京东商城百万数据抓取--苏宁易购,淘宝网,京东商城,百万级价格数据海量抓取
按照惯例先上成果:
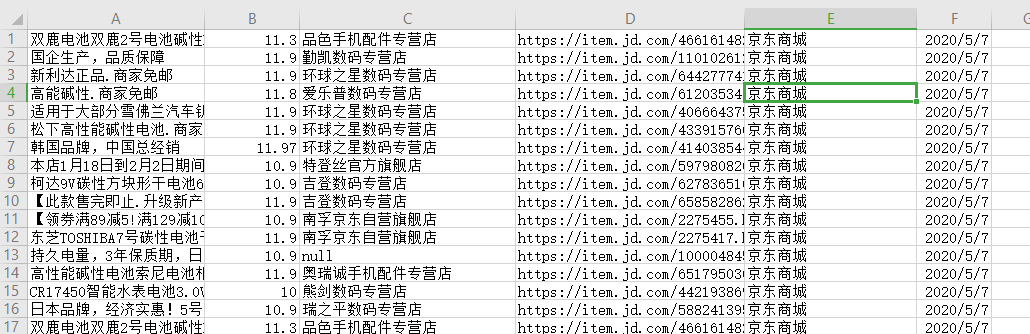
过了分割线就是源码了,一直复制运行一直爽
# -*- coding: utf-8 -*-
import requests
import re
import time
import datetime
import csv
import urllib.parse
def request_jd():
list = ('电池', '碗', '花', '手机', '后壳')
for kw in list:
print(kw)
u1 = 'https://search.jd.com/search?keyword='
u2 = '&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq='
u3 = '&ev=exprice_'
u4 = '%5E&page=3&s=59&click=0'
n = 10
m = n + 2
name = urllib.parse.quote('kw')
w = urllib.parse.quote(kw)
for i in range(0, 400):
# 可以更改page=n抓取所有第n页的数据
url = str(u1) + str(name) + str(w) + str(u2) + str(w) + str(u3) + str
 了解本专栏
订阅专栏 解锁全文
了解本专栏
订阅专栏 解锁全文
作者:不存在的ID
相关文章
Viola
2021-03-23
Gwen
2020-08-19
Jenny
2020-07-11
Rachel
2023-07-20
Psyche
2023-07-20
Winola
2023-07-20
Gella
2023-07-20
Grizelda
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Angie
2023-07-21
Nora
2023-07-24