VMware + Ubuntu18.04 搭建Hadoop集群环境的图文教程
前言
VMware克隆虚拟机(准备工作,克隆3台虚拟机,一台master,两台node)
1.创建Hadoop用户(在master,node1,node2执行)
2.更新apt下载源(在master,node1,node2执行)
3. 安装SSH、配置SSH免密登录 (在master,node1,node2执行)
4.安装Java环境 (在master,node1,node2执行)
修改主机名(在master,node1,node2执行)
修改IP映射(在master,node1,node2执行)
SSH免密登录其他节点(在master上执行)
安装hadoop3.2.1(在master中执行)
配置hadoop环境(这一步需要很仔细)
启动 (在master上执行)
关闭hadoop集群(在master上执行)
总结
前言本次教程是基于学校的大数据实验而做的,博主在搭建的同时,记录了自己的命令运行结果截图,在图书馆搭建环境+写博客,也花了将近3个小时。长时间眼睛对着电脑会很伤眼睛,所以童鞋们需要注意保护好眼睛,做做眼保健操。希望学到的童鞋可以点个赞!

先在虚拟机中关闭系统
右键虚拟机,点击管理,选择克隆

3.点击下一步,选择完整克隆,选择路径即可



顺序执行以下命令即可
1.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
设置用户密码(输入两次)
sudo passwd hadoop
添加权限
sudo adduser hadoop sudo
切换到hadoop用户(这里要输入刚刚设置的hadoop密码)
su hadoop
运行截图展示(以master虚拟机为例)

sudo apt-get update
截图展示(以master为例)

1.安装SSH
sudo apt-get install openssh-server
2.配置SSH免密登录
ssh localhost
exit
cd ~/.ssh/
ssh-keygen -t rsa #一直按回车
cat ./id_rsa.pub >> ./authorized_keys
3.验证免密
ssh localhost
exit
cd ~/.ssh/
ssh-keygen -t rsa #一直按回车
cat ./id_rsa.pub >> ./authorized_keys
截图展示(以master为例)

1.下载 JDK 环境包
sudo apt-get install default-jre default-jdk
2.配置环境变量文件
vim ~/.bashrc
3.在文件首行加入
export JAVA_HOME=/usr/lib/jvm/default-java
4,。让环境变量生效
source ~/.bashrc
5.验证
java -version
截图展示(以master为例)

1.将文件中原有的主机名删除,master中写入master,node1中写入node1,node2…(同理)
sudo vim /etc/hostname
重启三个服务器
reboot
重启成功后,再次连接会话,发现主机名改变了
截图展示(以node1为例)

查看各个虚拟机的ip地址
ifconfig -a
如果有报错,则下载 net-tools ,然后再运行即可看到
sudo apt install net-tools
如下图,红色方框内的就是 本台虚拟机的 ip 地址
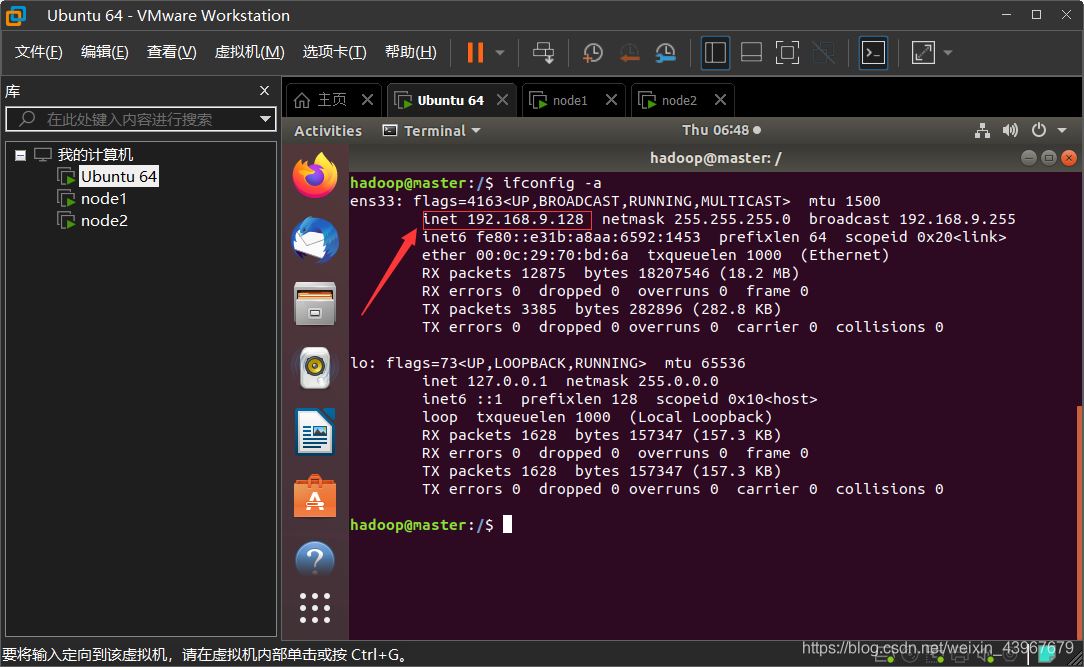
3台虚拟机中都需要在 hosts 文件中加入对方的ip地址
sudo vim /etc/hosts
以master为例截图展示

