【小白】Yhen手把手带你爬小说网站,全网打尽,想看就看!(这可能会是你看过最详细的教程)
以下内容为本人原创,欢迎大家观看学习,禁止用于商业用途,转载请说明出处,谢谢合作!
大噶好!我是python练习时长一个月的Yhen,今天我学习了爬取小说网站,特别感谢六星教育python学院,我就是在这里学的,老师讲的挺好挺仔细的,以下内容都是基于我在课堂上学到的,大家有兴趣可以到腾讯课堂报名听课,都是免费的。
接下来我把经验分享给大家,作为小白的我们,在写代码时肯定会遇到一些bug,下面有我敲代码过程中出现的错误以及我的解决方法,希望可以帮助到大家!最后的源码也会给大家!因为比较详细所以内容可能较多,大家如果只想知道结果,可以直接看源码。
好啦咱们说干就干,敲起来!
今天我们我们要爬取的小说网站是“千千小说网”
url :https://www.qqxsw.co/
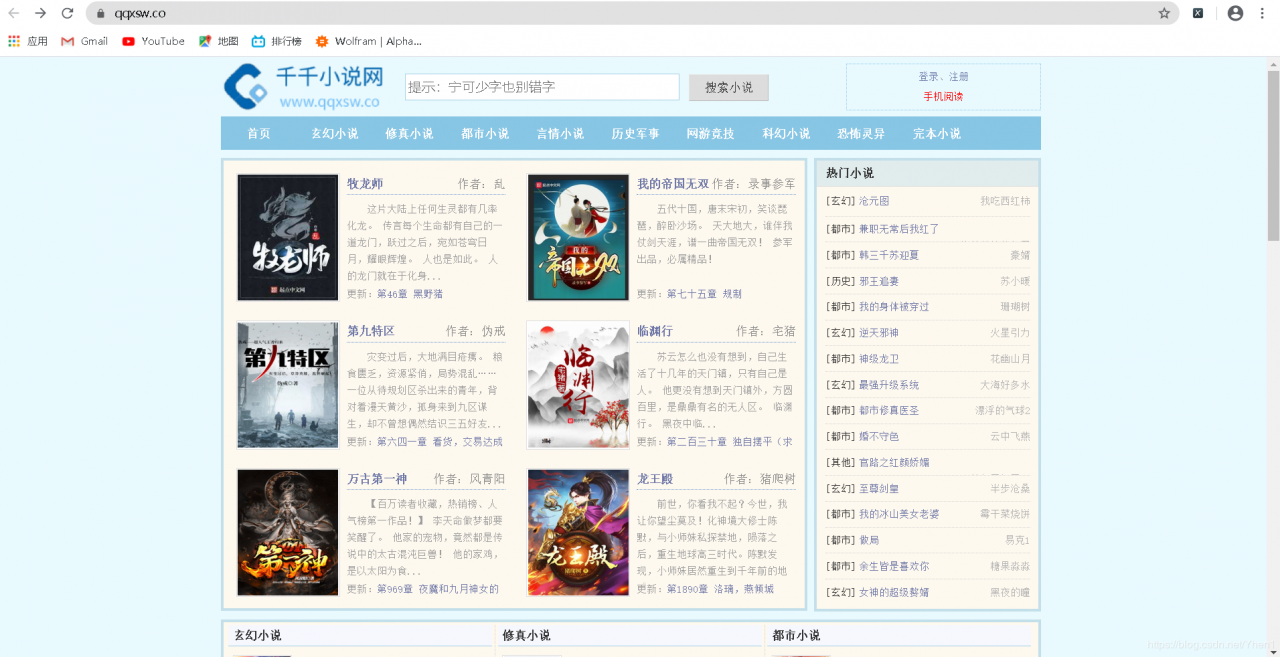
我们今天就做的是把首页第一本书《牧龙师》里面的内容爬下来
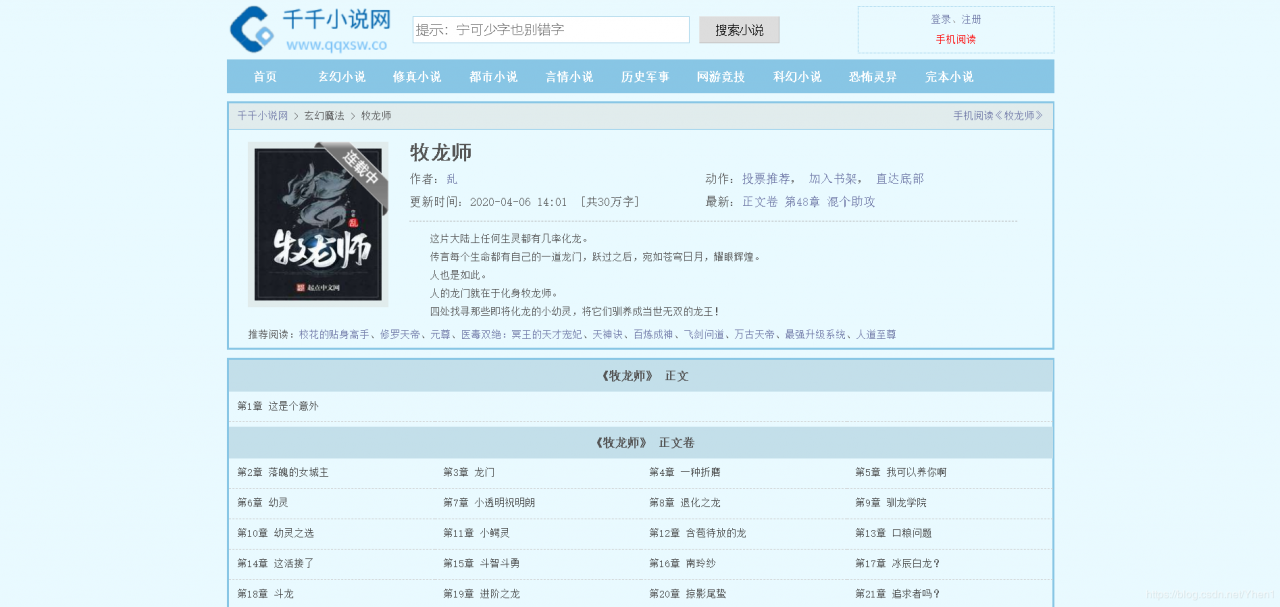
ok,清楚了需求,那我们马上开动起来吧!
我们首先先对小说的主页页面进行请求
# 导入爬虫包
import requests
# 小说页面的url
url = 'https://www.qqxsw.co/book_107838/'
# 对小说页面进行请求
response =requests.get(url).text
# 打印小说页面源码信息
print(response)
我们满心欢喜地执行上面的代码
我们得到了一堆数据,说明我们请求成功啦!
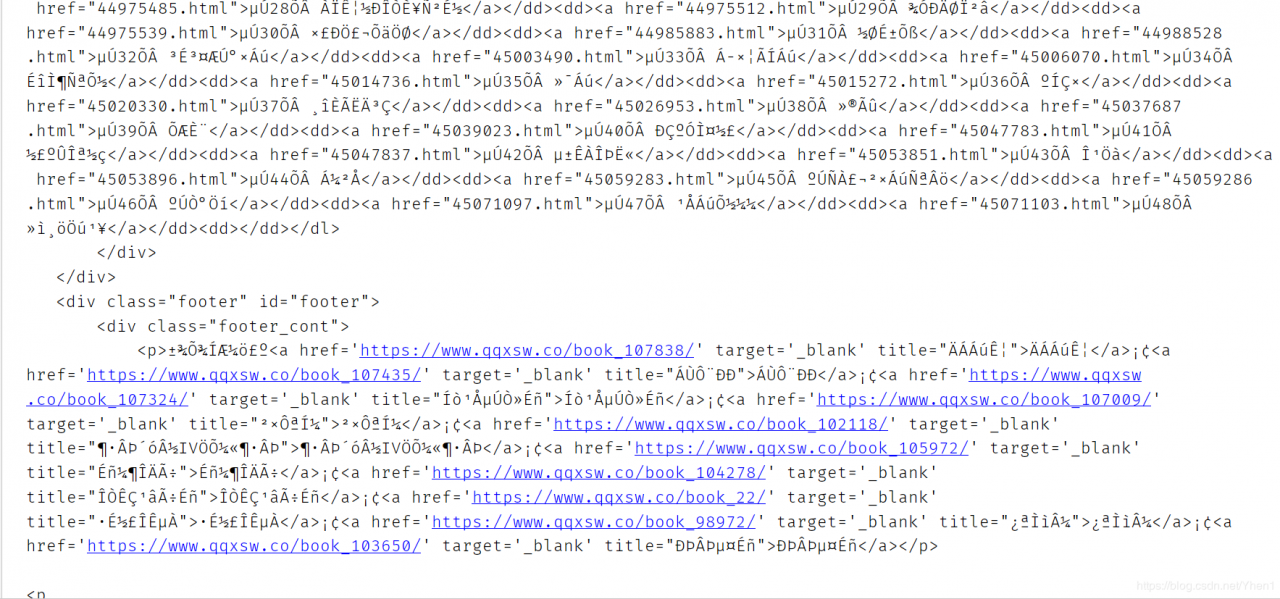
但是…有没有发现上面的数据有点奇怪呢?
