【监督学习】- 分类(决策树)
决策树(decision tree) 是一种基本的分类与回归方法。本博客主要讨论用于分类的决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。这些决策树学习的思想主要来源于由Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法,以及由Breiman等人在1984年提出的CART算法。本文首先介绍决策树的基本概念,然后介绍特征的选择、决策树的生成以及决策树的修剪,最后通过案例实现决策树模型。
相关学习链接:1:监督学习框架:思维导图-python.
1:机器学习GitHub代码:点我下载.
1:机器学习实战视频:ApacheCN_机器学习实战.
决策树 场景
特征:
1.不浮出水面是否可以生存
2.是否有脚蹼
案例1: 判定鱼类和非鱼类
根据以上2 个特征,将动物分成两类:鱼类和非鱼类。

决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(intermal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
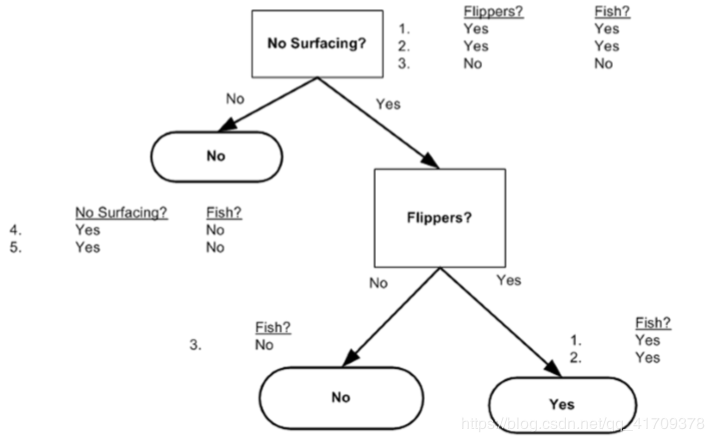
用决策树对鱼类和非鱼类分类,从根结点开始,对实例的两类特征进行测试,根据测试结果,将实例分配到其子结点中,这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点,最后将所有实例分到叶结点的类中。
决策树还表示给定特征条件下类的条件概率分布。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。假设X为表示特征的随机变量,Y为表示类的随机变量,那么这个条件概率分布可以表示为P(Y|X)。 X取值于给定划分下单元的集合,Y 取值于类的集合。各叶结点(单元)上的条件概率往往偏向某概率较大一个特定的类。 决策树分类时将该结点的实例强行分到条件概率大的那一类中。
将特征空间划分为互不相交的单元(cell) 或区域(region), 并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的每一条路径对应于划分中的一个单元。
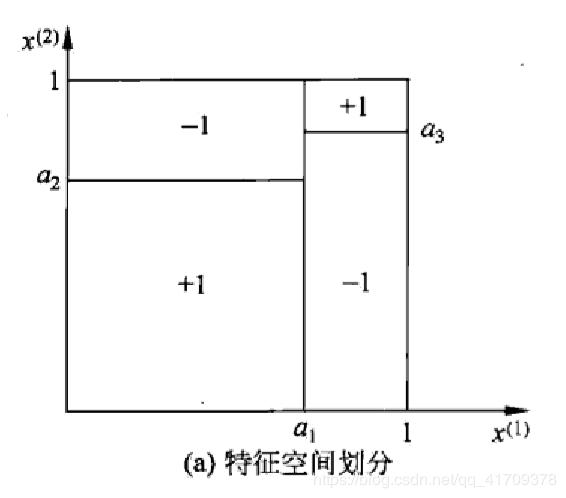
图(a)表示了特征空间的一个划分,图中的大正方形表示特征空间。这个大正方形被若干个小矩形分割,每个小矩形表示一个单元,特征空间划分上的单元构成了一个集合,X取值为单元的集合,为简单起见,假设只有两类:正类和负类,即r取值为+1和-1。小矩形中的数字表示单元的类,此次模型被分成2类4个单元。
在决策树学习中,假设给定训练数据集 D={(x1,y1),(x2,y2),⋯ ,(xN,yN)}D = \left\{ {\left( {{x_1},{y_1}} \right),\left( {{x_2},{y_2}} \right), \cdots ,\left( {{x_N},{y_N}} \right)} \right\}D={(x1,y1),(x2,y2),⋯,(xN,yN)}其中,x=(xi(1),xi(2),⋯ ,xi(n))Tx = {\left( {x_i^{\left( 1 \right)},x_i^{\left( 2 \right)}, \cdots ,x_i^{\left( n \right)}} \right)^T}x=(xi(1),xi(2),⋯,xi(n))T为输入实例(特征向量),n为特征个数,yi∈{1,2,⋯ ,K}{y_i} \in \left\{ {1,2, \cdots ,K} \right\}yi∈{1,2,⋯,K}为类标记,i=1,2,⋯ ,Ni = 1,2, \cdots ,Ni=1,2,⋯,N,N为样本容量。学习的目标是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
特征选取: 在训练特征数据(属性)中选取具有分类能力最强的特征。
如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。通常特征选择的准则是信息增益或信息增益比。
1:特征的选择是决定用哪个特征来划分特征空间。
例如:申请贷款的人有4种特征属性,
1.年龄:青年、中年、老年
2.有无工作:是、否
3.有无房子:是、否
4.信贷情况:非常好、好、一般
在对上述的特征制定一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
2:于是选取哪个特征作为根节点?
以下有两种(a)(b)不同特征作为根节点,决定的是不同的决策树。
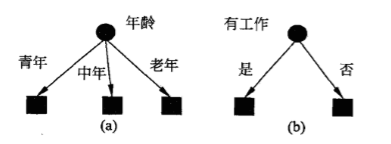