在Master上执行
cd ~/.ssh
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
cat ./id_rsa.pub >> ./authorized_keys
scp ~/.ssh/id_rsa.pub hadoop@node1:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@node2:/home/hadoop/

在node1,node2都执行
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就删掉

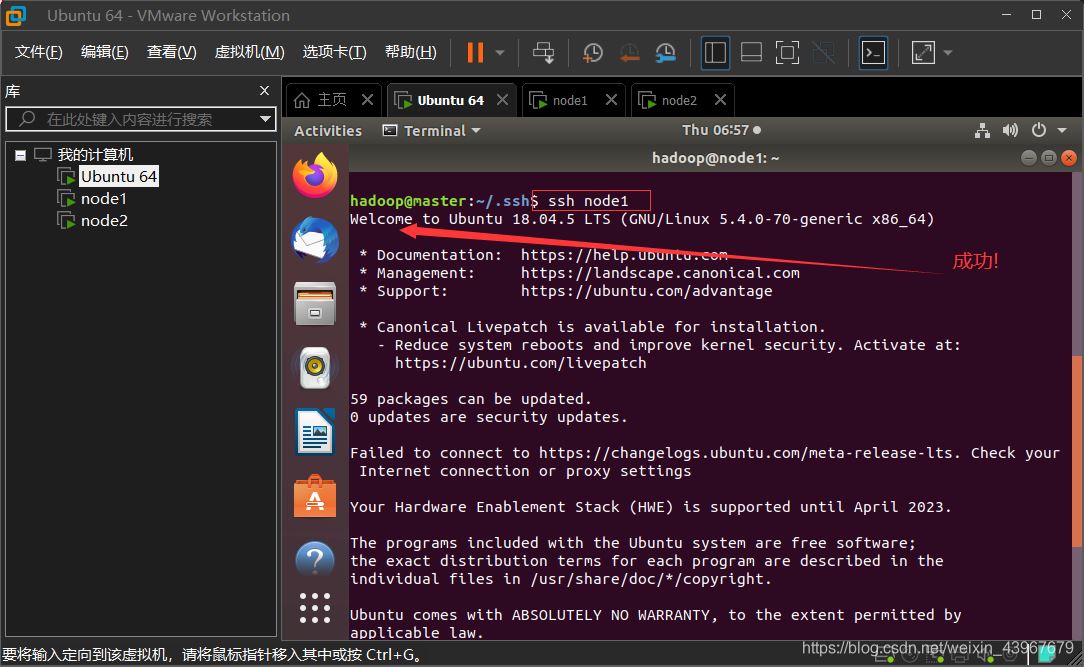
验证免密登录
ssh node1
exit
ssh node2
exit
以master为例截图展示
有些镜像的下载网址失效了,这里贴出官网的下载地址。
下载网址:hadoop3.2.1下载网址
下载好,之后通过VMware-Tools上传到master的/home/hadoop中

解压
cd /home/hadoop
sudo tar -zxf hadoop-3.2.1.tar.gz -C /usr/local #解压
cd /usr/local/
sudo mv ./hadoop-3.2.1/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
验证
cd /usr/local/hadoop
./bin/hadoop version