是的…他出现了乱码
像这样的数据,就是出现了中文乱码
出现这种情况的原因是因为页面的编码格式是“GBK”格式,而我们爬下来的数据默认是“utf-8”,所以和我们页面编码不一致而导致的。
关于“ignore”一开始我也不懂,
百度得知:因为decode的函数原型是decode([encoding], [errors=‘strict’]),可以用第二个参数控制错误处理的策略,默认的参数就是strict,代表遇到非法字符时抛出异常;如果设置为ignore,则会忽略非法字符;

所以我只要把请求的页面数据解码成“gbk”格式即可
修改后的代码如下
response =requests.get(url).content.decode("gbk","ignore")
我们再来看看解码后的打印结果

登登登登!是不是一切正常呢!嘻嘻嘻
我们已经成功获取了页面的数据
接下来就要定位到页面里的每一个章节的按钮
首先我们按f12进入我们的开发者页面
按照下图操作
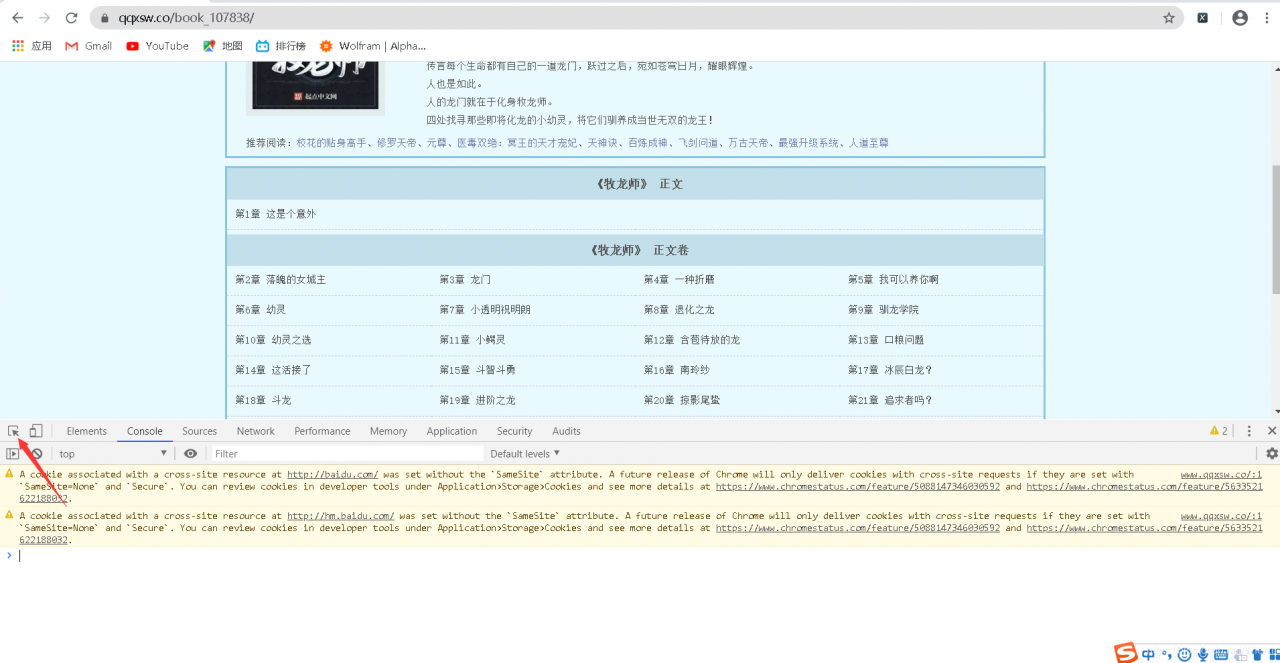
再点击定位到这里
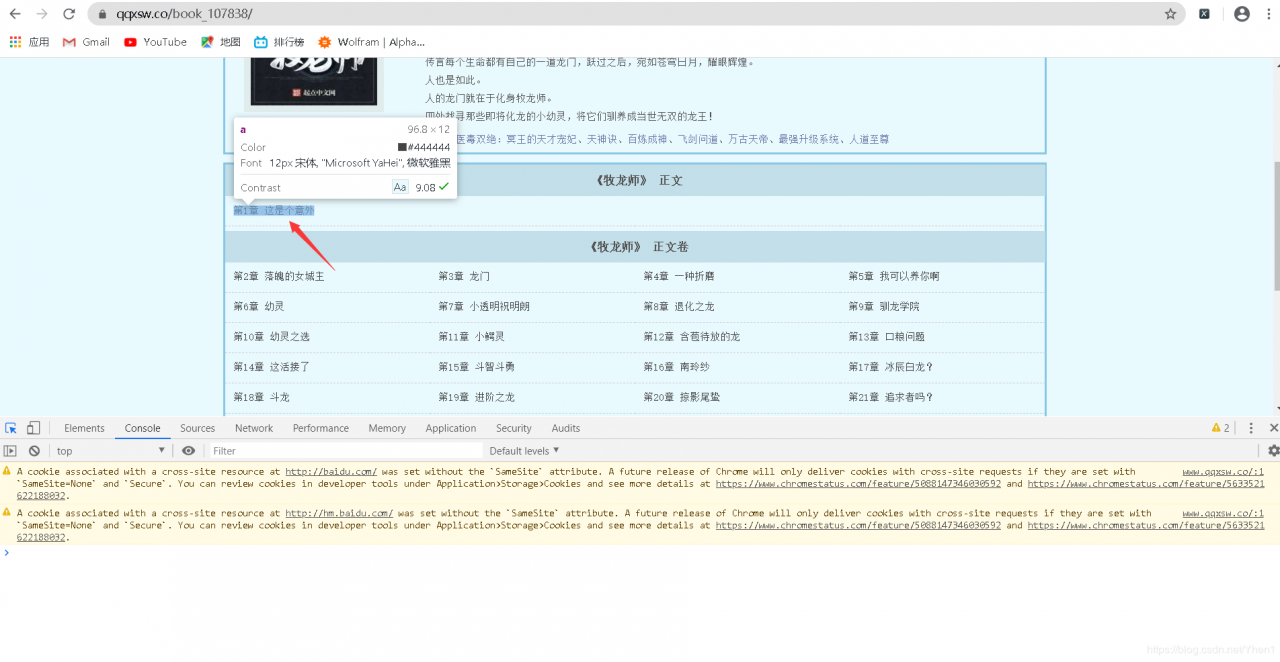