(a)所示的根结点的特征是年龄,有3个取值,对应于不同的取值有不同的子结点。(b)所示的根结点的特征是有工作,有2个取值。对应于不同的取值有不同的子结点。两个决策树都可以从此延续下去。
3:究竞选择哪个特征更好些?
于是就要求一种能够确定选择特征的准则,信息增益(information gain) 就能够很好地表示这一直观的准则.
了解信息增益,首先引入熵的定义。
熵: 熵(entropy) 是表示随机变量不确定性的度量。在不同的学科中也有引申出的更为具体的定 义,是各领域十分重要的参量。
设X是一个取有限个值的离散随机变量,其概率分布为
P(X=xi)=pi,i=1,2,.....,nP\left( {X = {x_i}} \right) = {p_i},{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} i = 1,2,.....,nP(X=xi)=pi,i=1,2,.....,n
则随机变量X的熵定义为
H(X)=−∑i=1npilogpiH\left( X \right) = - \sum\limits_{i = 1}^n {{p_i}\log {p_i}}H(X)=−i=1∑npilogpi
由定义可知,熵只依赖于X的分布,而与X的取值无关。
例如:当随机变量只取两个值1、0时,及X的分布为:
P(X=1)=p,P(X=0)=1−p,0≤p≤1P\left( {X = 1} \right) = p{\kern 1pt} {\kern 1pt} {\kern 1pt} ,{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} P\left( {X = 0} \right) = 1 - p{\kern 1pt} {\kern 1pt} {\kern 1pt} ,{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \le p \le 1P(X=1)=p,P(X=0)=1−p,0≤p≤1
熵为:
H(p)=−plog2p−(1−p)log2(1−p)H\left( p \right) = - p{\log _2}p - \left( {1 - p} \right){\log _2}\left( {1 - p} \right)H(p)=−plog2p−(1−p)log2(1−p)
我们发现当p=0或p=1时,H(p)H\left( p \right)H(p)=0,随机变量完全没有不确定性。当p=0.5 时,H(p)H\left( p \right)H(p)=1,熵取值最大,随机变量不确定性最大。
信息熵(香农熵): 是一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。
条件熵H(Y| X): 表示在已知随机变量X的条件下随机变量Y的不确定性。
随机变量X给定的条件下随机变量Y的条件熵(conditional entropy) H(Y\X), 定义为X给定条件下Y的条件概率分布的熵对X的数学期望。
H(Y∣X)=∑i=1npiH(Y∣X=xi)H\left( {Y|X} \right) = \sum\limits_{i = 1}^n {{p_i}H\left( {Y|X = {x_i}} \right)}H(Y∣X)=i=1∑npiH(Y∣X=xi) 其中,pi=P(X=xi)i=1,2,.....,n{p_i} = P\left( {X = {x_i}} \right){\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} i = 1,2,.....,npi=P(X=xi)i=1,2,.....,n
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empiricalentropy) 和经验条件熵(empiricalconditional entropy)。
信息增益: 在划分数据集前后信息发生的变化称为信息增益。
特征 A对训练数据集D的信息增益g(D,4),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
g(D,A)=H(D)−H(D∣A)g\left( {D,A} \right) = H\left( D \right) - H\left( {D|A} \right)g(D,A)=H(D)−H(D∣A)
在模式识别书籍中, 熵H(Y)与条件熵H(Y |X)之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
