吴恩达机器学习课后练习-ex2
所用到的文件
作者:JachinGuo
ex2.m-Octave/MATLAB脚本,该脚本引导您完成ex2
reg.m-Octave/MATLAB脚本,用于ex2data1.txt练习的后面部分-
Ex2data1.txt练习的前半部分的训练集-
ex2data2.txt练习的后半部分的训练集提交。m-提交脚本,用于将您的解决方案发送到我们的服务器
mapFeature.m-生成多项式特征的函数
plot decision boundary.m-绘制分类器决策边界的函数
[?]plot data.m-打印二维分类数据的函数
[?]sigmoid.m-sigmoid功能
[?]costFunction.m-Logistic回归成本函数
**[?]predict.m-**逻辑回归预测函数
[?]costFunctionReg.m-正规化逻辑回归成本
在整个练习中,您将使用脚本ex2.m和ex2 reg.m。这些脚本为问题设置数据集,并调用要编写的函数。你不需要修改它们中的任何一个。您只需按照此分配中的说明修改其他文件中的函数
在这部分练习中,您将建立一个logistic回归模型来预测学生是否被大学录取。
假设你是一所大学的系主任,你想根据每个申请者在两次考试中的成绩来决定他们的入学机会。您有以前申请者的历史数据,可以用作逻辑回归的训练集。对于每个培训示例,您都有申请者在两次考试中的分数和入学决定。
你的任务是建立一个分类模型,根据这两次考试的分数来估计申请者的录取概率。这个大纲和ex2.m中的框架代码将指导您完成这个练习。
1.1可视化数据
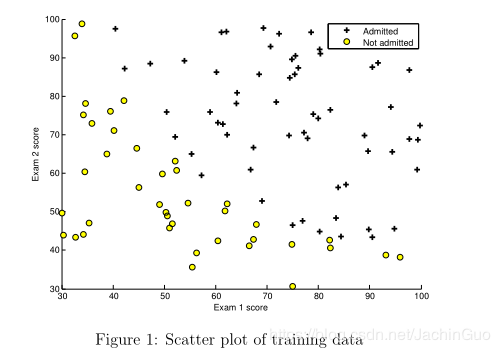
在开始实现任何学习算法之前,如果可能的话,最好将数据可视化。在ex2.m的第一部分中,代码将加载数据并通过调用函数plot data将其显示在二维图上。
现在,您将在plotData中完成代码,以便它显示如图1所示的图形,其中轴是两个考试分数,正数和负数示例用不同的标记显示
为了帮助您更熟悉绘图,我们将plotData.m保留为空,以便您可以自己尝试实现它。但是,这是一个可选(未分级)练习。我们还提供了下面的实现,以便您可以复制它或参考它。如果您选择复制我们的示例,请参考Octave/MATLAB文档,确保您了解它的每个命令的作用
```python
% Find Indices of Positive and Negative Examples
pos = find(y==1); neg = find(y == 0);
% Plot Examples
plot(X(pos, 1), X(pos, 2), 'k+','LineWidth', 2, ...
'MarkerSize', 7);
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y', ...
'MarkerSize', 7);
## 1.2实施
### 1.2.1热身练习:sigmoid函数
在开始使用实际成本函数之前,请记住,逻辑回归假设定义为:
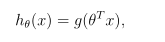
其中函数g是sigmoid的函数。sigmoid函数定义为:
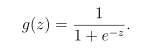
第一步是在sigmoid.m中实现这个函数,这样程序的其余部分就可以调用它了。完成后,通过在Octave/MATLAB命令行调用sigmoid(x),尝试测试一些值。对于x的大正值,sigmoid应该接近1,而对于大负值,sigmoid应该接近0。评估sigmoid(0)应该正好给你0.5。您的代码还应该使用向量和矩阵。对于矩阵,你的函数应该对每个元素执行sigmoid函数。
### 1.2.2成本函数与梯度
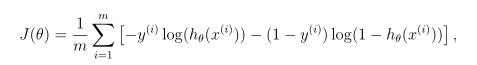
成本梯度是一个长度与θ相同的向量,其中第j个元素(对于j=0,1。. . ,n)定义如下:
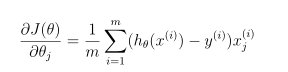
注意,虽然这个梯度看起来与线性回归梯度相同,但公式实际上是不同的,因为线性回归和logistic回归对hθ(x)有不同的定义。
完成后,ex2.m将使用θ的初始参数调用costFunction。你应该知道成本大约是0.693。
### 1.2.3使用fminunc学习参数
在上一个作业中,您通过实现梯度下降找到了线性回归模型的最佳参数。你写了一个成本函数并计算了它的梯度,然后相应地采取了梯度下降步骤。这次,您将使用一个名为fminunc的倍频程/MATLAB内置函数,而不是采取梯度下降步骤。
Octave/MATLAB的fminunc是一个优化求解器,它可以找到无约束2函数的最小值。对于logistic回归,需要使用参数θ优化成本函数J(θ)。
具体地说,在给定固定数据集(X和y值)的情况下,您将使用fminnc来找到logistic回归成本函数的最佳参数θ。您将向fminnc传递以下输入:
(1)我们试图优化的参数的初始值。
(2)当给定训练集和特定θ时,计算数据集(X,y)相对于θ的logistic回归成本和梯度的函数
在ex2.m中,我们已经编写了用正确参数调用fminunc的代码。
```python
```python
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 400);
% Run fminunc to obtain the optimal theta
% This function will return theta and the cost
[theta, cost] = ...