于是我们就得知了这个元素在页面中的位置

然后我们要用到一个叫做xpath的扩展工具,我用的是谷歌浏览器,xpath的安装是需要导入的。
可参考:https://blog.csdn.net/yhnobody/article/details/81030436
安装后以后,我们打开xpath
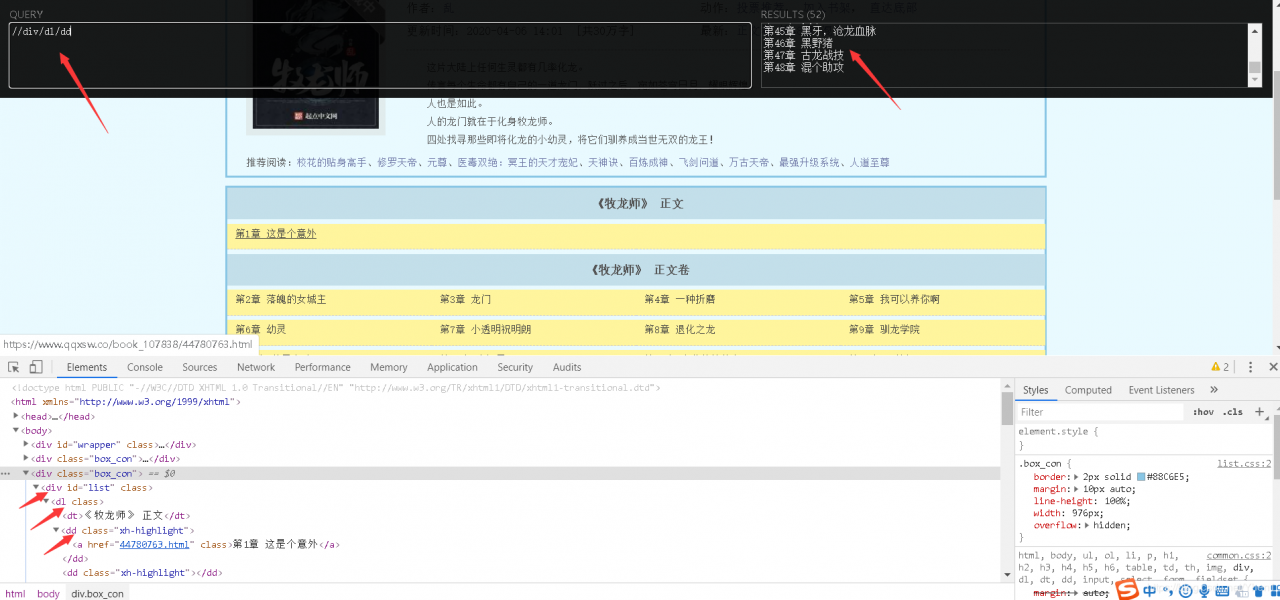
首先我们看控制台
刚刚我们定位到第一章的按钮位置是在
div标签下的dl标签下的dd标签下面的a
所以对应我们在xpath上输入//div/dl/dd/a
这里解释一下//是跨节点操作
然后在右边看到我们的resuits,嘿嘿,成功得到我们想要的所有入口章节的信息
得到了这个位置信息后
接下来继续敲代码
首先导入etree包,因为我们python是不能识别xpath的,所以要导包
注意这个包是自己要安装的哦
# 从lxml中导入etree包
from lxml import etree
获取HTML数据和通过xpath提取数据
# 获取HTML数据
dom =etree.HTML(response)