设训练数据集为D, ∣D∣|D|∣D∣表示其样本容量,即样本个数。设有K个类Ck{C_k}Ck, k=1,2…,K,∣D∣|D|∣D∣为属于类Ck{C_k}Ck的样本个数,∑k=1k∣Ck∣=∣D∣\sum\limits_{k = 1}^k {|{C_k}|} = |D|k=1∑k∣Ck∣=∣D∣。设特征A有n个不同的取值{a1,a2,...,an}\left\{ {{a_1},{a_2},...,{a_n}} \right\}{a1,a2,...,an}根据特征A的取值将D划分为n个子集 D1,D2,...,Dn{{D_1},{D_2},...,{D_n}}D1,D2,...,Dn,∣Di∣|D_i|∣Di∣为DiD_iDi的样本个数,∑i=1n∣Di∣=∣D∣\sum\limits_{i = 1}^n {|{D_i}|} = |D|i=1∑n∣Di∣=∣D∣。 记子集DiD_iDi中属于类CkC_kCk的样本的集合为Dik{D_{ik}}Dik,即Dik=Ck∩Di{D_{ik}} = {C_k} \cap {D_i}Dik=Ck∩Di,∣Dik∣|{D_{ik}}|∣Dik∣为Dik{D_{ik}}Dik的样本个数。
(1) 计算数据集D的经验熵:H(D)H\left( D \right)H(D)
H(D)=−∑k=1K∣Ck∣∣D∣log2∣Ck∣∣D∣H\left( D \right) = - \sum\limits_{k = 1}^K {\frac{{|{C_k}|}}{{|D|}}} {\log _2}\frac{{|{C_k}|}}{{|D|}}H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
仍然使用决策树构造中的案例(制定一个贷款申请的决策树),其中样本数据表为:
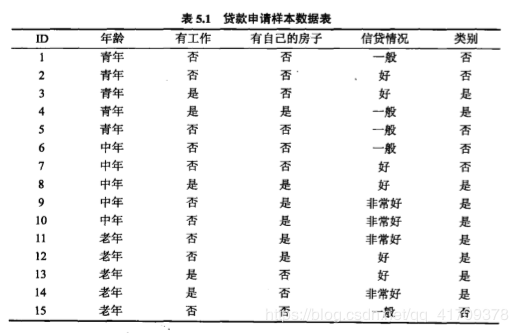
# -*- coding: utf-8 -*-
# @Time : 2020/4/10 10:15
from math import log
def entropy(dataset): #计算经验熵
feature_key = -1
column = [row[feature_key] for row in dataset] # 获取标签值
feature_set = set(column) # 对标签进行排列
entropy = 0.0
for x in feature_set: # 遍历标签值
p = column.count(x) / float(len(column)) # 统计各标签个数p
entropy -= p * log(p, 2)
return entropy
if __name__ == '__main__':
dataSet = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
entropy_value = entropy(dataSet)
print('经验熵为:', entropy_value)
测试结果:
经验熵为: 0.9709505944546686
也可以通过数学公式计算出:
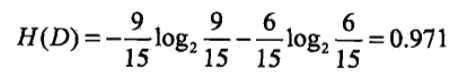
经验熵为0.971
(2) 计算特征A对数据集D的经验条件熵H(D∣A)H\left( {D|A} \right)H(D∣A)
H(D∣A)=∑n=1n∣Di∣∣D∣H(Di)=−∑i=1n∣Di∣∣D∣∑k=1K∣Dik∣∣Di∣log2∣Dik∣∣Di∣H\left( {D|A} \right) = \sum\limits_{n = 1}^n {\frac{{|{D_i}|}}{{|D|}}} H\left( {{D_i}} \right) = - \sum\limits_{i = 1}^n {\frac{{|{D_i}|}}{{|D|}}\sum\limits_{k = 1}^K {\frac{{|{D_{ik}}|}}{{|{D_i}|}}} {{\log }_2}\frac{{|{D_{ik}}|}}{{|{D_i}|}}}H(D∣A)=n=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣
例如计算特征年龄在数据集D的经验条件熵,年龄有青年、中年、老年三个特征,即i=3;k表示:在年龄为i时类别的“是”、“否”。∣D01∣{|{D_{01}}|}∣D01∣表示:在青年类别(i=0)下,类别为"是"的个数,个数为2。
(3) 计算信息增益
g(D,A)=H(D)−H(D∣A)g\left( {D,A} \right) = H\left( D \right) - H\left( {D|A} \right)g(D,A)=H(D)−H(D∣A)
# -*- coding: utf-8 -*-
# @Time : 2020/4/10 14:55
import numpy as np
from math import log
def entropy(dataset, feature_key): # 计算经验熵
column = [row[feature_key] for row in dataset] # 获取标签值
feature_set = set(column) # 对标签进行去重复