fminunc(@(t)(costFunction(t, X, y)), initial theta, options);
在这个代码片段中,我们首先定义了要与fminunc一起使用的选项。具体来说,我们将GradObj选项设置为on,这告诉fminunc我们的函数返回成本和梯度。这允许fminunc在最小化函数时使用梯度。此外,我们将MaxIter选项设置为400,以便fminunc在终止之前最多运行400步。
为了指定我们要最小化的实际函数,我们使用“short-hand”来指定带@(t)(costFunction(t,X,y))的函数。这将创建一个带有参数t的函数,该函数调用costFunction。这允许我们包装costFunction以用于fminunc。
如果正确地完成了costFunction,fminunc将收敛到正确的优化参数,并返回最终的cost和θ值。注意,通过使用fminunc,您不必自己编写任何循环,也不必像设置梯度下降那样设置学习速率。这都是由fminnc完成的:您只需要提供一个计算成本和梯度的函数
fminunc完成后,ex2.m将使用θ的最佳参数调用costFunction函数。你应该知道成本大约是0.203。
最后的θ值将用于在训练数据上绘制决策边界,得到类似于图2的图。我们还鼓励您查看plotDecisionBoundary.m中的代码,以了解如何使用θ值绘制这样的边界。
### 1.2.4 评价logistic回归
在学习了这些参数之后,您可以使用该模型来预测某个特定的学生是否会被录取。对于一个第一次为45分,第二次为85分的学生,你应该预计录取概率为0.776。
评估我们发现的参数质量的另一种方法是看学习的模型在我们的训练集上预测的有多好。在这个
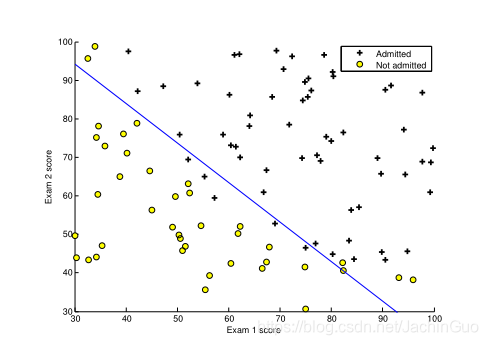
图2:具有决策边界的训练数据
部分,您的任务是完成predict.m中的代码。predict函数将在给定数据集和学习的参数向量θ的情况下生成“1”或“0”预测。
# 2.正则logistic回归
在练习的这一部分中,您将实现正则化逻辑回归,以预测来自制造工厂的微芯片是否通过质量保证(QA)。在质量保证期间,每个微芯片都要经过各种测试,以确保其正常工作。
假设你是工厂的产品经理,你有两个不同测试的一些微芯片的测试结果。从这两个测试中,您想确定是否应该接受或拒绝微芯片。为了帮助你做出决定,你有一个过去微芯片测试结果的数据集,从中你可以建立一个逻辑回归模型。7您将使用另一个脚本ex2 reg.m来完成练习的这一部分。
## 2.1可视化数据
与本练习的前面部分类似,plotData用于生成图3所示的图形,其中轴是两个测试分数,正(y=1,接受)和负(y=0,拒绝)示例用不同的标记显示。
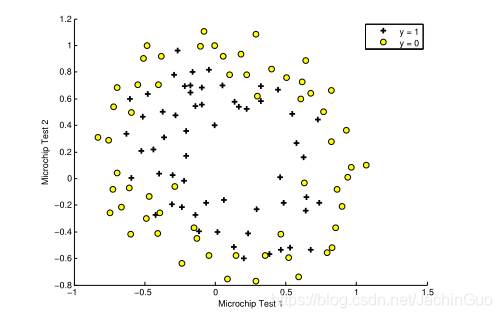
图3:训练数据图
图3显示了我们的数据集不能通过一条穿过图的直线分为正例子和负例子。因此,由于logistic回归只能找到一个线性的决策边界,因此直接应用logistic回归不能很好地处理这个数据集。
## 2.2特征映射
一种更好地拟合数据的方法是从每个数据点创建更多的特征。在提供的函数mapFeature.m中,我们将把这些特征映射到x1和x2的所有多项式项,直到第六次方。
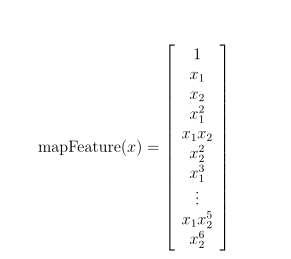