# 通过xpath提取数据
html =dom.xpath("//div/dl/dd/a/")
我们把结果html打印一下
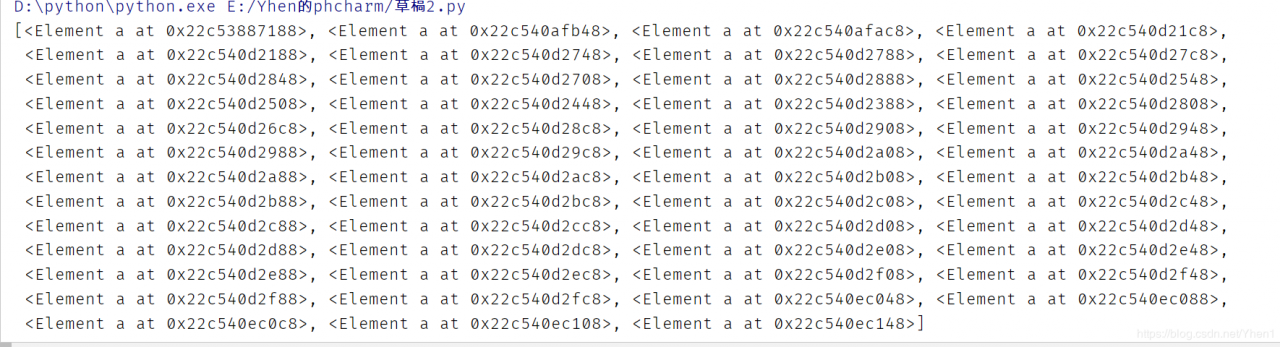
得到了这么一大串的对象数据
但是现在的数据都挤在了一块了,我们要把数据一 一取出来怎么办呢?
用到for 循环
for x in html:
print(x)
这个循环的意思就是,从nodes中把数据一 一提取到node里面去
我们来看下打印结果
看!现在是不是我们的对象都乖乖的排好队了呢
我们刚刚获取的是对象数据,如果想进一步获取网址
要再用一次xpath
还记得这个页面嘛?
我们的小说的章节都在这个href里面了

我们再用一次xpath获取
# 获取小说页面网址
a=["url"] = x.xpath("./@href")[0]
打印下结果看看
欧耶,成功获取了
emm…不过怎么怪怪的,和我们平时看到的网址不太一样啊
嗯,没错,少了前面的一段
我们来把他们拼接起来
a = url + x.xpath("./@href")[0]
打印一下

perfect!
然后我们要把这些数据装进字典里
# 创建一个新字典
dic = {}
