机器学习(九)基于SVM的上证指数涨跌预测
数据介绍:
网易财经上获得的上证指数的历史数据,爬取了20年的上证指数数据。
实验目的:
根据给出当前时间前150天的历史数据,预测当天上证指数的涨跌。
技术路线:sklearn.svm.SVC
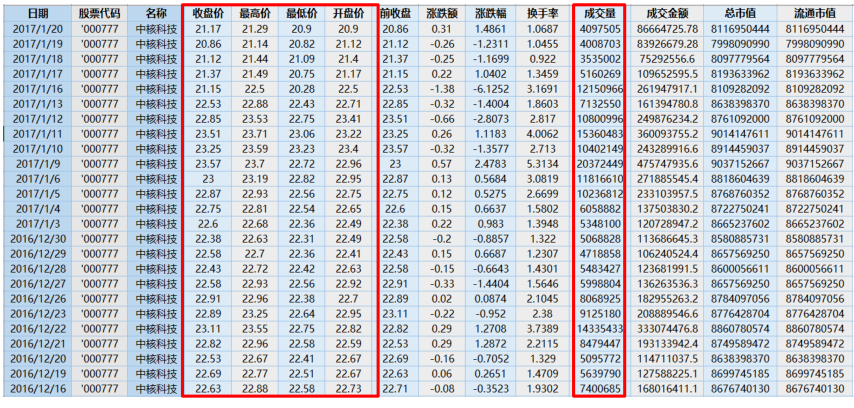
数据实例:中核科技1997年到2017年的股票数据部分截图,红框部分为选取的特征值
--------------------------------------
特征&标签的区别:
在周志华的《机器学习》中判断是否正熟的好瓜,首先会从西瓜这个具体的事物中抽取一些有用的信息,西瓜的颜色、瓜蒂的形状、敲击的声音就是特征,而“好瓜”和“坏瓜”这两个判断就是标签。更抽象一点,特征是做出某个判断的证据,标签是结论。
关于一些相关包的介绍:
pandas:用来加载CSV数据的工具包
numpy:支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
sklearn下svm:SVM算法
sklearn下cross_validation:交叉验证
import pandas as pd
import numpy as np
from sklearn import svm
from sklearn import cross_validation
2)数据加载&数据预处理
参数解释1(上段):读入数据
pd:pandas包的实例参数
read_csv( ): 详细解释 (http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html)
pandas.read_csv(数据源, encoding=编码格式为gbk, parse_dates=第0列解析为日期,index_col=用作行索引的列编号)
sort_index( ): 详细解释( http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_index.html )
DataFrame.sort_index(axis=0 (按0列排), ascending=True(升序), inplace=False(排序后是否覆盖原数据))data 按照时间升序排列
-------------------------------------
参数解释2(下段):
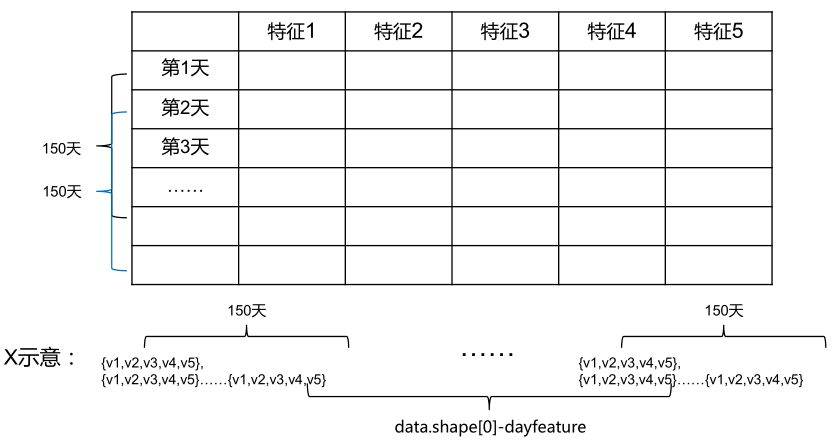
选取5列数据作为特征:收盘价 最高价 最低价 开盘价 成交量
dayfeature:选取150天的数据
featurenum:选取的5个特征*天数
x:记录150天的5个特征值
y:记录涨或者跌
data.shape[0]-dayfeature意思是因为我们要用150天数据做训练,对于条目为200条的数据,只有50条数据是有前150天的数据来训练的,所以训练集的大小就是200-150, 对于每一条数据,他的特征是前150天的所有特征数据,即150*5, +1是将当天的开盘价引入作为一条特征数据
data=pd.read_csv('stock/000777.csv',encoding='gbk',parse_dates=[0],index_col=0)
data.sort_index(0,ascending=True,inplace=True)
dayfeature=150
featurenum=5*dayfeature
x=np.zeros((data.shape[0]-dayfeature,featurenum+1))
y=np.zeros((data.shape[0]-dayfeature))
参数解释:
u:unicode编码
reshape:转换成1行,featurenum列
ix :索引
for i in range(0,data.shape[0]-dayfeature):
#/将数据中的“收盘价”“最高价”“开盘价”“成交量”存入x数组中
#u:unicode编码 reshape:转换成1行,featurenum列
x[i,0:featurenum]=np.array(data[i:i+dayfeature]\
[[u'收盘价',u'最高价',
u'最低价',u'开盘价',u'成交量']]).reshape((1,featurenum))
x[i,featurenum]=data.ix[i+dayfeature][u'开盘价']
#最后一列记录当日的开盘价 ix :索引
for i in range(0,data.shape[0]-dayfeature):
if data.ix[i+dayfeature][u'收盘价']>=data.ix[i+dayfeature][u'开盘价']:
y[i]=1
else:
y[i]=0
#如果当天收盘价高于开盘价,y[i]=1代表涨,0代表跌
3)创建SVM并进行交叉验证
#创建SVM并进行交叉验证
clf =svm.SVC(kernel='rbf')
#调用svm函数,并设置kernel参数,默认是rbf,其它:‘linear’‘poly’‘sigmoid’
result =[]
for i in range(5):
#x和y的验证集和测试集,切分80 - 20 % 的测试集
x_train,x_test,y_train,y_test =\
model_selection.train_test_split(x,y,test_size=0.2)
#训练数据进行训练
clf.fit(x_train,y_train)
