金融科技之高效办公(一):自动生成信托计划说明书
计算机极大地提高了人们的工作效率,但除了使用市场上成熟的软件外,金融业还有根据实际业务需要,自行编写提高办公效率的小工具的需求。
昨天下午实习公司给了个任务,说是比较着急:根据两个word文件段落的映射关系自动生成信托计划说明书。具体来讲,一个文件是尽调报告,里面有业务参与方的相关信息,信息按照特定的模板填入。另一个文件是计划说明书,也有特定的模板。
(所以这个项目其实没有太多内容,就是用Python将一个word文件中的指定段落复制到另一个word文件中指定位置。)
尽调报告:

说明书:

映射表:
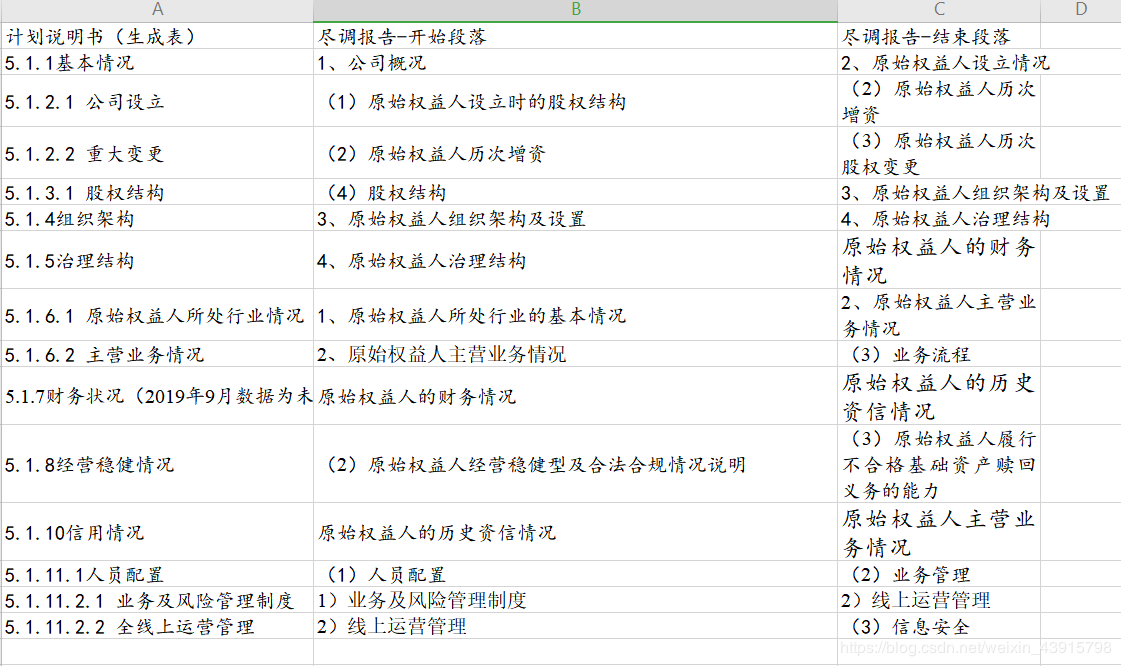
之前都是员工人工进行复制、粘贴,但公司体量较大,每天都要处理大量的合同,所以需要编写一个根据映射关系自动生成计划说明书的程序来提高办公效率。
编写最终通过查资料,最终利用Python-docx库开发了一个可以将A文件中两个段落之间的内容(包括文字和表格)复制到B文件指定段落的后的程序。
因为第一次接触Python-docx,对很多接口的原理和细节不是很了解。Python-docx的原理好像是将Python-docx的结构转换成xml。去年数据有做过用Java处理xml的程序,但时间久了已经忘了…
下面直接给出源码:
因为第一次使用Python-docx,所有如果有不规范或者不简介的地方,请见谅并指出。
当然,中使用前要通过pip安装Python-docx.
from docx import Document
from docx.text.paragraph import Paragraph
from docx.oxml.text.paragraph import CT_P
from docx.oxml.table import CT_Tbl
from docx.table import Table
from copy import deepcopy
import pandas as pd
def copyText(filename,paratext,Para):
document = Document(filename)
paras=document.paragraphs
index=0
if type(paratext)==str:
print('copy:',paratext,Para.text)
for para in paras:
if para.text==paratext:
index=paras.index(para)+1
para=paras[index]
else:
print('copy:',Para.text,paratext.text)
for para in paras:
if para.text== paratext.text:
index = paras.index(para) + 1
paratext.runs[0].drawing_lst:
para = paras[index]
newPara=para.insert_paragraph_before()
for run in Para.runs:
#复制内容(包括样式)
newParaRun=newPara.add_run(run.text)
newParaRun.bold = run.bold
newParaRun.italic = run.italic
newParaRun.underline = run.underline
newParaRun.font.color.rgb = run.font.color.rgb
newParaRun.style.name = run.style.name
newPara.paragraph_format.alignment = Para.paragraph_format.alignment
newPara.paragraph_format.first_line_indent = Para.paragraph_format.first_line_indent
newPara.paragraph_format.left_indent = Para.paragraph_format.left_indent
newPara.paragraph_format.right_indent = Para.paragraph_format.right_indent
document.save(filename)
def copyTable(filename,paratext,table):
#复制表格
document = Document(filename)
paras = document.paragraphs
if type(paratext)==str:
for para in paras:
#print(para.text)
if paratext == para.text :
paragraph=para
tbl, p = table._tbl, paragraph._p
else:
for para in paras:
# print(para.text)
if paratext.text == para.text:
paragraph = para
tbl, p = table._tbl, paragraph._p
new_tbl = deepcopy(tbl)
p.addnext(new_tbl)
document.save(filename)
def Copy_Contents_Between_ParaA_ParaB_to_ParaC(filename1, filename2,Paratext1,Paratext2,Paratext3):
documentA = Document(filename1)
paragraphs = documentA.paragraphs#所有的段落
Paratext1 = Paratext1.encode('utf-8').decode('utf-8')
for aPara in paragraphs:
if Paratext1 == aPara.text :#匹配到了开始段落
ele = aPara._p.getnext()
break
while(True):#向后遍历
if ele==None:
break
if ele.tag == '':
break
if isinstance(ele, CT_P):#是段落
para = Paragraph(ele, documentA)
if Paratext2 == para.text:
break
copyText(filename2, Paratext3, para)#复制表格
if para.text!='':
Paratext3=para
elif isinstance(ele, CT_Tbl):#是表格
table=Table(ele,documentA)
copyTable(filename2,Paratext3,table)#复制表格
ele=ele.getnext()
if __name__ == '__main__':
data = pd.read_excel('尽调-计划说明书映射表.xlsx')
for i in range(len(data['计划说明书(生成表)'])):
Copy_Contents_Between_ParaA_ParaB_to_ParaC('数据来源-尽调报告.docx','生成的信托计划说明书.docx',data['尽调报告-开始段落'][i],
data['尽调报告-结束段落'][i],data['计划说明书(生成表)'][i])
程序执行后生成的计划说明书:

可以看到,尽调报告中指定的数据以及被复制到计划说明书的指定位置了。
待解决的问题:
上面的程序可以复制文字和表格以及样式,但是无法复制图片。据了解,Python-docx没有提供提取指定位置的图片的接口(至少在官方手册中没有找到),所以需要二次开发,这就要去研究Python-docx的原理和一些xml的知识了。但因为时间有限(网课还是要看的,作业还是要写的),就把这个问题留给我的实习负责人了。
如果大佬们知道如何解决图片处理的问题,请不吝赐教。
作者:cjh_hit