# 获取小说页面网址
dic["url"] = url + x.xpath("./@href")[0]
接下来提取章节名也是同样的方法,
./text()的作用是提取数据里的文本数据
# 提取章节名
dic["name"] = x.xpath("./text()")[0]
看看成果
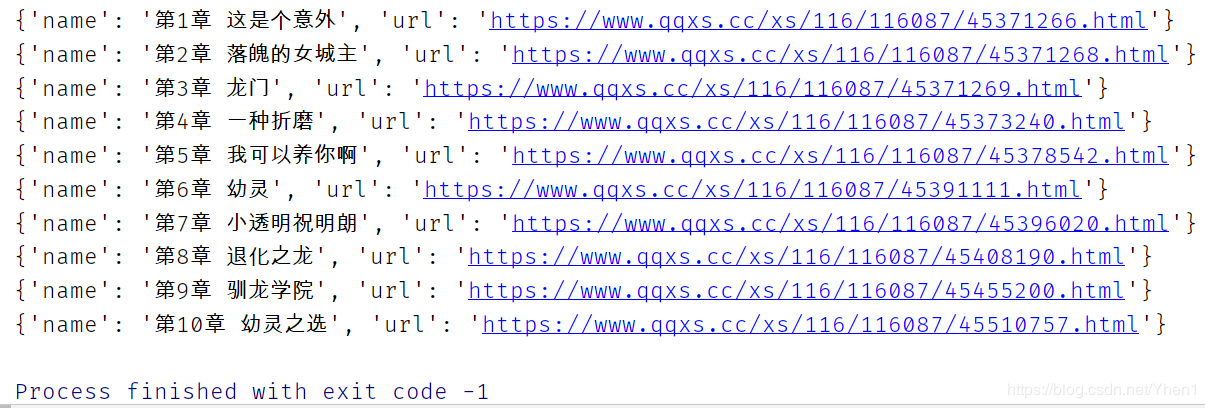
我们想要的数据已经一一对应起来啦
到这里我们已经完成一大半啦
接下来要做的就是对章节网址进行请求
然后提取里面的小说数据
我们来对章节的网址进行请求
并查看请求信息
response = requests.get(dic["url"]).content.decode("gbk", "ignore")
print(response)

成功获得章节页里面的数据啦
那么我们要怎样才能把我们网页里面的小说文字提取出来呢
还是要用到我们的老朋友xpath
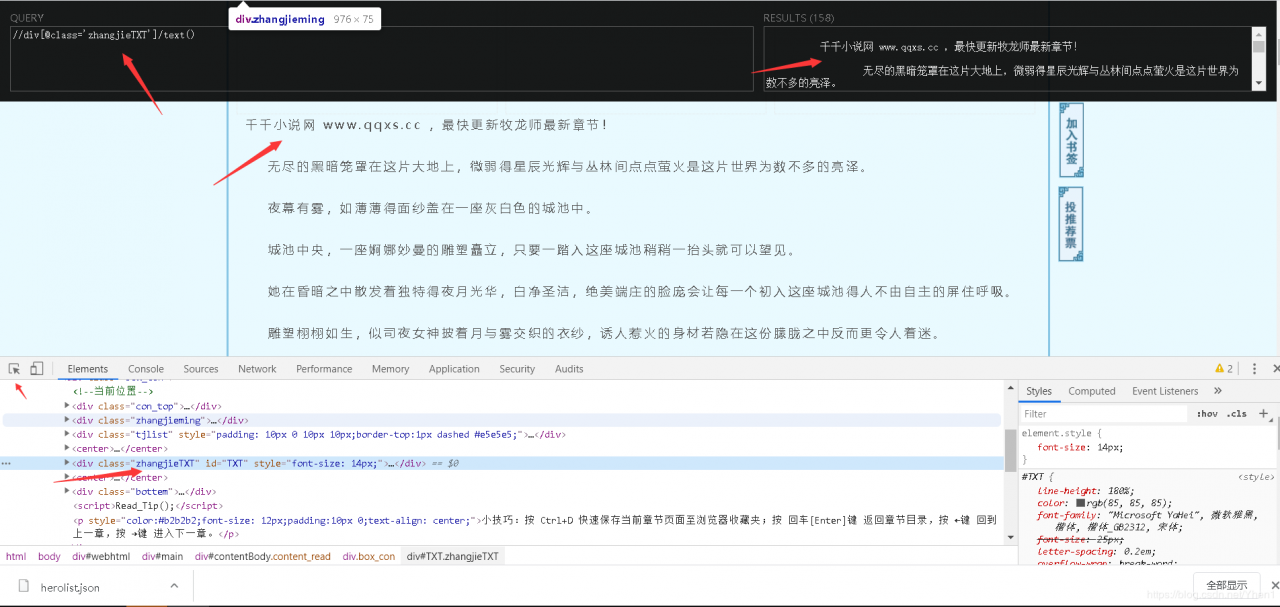
一样的方法,先定位到小说文字元素,找到元素所在的位置
然后在我们的xpath上输入//div[@class=‘zhangjieTXT’]