entropy = 0.0
for x in feature_set: # 遍历标签值
p = column.count(x) / float(len(column)) # 统计各标签个数p
entropy -= p * log(p, 2)
return entropy
def conditional_entropy(dataset, feature_key): # 计算信息增益
column = [row[feature_key] for row in dataset] # 读取[feature_key]这一列
conditional_entropy = 0
for x in set(column): # 划分数据集,并计算
sub_data_set = [row for row in dataset if row[feature_key] == x] # 按某列轴的特征划分数据子集
conditional_entropy += (column.count(x) / float(len(column))) * entropy(sub_data_set, feature_key = -1) # 计算某一列轴中某个特征的熵值,累加后即为条件熵
return conditional_entropy
def create_feature_set(dataset): # 创建特征集,特征集是样本每个维度的值域(取值)
"""
like {0: ['老年', '青年', '中年'], 1: ['否', '是'], 2: ['否', '是'], 3: ['好', '一般', '非常好']}
"""
feature_set = {}
m, n = np.shape(dataset) # m means rows, n means columns
for axis in range(n - 1): # 按列来遍历,n-1代表不存入类别的特征(标签不存入)
column = list(set([row[axis] for row in dataset])) # 按列提取数据,并用set过滤
feature_set[axis] = column # 每一行就是每一维的特征值
return feature_set
if __name__ == '__main__':
dataSet = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
# entropy_value = entropy(dataSet)
# print('经验熵为:', entropy_value)
feature_set = create_feature_set(dataSet) # 特征集
# print(feature_set)
DA_all = []
for key in feature_set: # 遍历每一列[0,1,2,3]
DA = conditional_entropy(dataSet, key) # 当前按i维特征划分的信息增益
print('第%d列特征对数据集D的条件熵为:%f'%(key, DA))
DA_all.append(DA)
g_DA_All = entropy(dataSet, feature_key = -1) - np.array(DA_all)
print('\n')
for value in range(len(g_DA_All)):
print('第%d列特征对数据集D的信息增益值为:%f'%(value, g_DA_All[value]))
测试结果:
第0列特征对数据集D的条件熵为:0.887943
第1列特征对数据集D的条件熵为:0.647300
第2列特征对数据集D的条件熵为:0.550978
第3列特征对数据集D的条件熵为:0.607961
第0列特征对数据集D的信息增益值为:0.083007
第1列特征对数据集D的信息增益值为:0.323650
第2列特征对数据集D的信息增益值为:0.419973
第3列特征对数据集D的信息增益值为:0.362990
通过数学公式可以直接计算出第iii列特征(Ai+1A_{i+1}Ai+1)对数据集DDD的条件熵与信息增益值。例如,对于第000列特征(A1A_1A1)对数据集DDD的条件熵与信息增益值。
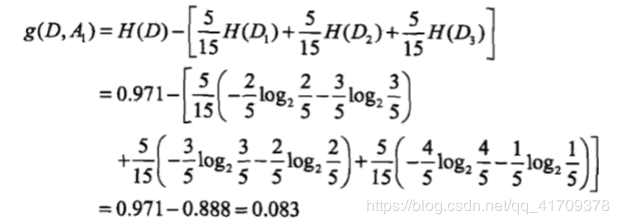
第000列特征(A1A_1A1)对数据集DDD的条件熵为:0.888
信息增益值为:0.083
决策树算法作为一种分类算法,目标就是将具有m个特征的n个样本分到c个类别中去。相当于做一个投影,c=f(n),将样本经过一种变换赋予一种类别标签。决策树为了达到这一目的,把分类的过程表示成一棵树,每次通过选择一个特征 mim_imi 来进行分叉。
那么怎样选择分叉的特征呢?
每一次分叉选择哪个特征对样本进行划分可以最快最准确的对样本分类呢?
不同的决策树算法有着不同的特征选择方案。
