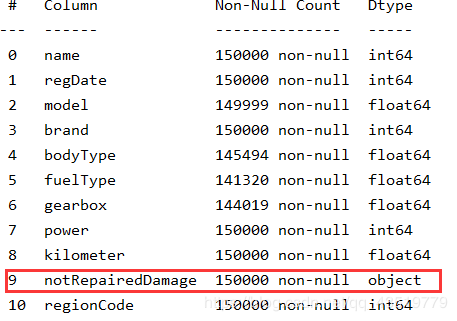
# 在这里我们可以看到除 notRepairedDamage 外其它字段的类型均为数字类型
# 因此我们可以查看一下 notRepairedDamage 的值的分布情况
print(train_data['notRepairedDamage'].value_counts())

# 在这里我们看到有一个值为 “-” ,而其它值为数字,说明这个值是无意义的,也就是 Nan
# 因此我们在这里将其替换为 -1
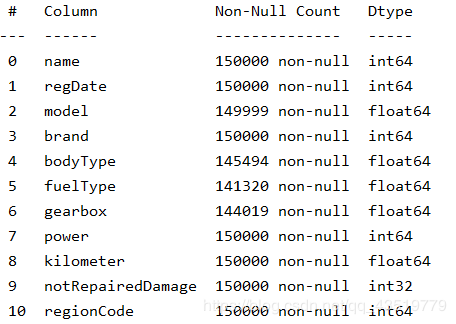
train_data['notRepairedDamage'].replace("-", -1., inplace=True)
# 因为这个数据代表车辆是否有过修里破损,因此为了后续方便,将其数据类型转化为 int32
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].astype(np.float32).astype(np.int32)
# 再次查看,已经都是数字了
print(train_data.info())
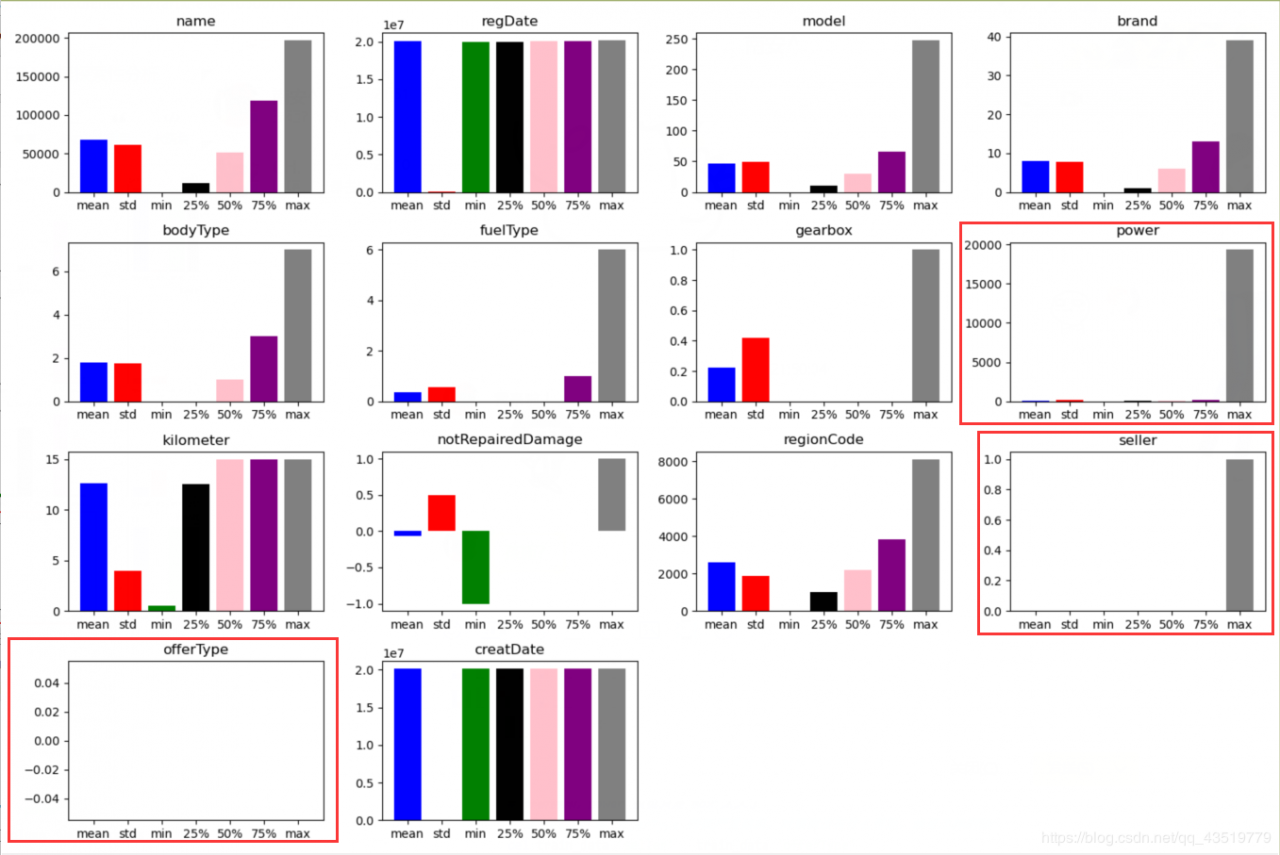
# 通过 describe 和 matplotlib 可视化查看数据的相关统计量
train_data_describe = train_data.describe()
columns = train_data_describe.columns
index = train_data_describe.index[1:]
colors = ['blue', 'red', 'green', 'black', 'pink', 'purple', 'gray', 'yellow']
plt.figure(figsize=(15, 10))
for i in range(len(columns) - 16):
ax = plt.subplot(4, 4, i + 1)
ax.set_title(columns[i])
for j in range(len(index)):
plt.bar(index[j], train_data_describe.loc[index[j], columns[i]], color=colors[j])
plt.show()
del columns, index, colors, i, j, ax
# 可以从中看到 seller 、 offerType 和 power 的数据不太正常
# 进一步查看分析 train_data_describe 得知:
# power、seller 的 mean 过于接近 min,offerType 的 mean=min=max
# 查看上述异常列的值的分布情况
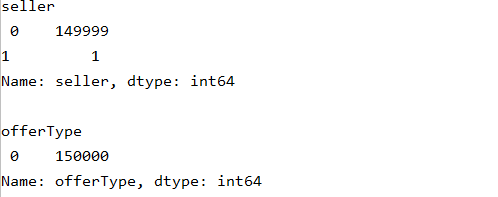
for column in ['seller', 'offerType', 'power']:
print(column + '\n', train_data[column].value_counts(), '\n')
del column