配置环境变量
vim ~/.bashrc
在首行中写入
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使得配置生效
source ~/.bashrc
创建文件目录(为后面的xml做准备)
cd /usr/local/hadoop
mkdir dfs
cd dfs
mkdir name data tmp
cd /usr/local/hadoop
mkdir tmp
配置hadoop的java环境变量
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
两个的首行都写入
export JAVA_HOME=/usr/lib/jvm/default-java
(master中)配置nodes
cd /usr/local/hadoop/etc/hadoop
删除掉原有的localhost,因为我们有2个node,就把这2个的名字写入
vim workers
node1
node2
配置 core-site.xml
vim core-site.xml
因为我们只有一个namenode,所以用fs.default.name,不采用fs.defalutFs
其次确保/usr/local/hadoop/tmp这个目录存在
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
配置 hdfs-site.xml
vim hdfs-site.xml
dfs.namenode.secondary.http-address确保端口不要和core-site.xml中端口一致导致占用
确保/usr/local/hadoop/dfs/name :/usr/local/hadoop/dfs/data 存在
因为我们只有2个node,所以dfs.replication设置为2
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
配置mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置 yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
将hadoop压缩
cd /usr/local
tar -zcf ~/hadoop.master.tar.gz ./hadoop #压缩
cd ~
复制到node1中
scp ./hadoop.master.tar.gz node1:/home/hadoop
复制到node2中
scp ./hadoop.master.tar.gz node2:/home/hadoop
在node1、node2上执行
解压
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local #解压
sudo chown -R hadoop /usr/local/hadoop #修改权限
首次启动需要先在 Master 节点执行 NameNode 的格式化,之后不需要
hdfs namenode -format
(注意:如果需要重新格式化 NameNode ,才需要先将原来 NameNode 和 DataNode 下的文件全部删除!!!!!!!!!)
#看上面的文字,不要直接复制了
rm -rf $HADOOP_HOME/dfs/data/*
rm -rf $HADOOP_HOME/dfs/name/*
启动 (在master上执行)
start-all.sh
mr-jobhistory-daemon.sh start historyserver
master中,出现Warning不影响
jps
运行截图展示

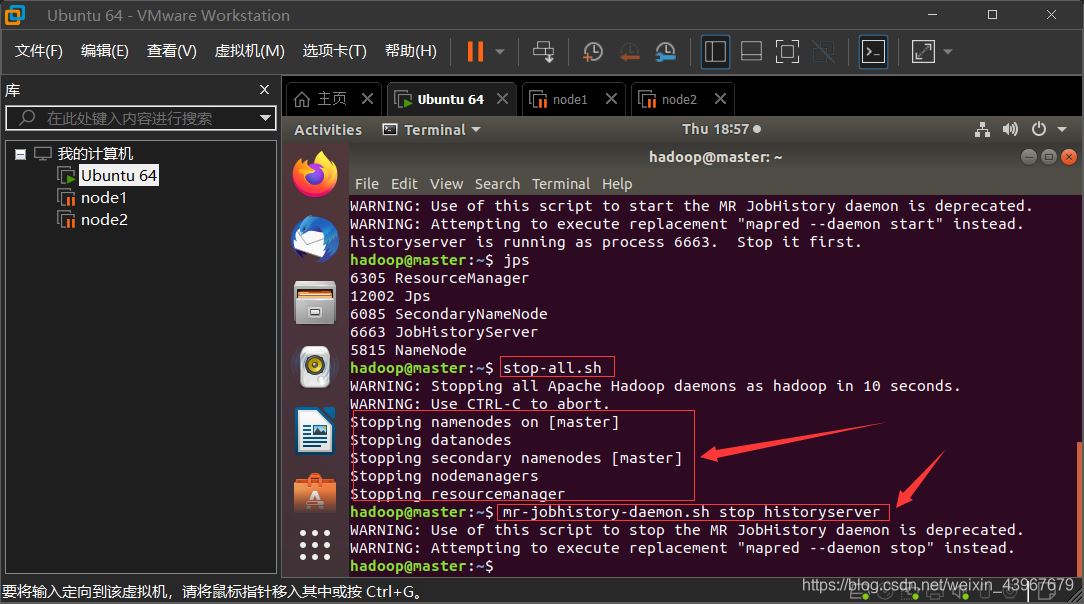
stop-all.sh
mr-jobhistory-daemon.sh stop historyserver
运行截图展示
搭建环境是一件比较耗时的操作,自己亲手搭一遍,可能其中会遇到很多问题,比如说Linux的命令不熟悉,各种报错,运行结果不对等,但是这些一般都可以在网上搜索到对应的解决方法。学习新技术就是要勇于试错,然后归纳总结,这样子会形成自己的一套解决问题的逻辑框架思维,也可以增强知识框架的形成,加油!
到此这篇关于VMware + Ubuntu18.04 搭建Hadoop集群环境的图文教程的文章就介绍到这了,更多相关VMware Ubuntu搭建Hadoop集群内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!