ID3用信息增益,C4.5用信息增益率,CART用gini系数。
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。ID3相当于用极大似然法进行概率模型的选择。
具体方法是:
1)从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征。
2)由该特征的不同取值建立新的子节点,再对子结点递归地调用以上方法,构建决策树;
3)直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。
决策树结束的条件是:
程序完全遍历所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类,如果所有实例具有相同的分类,则得到一个叶子节点或者终止块,任何到达叶子节点的数据必然属于叶子节点的分类。
算法步骤:


仍然使用决策树构造中的案例(制定一个贷款申请的决策树),编写ID3算法为:
# -*- coding: utf-8 -*-
# @Time : 2020/4/10 19:20
import numpy as np
from math import log
class Node: # 结点
def __init__(self, data = None):
self.data = data
self.child = {}
class DecisionTree: # 决策树
def create(self, dataset, labels, option="ID3"):
"""
:param dataset:
:param labels: description
:param option: "ID3/C4.5"
:return: a root node
"""
feature_set = self.create_feature_set(dataset) # 特征集
# like {0: ['老年', '青年', '中年'], 1: ['否', '是'], 2: ['否', '是'], 3: ['好', '一般', '非常好']}
def create_branch(dataset, feature_set):
label = [row[-1] for row in dataset] # 按列读取标签
node = Node()
# TODO: 算法5.2步骤(2)
if (len(set(label)) == 1): # 意味着单结结点,不需要再分
node.data = label[0]
node.child = None
return node
# TODO: 算法5.2步骤(3)
HD = self.entropy(dataset) # 数据集的熵
max_ga = 0 # 最大信息增益
max_ga_key = 0 # 最大信息增益的索引
for key in feature_set: # 计算最大信息增益
g_DA = HD - self.conditional_entropy(dataset, key) # 当前按i维特征划分的信息增益
# 这里是计算信息增益比,跳过下面的判断,就是用ID3算法,否则就是C4.5算法
if option == "C4.5":
g_DA = g_DA / float(self.entropy(dataset, key))
if (max_ga < g_DA):
max_ga = g_DA
max_ga_key = key
# TODO: 算法5.2步骤(4)
node.data = labels[max_ga_key]
sub_feature_set = feature_set.copy()
print(node.data) # 非叶子结点
# print(sub_feature_set)
del sub_feature_set[max_ga_key] # 删除特征集(根结点已经确定,不再作为划分依据)
# print(feature_set[max_ga_key])
for x in feature_set[max_ga_key]: # 这里是计算出信息增益后,知道了需要按哪一维进行划分集合
print(x) # 分支
sub_data_set = [row for row in dataset if row[max_ga_key] == x] # 这个可以得出某一列的数据子集
node.child[x] = create_branch(sub_data_set, sub_feature_set) # continue to split the sub data set
# print(node.__dict__) # 返回结点中元素的类别
return node
return create_branch(dataset, feature_set)
def create_feature_set(self, dataset): # 创建特征集,特征集是样本每个维度的值域(取值)