需要注意的一个就是别忘了 'zhangjieTXT’这里是有个引号的,如果没有了,就会定位不准确,导致得到很多我们不想要的数据哦…
这里的操作和第一次时一样的
doc = etree.HTML(response)
HTML = doc.xpath('//div[@class="zhangjieTXT"]/text()')
print(HTML)
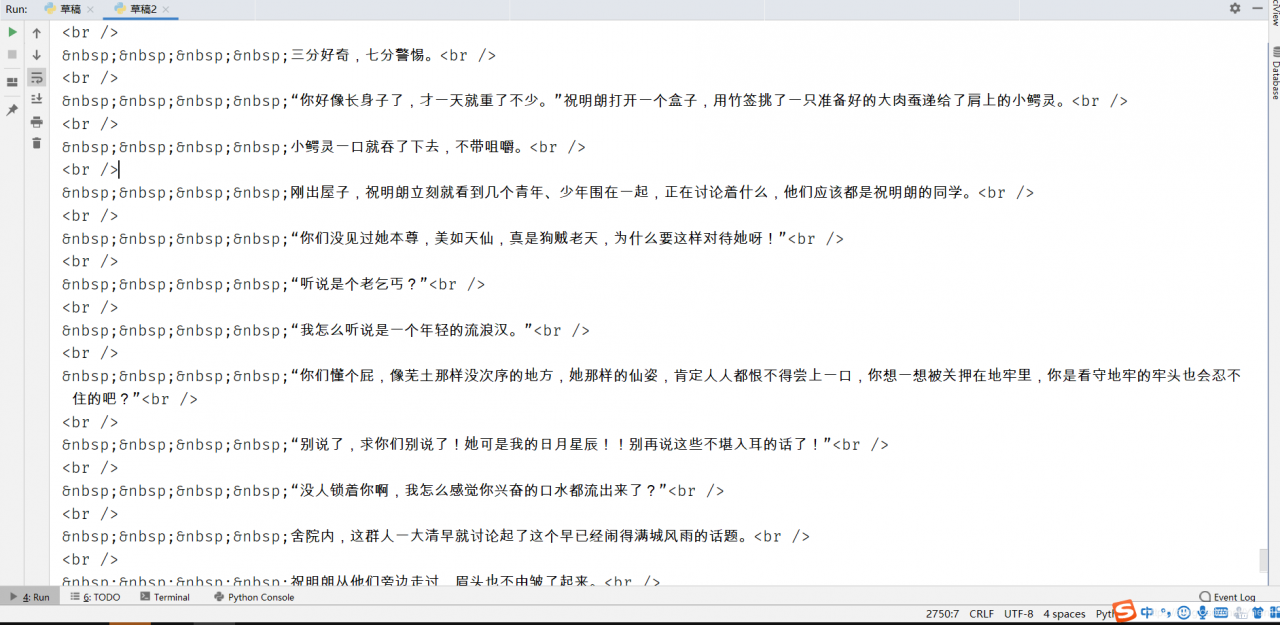
到这里就快要完成了
遍历小说数据
for v in HTML:
print(v)
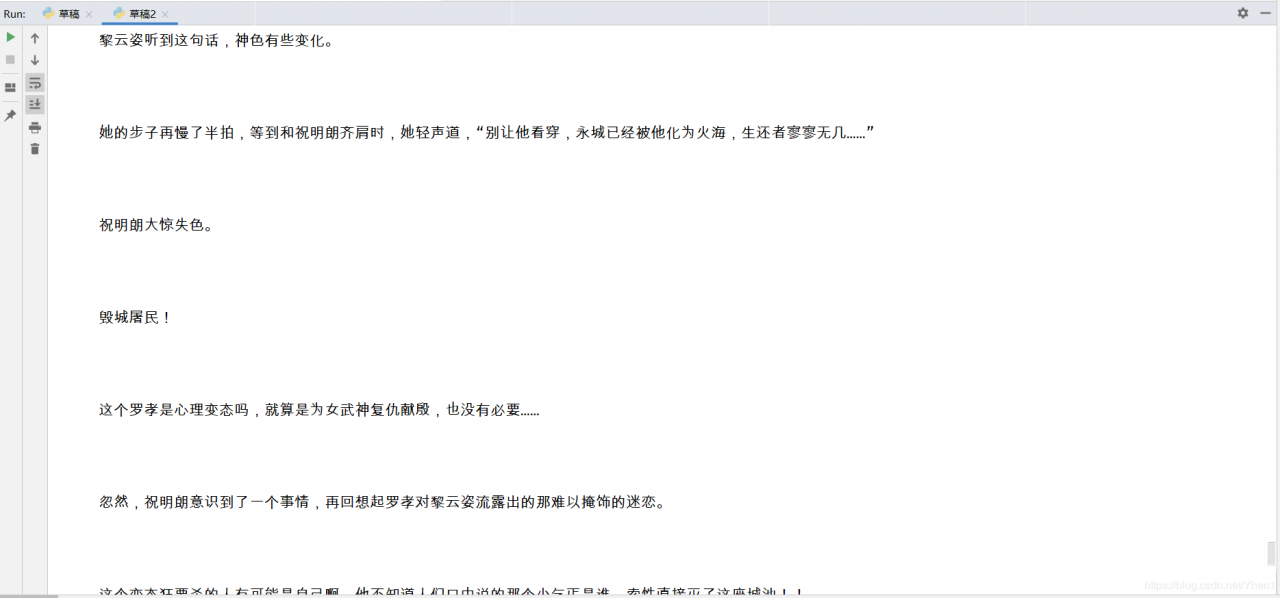
成功爬到了我们的小说文字
但是文字间的间隔太大了
不知道你看着爽不爽,反正我看着是很不爽
所以,安排!
先上图

哈哈哈哈哈这样的是不是舒服多了
怎么实现呢
for v in HTML:
# 头尾去空格
novel = v.strip()
strip()把头尾的空格去掉就可以啦!
这里给大家拓展一下:
去左边的空格lstrip()
去右边的空格rstrip()
接下来我们把爬到的数据保存到本地,就完成啦!
