【机器学习算法】手动Python实现KNN分类算法,并用iris数据集检验模型效果
目录一、KNN算法Python实现1、导入包2、 画图,展示不同电影在图上的分布3、训练样本和待测样本准备4、计算待测样本点到每个训练样本点的距离5、查找离待测样本点最近的K个训练样本点的类型6、找出数量最多的类7、写成自定义函数二、鸢尾花(iris)数据集测试1、导入包2、导入数据,划分数据集3、调用写好的KNN函数,并计算查准率、查全率和混淆矩阵
作者:紫雪凝香
KNN是机器学习十大算法之一,因为原理很好理解,有一句话:“Talk is cheap.Show me the code.” 所以用Python来实现一下吧,并在iris数据集上检验模型效果。
算法原理:看新样本与最接近的那个训练集样本属于哪一类,“最接近”一般是用距离来量化的。找到距离最近的K个训练样本,按“少数服从多数”原则,实现待判样本分类。
这里的距离(distance)用的是欧氏距离:
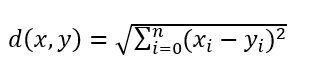
算法缺点:算法复杂度较高,因为要比较所有训练样本与待测样本;另外,当训练样本分布不均衡时,比如某一类样本占比过大,那待测样本就很容易被归为这一类,实际上可能距离并没有更接近,只是在数量上占了优势。
算法优化:所以有一个优化方法,弱化样本不平衡代来的影响,即将距离作为权重加权(weight=1/d),使得离待判样本越近的训练集样本权重越大。
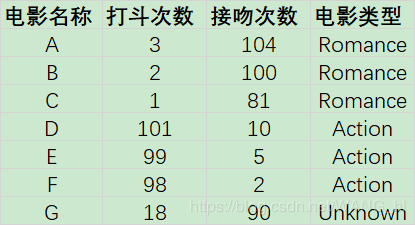
下面就是我的实现过程了。这个例子是根据电影的打斗次数和接吻次数来划分电影类型。
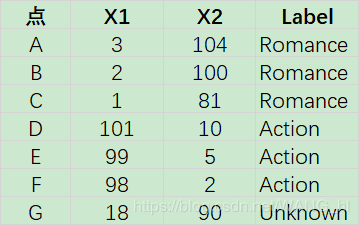
调整调整一下:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
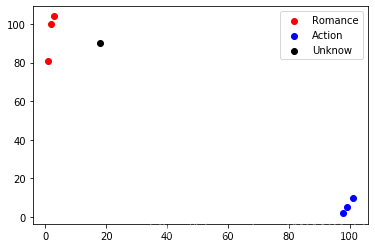
2、 画图,展示不同电影在图上的分布
#画图
x1 = np.array([3,2,1])
y1 = np.array([104,100,81])
x2 = np.array([101,99,98])
y2 = np.array([10,5,2])
s1 = plt.scatter(x1,y1,c='r')
s2 = plt.scatter(x2,y2,c='b')
#未知电影
x = np.array([18])
y = np.array([90])
s3 = plt.scatter(x,y,c='k')
plt.legend(handles=[s1,s2,s3],labels=['Romance','Action','Unknow'],loc='best')
plt.show()
#定义训练样本,x有两个特征值
x_data = np.array([
[3,104],
[2,100],
[1,81],
[101,10],
[99,5],
[81,2]
])
#y为标签
y_data = np.array(['Romance','Romance','Romance','Action','Action','Action'])
#要测试的电影类型数据
x_test = np.array([18,90])
4、计算待测样本点到每个训练样本点的距离
#因为有6个训练样本,需要计算待测样本到6个训练样本点的距离
((np.tile(x_test,(x_data.shape[0],1))-x_data)**2).sum(axis=1) # (xi-x)^2+(yi-y)^2
#求出测试点到每个点的距离
distances = (((np.tile(x_test,(x_data.shape[0],1))-x_data)**2).sum(axis=1))**0.5 #sqr((xi-x)^2+(yi-y)^2)
sort_distances = distances.argsort() #对距离按下标排序
5、查找离待测样本点最近的K个训练样本点的类型
k值的选取在这里是随便选的,实际情况需要根据模型效果多次调整。
k = 5 #设置K近邻的k为5
classcount = {}
#取前5个,求每一类的数量
for i in range(k):
votlabel = y_data[sort_distances[i]]
