第十二章-SVM支持向量机 深度之眼_吴恩达机器学习作业训练营
目录
一,优化目标
1.1 从逻辑回归到SVM
1.1.1 回顾逻辑回归算法
1.1.2 损失项变换
1.1.3 正则化变换
1.1.4 假设函数变换
1.2 最大间隔
1.2.1 直觉上理解
1.2.2 最大间隔的数学原理
二, 核函数
2.1 高斯核函数
2.2 其他核函数
三,SVM的使用建议
3.1 超参数
3.2 核函数的选择以及训练
3.3 多分类问题
一,优化目标支持向量机(Support Vector Machines,简称SVM)是一个非常强大且广泛运用与工业界和学术界的算法,其为学习复杂的非线性方程提供了一直清晰且强大的方法。其即可用于分类问题,又可稍加变形运用到回归问题中,本章主要从分类问题着手,从逻辑回归算法“演变”到SVM。
1.1 从逻辑回归到SVM本节中,我们首先回顾逻辑回归算法,然后再通过“3步变换”,得出SVM算法。
1.1.1 回顾逻辑回归算法研究任何一个算法,首要的就是确定其优化目标,也就是常说的损失函数。这里我们先回顾逻辑回归的目标函数与损失函数:
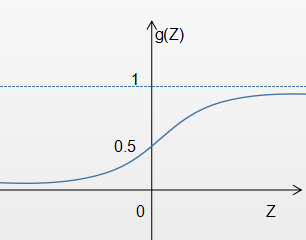
在逻辑回归中h(X)一直可被理解为样本 X的标签y=1的概率,当 θX越大,概率越接近1;当 θX越小,概率越接近0。再来观察损失函数,当样本X的真实标签Y为1或为0时损失函数分别如图12-2和图12-3所示。
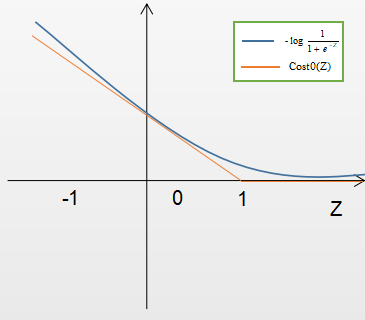
当y=1时:如果Z越大相应的预测为1的概率越大,则损失值越小;反之如果Z越小相应的预测为1的概率越小,则损失值越大。
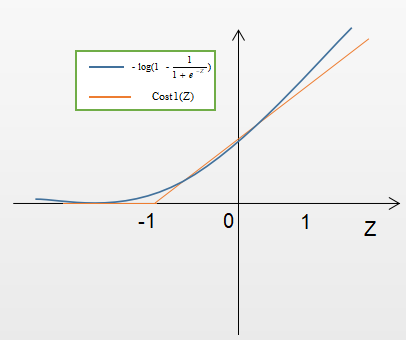
当y=0时:如果Z越大相应的预测为1的概率越大,则损失值越大;反之如果Z越小相应的预测为1的概率越小,则损失值越小。
1.1.2 损失项变换在SVM中,我们将公式9.1中的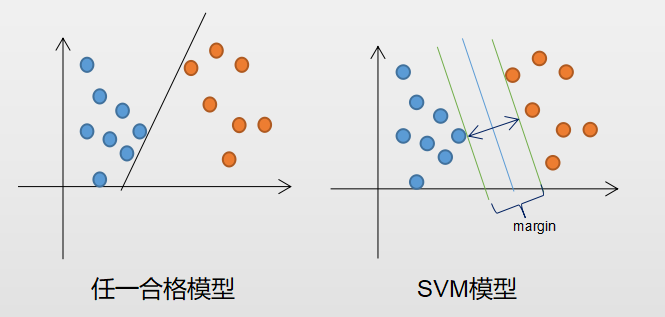
回顾假设函数(公式 12.3),可知模式以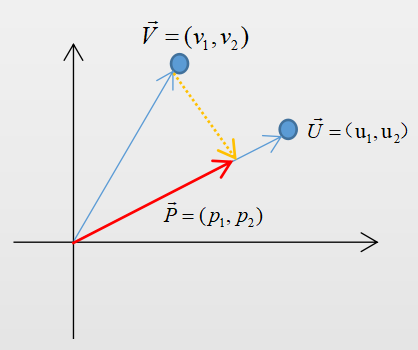
首先需要了解一个前提知识:向量投影。任意一个N维向量可与N维空间中的一个点相对应,如图12-5中,向量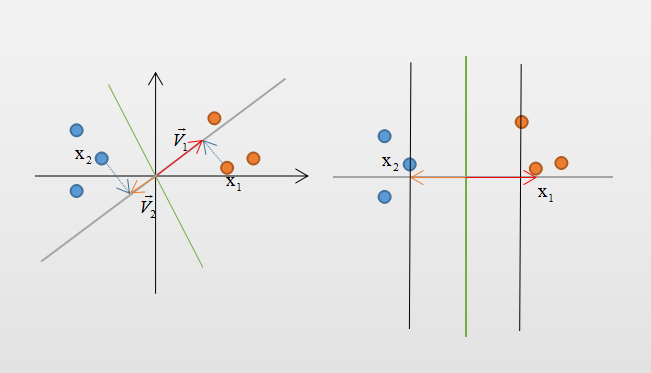