# 打开“小说”文件夹,将小说的章节名作为保存的文件名,以“a”追加的方式,编码成“utf-8”
f = open("小说/" + dic['name'] + ".txt", "a", encoding="utf-8")
# 写入小说数据,\n是换行符
f.write(novel + "\n")
#关闭读写文件
f.close()
来看看运行的结果
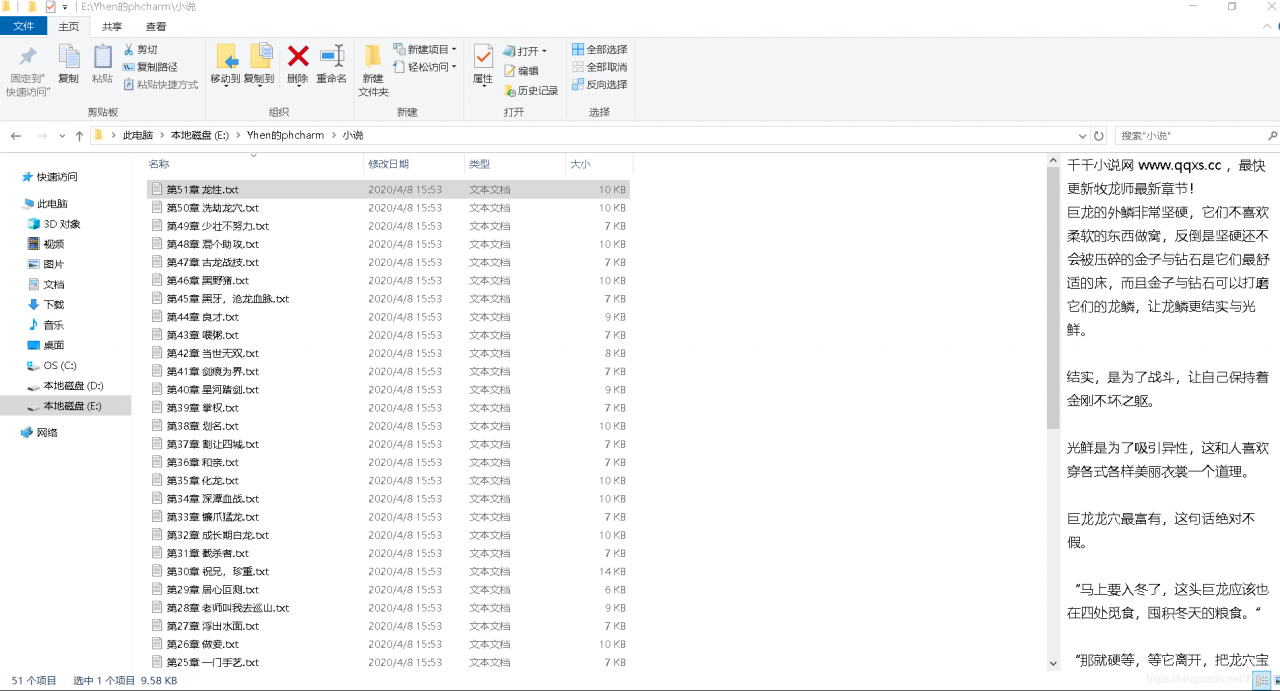

大功告成!撒花完结!!!
最后附上源码
import requests
from lxml import etree
# 章节菜单网址
url = "https://www.qqxs.cc/xs/116/116087/"
response = requests.get(url).content.decode("gbk", "ignore")
# 获取页面的HTML数据
dom = etree.HTML(response)
html = dom.xpath("//div/dl/dd/a")
for x in html:
# 创建一个新字典
dic = {}
# 获取小说页面网址
dic["name"] = x.xpath("./text()")[0]
# 提取章节名
dic["url"] = url + x.xpath("./@href")[0]
# print(dic)
# 对章节网址进行请求
response = requests.get(dic["url"]).content.decode("gbk", "ignore")
# print(response)
# 提取页面中的HTML数据
doc = etree.HTML(response)
# 提取小说文字数据
HTML = doc.xpath('//div[@class="zhangjieTXT"]/text()')
# 遍历小说数据
for v in HTML:
# 头尾去空格
novel = v.strip()
# 打开“小说”文件夹,将小说的章节名作为保存的文件名,以“a”追加的方式,编码成“utf-8”
f = open("小说/" + dic['name'] + ".txt", "a", encoding="utf-8")
# 写入小说数据,\n是换行符
f.write(novel + "\n")
#关闭读写文件
f.close()
Yhen有感
说实话,写教程还真挺累的哈哈哈,也深切体会到之前大佬们写教程的不易了。但当我写完之后,我是真的满满的成就感,原来我也能自己写这种博客,也能把我的知识和大家分享,虽然我懂的不多,但是我愿意把我会的都和大家分享!
写这个教程时,我也发现了很多问题,我自己尝试解决问题时就是我在学习的一个过程。比如老师演示的时候,爬下来的数据是没有空行的,但是我爬下来却有很多空行,我就得想办法解决,上网查到的消除空行的方法都是要写入后再对txt文件进行处理,很麻烦。我把问题发到群上后,有同学说可以用strip()去空行的方法,我试了一下,果然OK!感谢!
我在写代码时也和老师上课讲的代码作比较,想想老师用的方法我能否换个方法来实现同样的效果呢,比如说网址拼接那里我是直接拼接的…老师有没有一些步骤是不必要的呢?有,比如老师上课时把字典里的数据再装进列表里,然后再用for循环遍历…我把结果打印出来,其实就是字典里的数据,所以还何必多此一举,装进去再拿出来呢?而且后面完全是用不到这个列表里的数据的。
很开心能在这里给大家分享我的经验
我还只是个小白,如果有什么写的不好,写错了的地方欢迎大家指正,有什么问题都可以在评论区提出哦!我们一起共同进步!
希望大家能够喜欢这篇文章,以后我也会继续出其他的教程,把我的经验分享给大家!谢谢
如果可以的话,可以点个赞鼓励下小弟嘛?加个关注更好哦哈哈嘻嘻
我是Yhen,我们下次见
作者:Yhen1