classcount[votlabel] = classcount.get(votlabel,0)+1
classcount
结果:
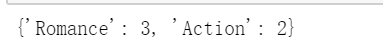
#找出数量最多的类
max_k=''
max_v=0
for k,v in classcount.items():
if v>max_v:
max_v = v
max_k = k
print(max_k)
7、写成自定义函数
#x_data:训练样本特征值;
#y_data:训练样本标签(类型);
#x_test:待判样本;
#K:最近邻选择的样本点
#返回预测类型
def knn(x_test,x_data,y_data,k):
#计算样本数量
x_data_size = x_data.shape[0]
# 复制x_test
np.tile(x_test,(x_data_size,1))
# 计算x_test与每个样本的差值
diffMat = np.tile(x_test,(x_data_size,1))-x_data
# 计算差值的平方
sqDiffMat = diffMat**2
# 求和
sqDistances = sqDiffMat.sum(axis=1)
# 开方
distances = sqDistances**0.5
# 从小到大排序
sortedDistances = distances.argsort()
classCount = {}
for i in range(k):
# 获取标签
votelabel = y_data[sortedDistances[i]]
# 统计标签数量
classCount[votelabel] = classCount.get(votelabel,0)+1
# 找出数量最多的标签
max_k = ''
max_v = 0
for k,v in classCount.items():
if v > max_v:
max_v = v
max_k = k
return(max_k)
二、鸢尾花(iris)数据集测试
1、导入包
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split #数据切分
from sklearn.metrics import classification_report,confusion_matrix #查准率、查全率、混淆矩阵
import random
2、导入数据,划分数据集
#载入数据
iris = datasets.load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris,iris.target,test_size = 0.2)
如果不想用自带的train_test_split()方法划分数据集,可以自己写,代码如下:
#由于鸢尾花数据都是按类别排列好了的,现在需要打乱数据
#相当于x_train,x_test,y_train,y_test = train_test_split(iris,iris.target,test_size = 0.2) 实现的功能
data_size = iris.data.shape[0]
index = [i for i in np.arange(data_size)]
random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index]
#切分数据集
test_size = int(data_size * 0.2)
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size]
3、调用写好的KNN函数,并计算查准率、查全率和混淆矩阵
prediction = []
#调用knn(x_test,x_data,y_data,k)函数
for i in range(x_test.shape[0]):
prediction.append(knn(x_test[i],x_train,y_train,5))
print(classification_report(y_test,prediction))
print(confusion_matrix(y_test,prediction))
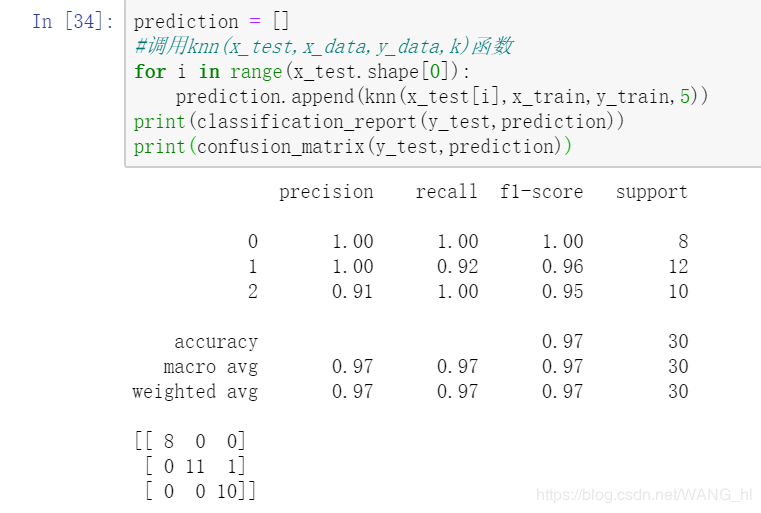
好像效果还不错的样子,继续加油↖(ω)↗
完
作者:紫雪凝香