#将预测数据和测试集的验证数据比对
result.append(np.mean(y_test ==clf.predict(x_test)))
print("svm classifier accuacy:")
print(result)
4)全部代码
#用来加载CSV数据的工具包
import pandas as pd
#:支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
import numpy as np
#sklearn下svm:SVM算法
from sklearn import svm
# sklearn下cross_validation:交叉验证
from sklearn import model_selection
#parse_dates=第0列解析为日期, index_col= 用作行索引的列编号)
data =pd.read_csv(r'C:\Users\86493\Desktop\北理工机器学习慕课数据\分类\stock\000777.csv',encoding='gbk',parse_dates=[0],index_col=0)
#DataFrame.sort_index(axis=0 (按0列排), ascending=True(升序),
#inplace=False(排序后是否覆盖原数据))data 按照时间升序排列
data.sort_index(0,ascending=True,inplace=True)
#选取5列数据作为特征:收盘价 最高价 最低价 开盘价 成交量
#dayfeature:选取150天的数据
#featurenum:选取的5个特征*天数
#x:记录150天的5个特征值 y:记录涨或者跌
dayfeature=150
featurenum =5*dayfeature
#data.shape[0]-dayfeature意思是因为我们要用150天数据做训练,
# 对于条目为200条的数据,只有50条数据是有前150天的数据来训练的,
# 所以测试集的大小就是200-150, 对于每一条数据,他的特征是前150天的所有特征数据,
# 即150*5, +1是将当天的开盘价引入作为一条特征数据
x=np.zeros((data.shape[0]-dayfeature,featurenum+1))
y=np.zeros((data.shape[0]-dayfeature))
for i in range(0,data.shape[0]-dayfeature):
#/将数据中的“收盘价”“最高价”“开盘价”“成交量”存入x数组中
#u:unicode编码 reshape:转换成1行,featurenum列
x[i,0:featurenum]=np.array(data[i:i+dayfeature]\
[[u'收盘价',u'最高价',
u'最低价',u'开盘价',u'成交量']]).reshape((1,featurenum))
x[i,featurenum]=data.ix[i+dayfeature][u'开盘价']
#最后一列记录当日的开盘价 ix :索引
for i in range(0,data.shape[0]-dayfeature):
if data.ix[i+dayfeature][u'收盘价']>=data.ix[i+dayfeature][u'开盘价']:
y[i]=1
else:
y[i]=0
#如果当天收盘价高于开盘价,y[i]=1代表涨,0代表跌
#创建SVM并进行交叉验证
clf =svm.SVC(kernel='rbf')
#调用svm函数,并设置kernel参数,默认是rbf,其它:‘linear’‘poly’‘sigmoid’
result =[]
for i in range(5):
#x和y的验证集和测试集,切分80 - 20 % 的测试集
x_train,x_test,y_train,y_test =\
model_selection.train_test_split(x,y,test_size=0.2)
#训练数据进行训练
clf.fit(x_train,y_train)
#将预测数据和测试集的验证数据比对
result.append(np.mean(y_test ==clf.predict(x_test)))
print("svm classifier accuacy:")
print(result)
5)结果分析
==搞了半天这个代码运行出错,cross_validation改成model_selcetion后也不行。。有时间再来收拾。。
正常应该输入如下:
svm classifier accuacy:
[0.5635179153094463,0.5754614549402823, 0.5266015200868621, 0.5450597176981542, 0.5407166123778502]

(3)交叉验证
1)基本思想:
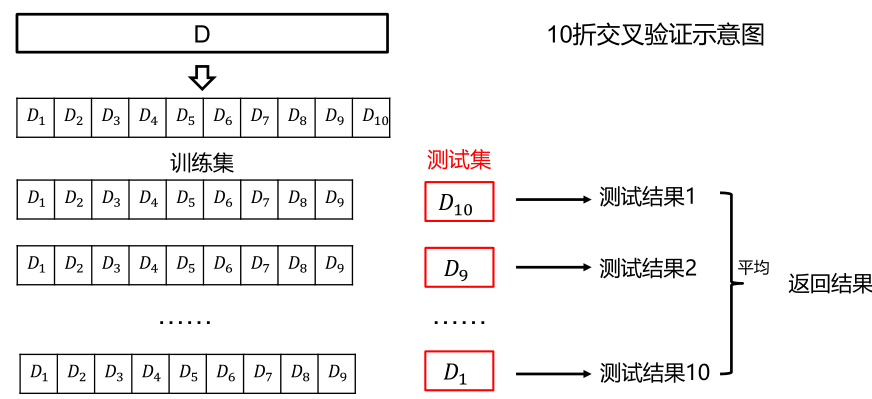
交叉验证法先将数据集D划分为k个大小相似的互斥子集,每个自己都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集;这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这个k个测试结果的均值。通常把交叉验证法称为“k者交叉验证”, k最常用的取值是10,此时称为10折交叉验证。
2)10折交叉验证示意图
作者:奇跡の山