当数据非线性可分时我们可改变决策边界的表达式,但在SVM中还有更好的方法---核函数。核函数可将已有的数据特征映射到更高维度的空间中,使得存在一个超平面能将样本进行划分。核函数的种类很多,这里介绍常用的高斯核函数。
2.1 高斯核函数在N维空间中选定k个地标(landmarks) 假设训练出结果为 由上可知,地标的选择非常重要。这里介绍一种简单的选择方法,即在训练样本中每个原样本所在位置处复制出一个一模一样的地标。假设有m个实例,则会将原数据映射到m维空间中,最后通过训练可知一些特征所对应的参数θ较小甚至为0,表明其对分类不重要可删去。 同时超参数 除了高斯核函数以外还有一些其他的常用核函数,例如: 回顾上文,已知有2个超参数 假设特征数为n,样本数为m,则有以下的使用准则: 在训练SVM时,最好选择合适的高级优化软件库而非自己实现,这时要求所选的核函数满足Mercer‘s定理才能被正确的优化。 还需要注意的一点是当使用核函数时,损失函数中的正则化项 对于多分类问题,同样可以采取在介绍逻辑回归时所采用的训练出多个二分类模型的方法。假设一个有K个类,则训练出K个二分类SVM,一个对应一个类别即可。 同时也可直接采用有关SVM的软件包,其中有内置的多分类功能。 四,总结 本章主要讲解了SVM的相关知识具体有: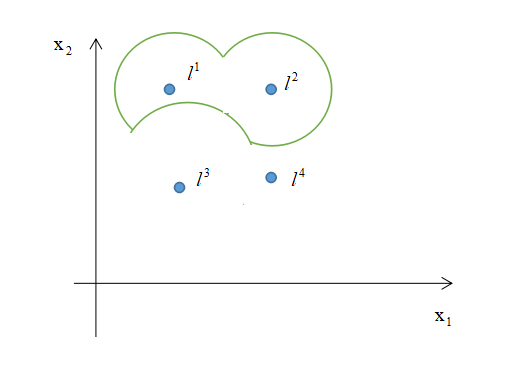
。则表明当样本越解决地标
时越可能是正类,越接近地标
时,越可能是负类,地标
对分类无影响,且远离这些地标时默认为负类。综上所述可得图中绿色的决策边界,边界以内为正类,边界以外为负类。于是乎通过从高斯核函数可得到如图中这般复杂的决策边界。
也会对训练造成一定的麻烦,当
较大时,可能会导致低方差,高偏差;当
较小时,可能会导致低偏差,高方差。
和
![]() 会影响最终结果需要了解的是。
会影响最终结果需要了解的是。较大时,可能会导致低方差,高偏差;当
较小时,可能会导致低偏差,高方差。
当C较大时,相当于λ较小,容易导致过拟合,高方差;当C较小时,相当于λ较大,容易导致欠拟合,高偏差。
3.2 核函数的选择以及训练
 需要修改为
需要修改为![]() ,其中M为根据具体核函数而定了一个矩阵,其原因是为了简化计算。
,其中M为根据具体核函数而定了一个矩阵,其原因是为了简化计算。
作者:凡尘一人