作为这个映射的结果,我们的两个特征向量(两个QA测试的分数)被转换成一个28维向量。在这个高维特征向量上训练的logistic回归分类器将具有更复杂的决策边界,并且在我们的二维图中绘制时将呈现非线性。
虽然特征映射允许我们构建一个更具表现力的分类器,但它也更容易过度拟合。在练习的下一部分中,您将实现正则化的logistic回归来拟合数据,并亲自查看正则化如何帮助解决过拟合问题。
## 2.3成本函数与梯度
现在您将实现代码来计算正则化logistic回归的成本函数和梯度。完成costFunctionReg.m中的代码以返回成本和梯度
回顾一下logistic回归中的正则化成本函数是
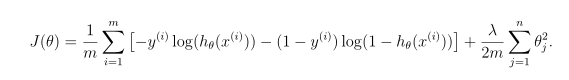
注意,不应该正则化参数θ0。在Matlab中,记得索引从1开始,因此,不应该规范代码中的θ(1)参数(对应于θ0)。成本函数的梯度是一个向量,其中jt定义如下:
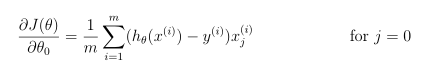
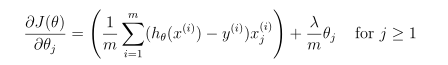
完成后,ex2 reg.m将使用θ的初始值(初始化为所有零)调用costFunctionReg函数。你应该知道成本大约是0.693。
### 2.3.1使用fminunc学习参数
与前面的部分类似,您将使用fminunc来学习最佳参数θ。如果您正确地完成了正则化logistic回归(costFunctionReg.m)的成本和梯度,那么您应该能够使用fminnc逐步了解ex2 reg.m的下一部分以了解参数θ。
## 2.4绘制决策边界
为了帮助您可视化这个分类器所学习的模型,我们提供了函数plotDecisionBoundary.m,它绘制(非线性)决策边界,该边界将正反两个示例分开。在plot decision boundary.m中,我们通过在等距网格上计算分类器的预测来绘制非线性决策边界,然后绘制预测从y=0变为y=1的等高线图。
在学习参数θ之后,ex reg.m中的下一步将绘制一个类似于图4的决策边界。
## 2.5 可选(未分级)练习
在本部分练习中,您将尝试为数据集设置不同的正则化参数,以了解正则化如何防止过度拟合。
注意当你改变λ时决策边界的变化。使用一个小的λ,您会发现分类器几乎可以正确地获取每个训练示例,但是会绘制一个非常复杂的边界,从而过度拟合数据(图5)。这不是一个好的决策边界:例如,它预测x=(-0.25,1.5)处的一个点被接受(y=1),考虑到训练集,这似乎是一个错误的决策。
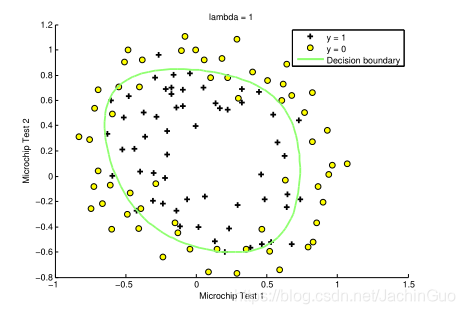
图4:具有决策边界的训练数据(λ=1)
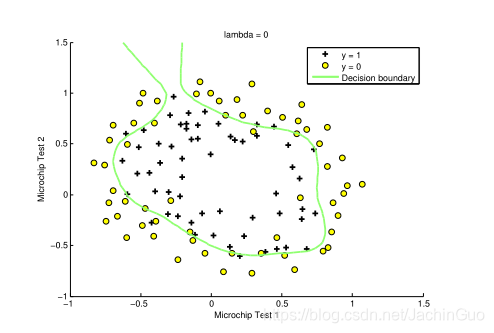
图5:无正则化(过度拟合)(λ=0)
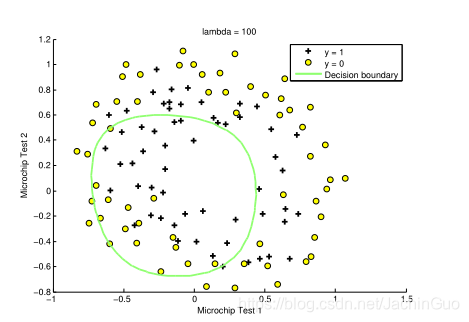
图6:过多的正则化(不适合)(λ=100)
作者:JachinGuo
相关文章
Quirita
2021-04-07
Iris
2021-08-03
Tania
2020-03-07
Jessica
2020-10-10
Kande
2023-05-13
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20