集成学习算法
集成学习算法集成学习的基本原理BaggingBoosting随机森林
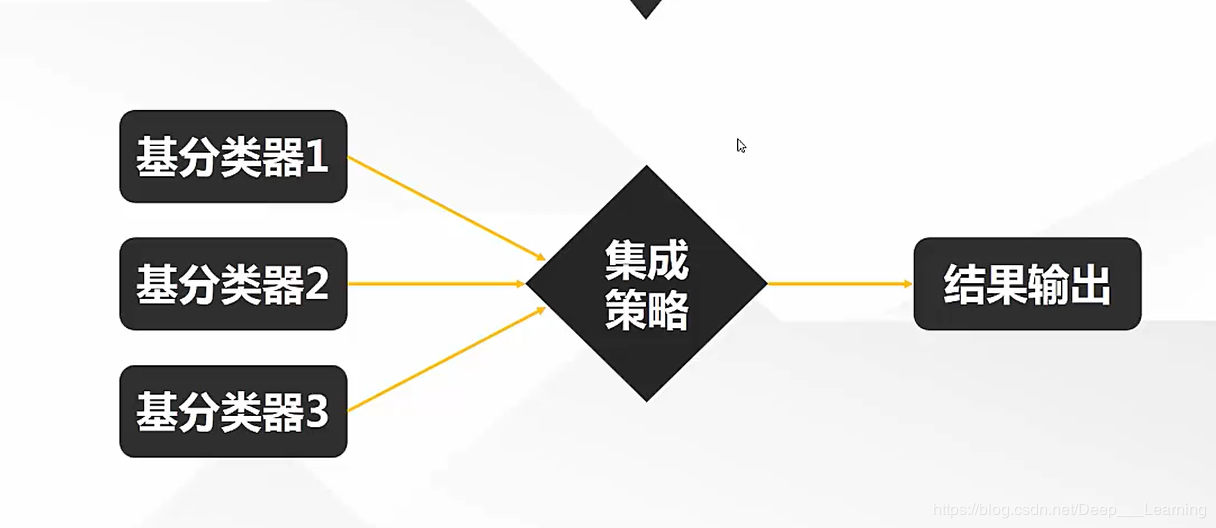
集成学习的基本原理
作者:虐猫人薛定谔i


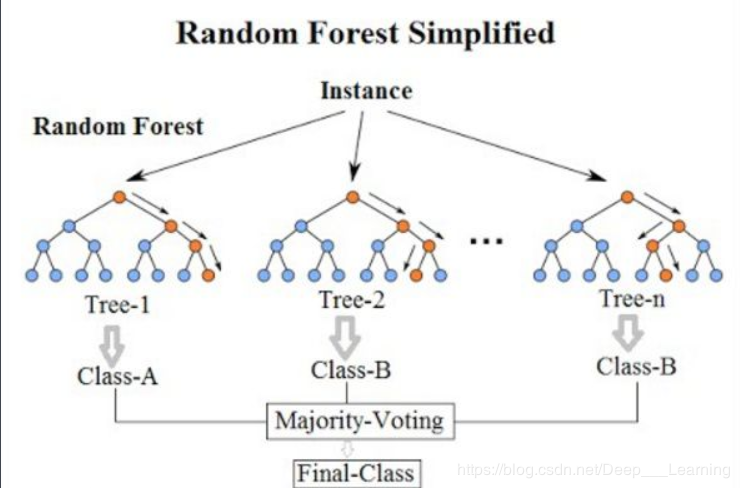
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出,并被注册成了商标。
随机森林相对于Bagging,既对样本做随机,又对变量做随机。
随机森林的优点:
1)对于很多种资料,它可以产生高准确度的分类器;
2)它可以处理大量的输入变数;
3)它可以在决定类别时,评估变数的重要性;
4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计;
5)它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;
6)它提供一个实验方法,可以去侦测variable interactions;
7)对于不平衡的分类资料集来说,它可以平衡误差;
8)它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将资料视觉化非常有用;
9)使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料;
10)学习过程是很快速的。
作者:虐猫人薛定谔i
相关文章
Serafina
2021-03-06
Iris
2021-08-03
Vesta
2021-07-19
Rhea
2023-05-31
Pandora
2023-07-07
Tallulah
2023-07-17
Trixie
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Hester
2023-07-20
Ianthe
2023-07-20
Irma
2023-07-20
Valora
2023-07-20
Kirima
2023-07-20
Radinka
2023-07-20
Fawn
2023-07-21
Tertia
2023-07-21