# 分析得知,power 仅仅只是 max 太大了
# 而 seller 和 offerType 特征严重倾斜,对预测没有什么帮助,故可选择删除
del train_data['seller'], train_data['offerType']
# 查看一下 nan 的分布情况
train_data['notRepairedDamage'].replace(-1, np.nan, inplace=True)
print(train_data.isnull().sum())
train_data['notRepairedDamage'].replace(np.nan, -1, inplace=True)
# 可视化查看 nan 的分布情况
msno.matrix(train_data)
plt.show()
# 如果某个特征的 nan 过多,则可选择性将其删除
# 这里我们看到虽然 notRepairedDamage 这个特征的 nan 高达 24324
# 但是直观上考虑到这个变量对于二手车价格的影响应该很大,所以这里就不删除了

3、了解预测值的分布
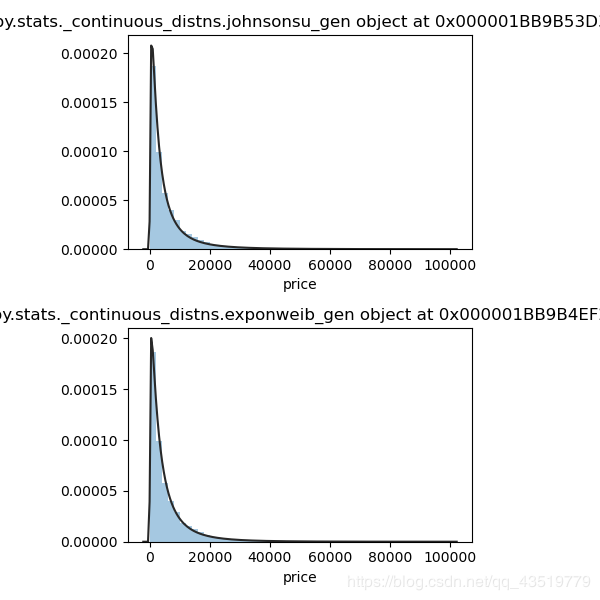
# 尝试多种方法,拟合价格分布
# 可参考 https://cloud.tencent.com/developer/ask/112712 选取合适的拟合方法
y_train = train_data['price']
fits = [st.johnsonsu, st.exponweib]
plt.figure(figsize=(6, 3 * len(fits)))
for i in range(len(fits)):
ax = plt.subplot(len(fits), 1, i+1)
ax.set_title(str(fits[i]))
sns.distplot(y_train, kde=False, fit=fits[i])
plt.show()
del fits, ax, i
# 由图可知无界约翰逊分布和 exponweib 分布拟合效果很好
# 查看价格的偏度(skewness)和峰度(kurtosis)
# 有关偏度和峰度的介绍见链接 https://blog.csdn.net/qq_36523839/article/details/88671873
print("skewness is ", y_train.skew())
print("kurtosis is ", y_train.kurt())
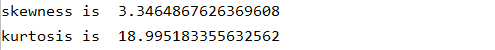
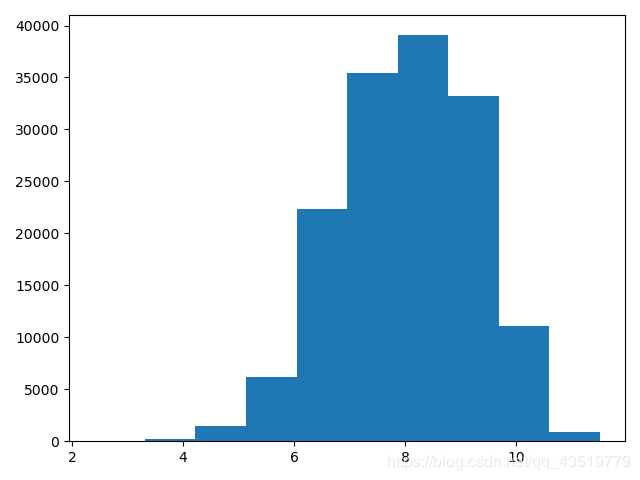
# 从上面的拟合效果中可以看出价格大致服从 exp^-1 的指数分布
# 但是由于指数分布越往后分布越稀疏,因此尝试对数据尝试进行 log 变换。
# log 变换后再次绘制频数分布图,发现,明显缩小了价格的分布区间,
# 进行某种函数变换后再进行预测,这也是预测问题常用的trick
y_train = np.log(y_train)
plt.hist(y_train)
plt.show()
作者:投笔丶从戎
相关文章
Quirita
2021-04-07
Iris
2021-08-03
Kande
2023-05-13
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20