"""
like {0: ['老年', '青年', '中年'], 1: ['否', '是'], 2: ['否', '是'], 3: ['好', '一般', '非常好']}
"""
feature_set = {}
m, n = np.shape(dataset) # m means rows, n means columns
for axis in range(n - 1): # 按列来遍历,n-1代表不存入类别的特征(标签不存入)
column = list(set([row[axis] for row in dataset])) # 按列提取数据,并用set过滤
feature_set[axis] = column # 每一行就是每一维的特征值
return feature_set
def conditional_entropy(self, dataset, feature_key): #条件经验熵
column = [row[feature_key] for row in dataset] #读取i列
conditional_entropy = 0
for x in set(column): #划分数据集,并计算
sub_data_set = [row for row in dataset if row[feature_key] == x] #按i轴的特征划分数据子集
conditional_entropy += (column.count(x) / float(len(column))) * self.entropy(sub_data_set) #p*entropy(sub_data_set)
return conditional_entropy
def entropy(self, dataset, feature_key = -1): #计算熵
column = [row[feature_key] for row in dataset] # 获取标签值
feature_set = set(column) # 对标签进行去重复
entropy = 0.0
for x in feature_set: # 遍历标签值
p = column.count(x) / float(len(column)) # 统计各标签个数p
entropy -= p * log(p, 2)
return entropy
if __name__ == "__main__":
dataset = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否']]
description = ['年龄', '有工作', '有自己的房子', '信贷情况'] #the description of samples, the internal node data is one of this description
tree = DecisionTree()
node = tree.create(dataset, description, option="C4.5")
测试结果:
有自己的房子
否
有工作
否
是
是
《统计学习方法》书籍中用确确实实的数学公式进行了推导,确定哪几种特征作为内部结点,通过计算,得到“有自己的房子”特征信息增益最大,选择这一个作为根结点,通过剔除根节点后,再对剩余特征进行计算最大的信息增益,选取信息增益最大的特征“有工作”,在对工作进行分类时,有工作与没有工作的信息熵为1,不再进行特征点的划分,以下图片为决策树的生成图。
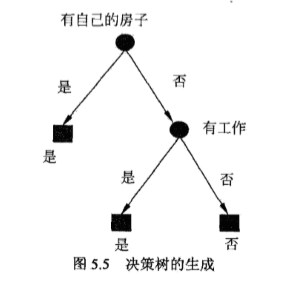
程序结果也显示了根结点为:有自己的房子。
剔除根节点后,内部节点为:有工作。
为了方便学习,这里有更加详细的C4.5介绍过程。
链接: C4.5算法详解(非常仔细)
与ID3算法类似,C4.5用信息增益率将信息增益比作为选择特征的标准。
在ID3算法程序中体现在:
# 这里是计算信息增益比,跳过下面的判断,就是用ID3算法,否则就是C4.5算法
if option == "C4.5":
g_DA = g_DA / float(self.entropy(dataset, key))
算法过程:

PS:C4.5生成算法代码在ID3算法代码中
决策树生成算法递归的产生决策树,直到不能继续下去为止,这样产生的树往往对训练数据的分类很准确,但对未知测试数据的分类缺没有那么精确,即会出现过拟合现象。过拟合产生的原因在于在学习时过多的考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树,解决方法是考虑决策树的复杂度,对已经生成的树进行简化。
剪枝(pruning):从已经生成的树上裁掉一些子树或叶节点,并将其根节点或父节点作为新的叶子节点,从而简化分类树模型。
实现方式:极小化决策树整体的损失函数或代价函数来实现。
1. C(T)C\left( T \right)C(T):表示模型对训练数据的预测误差
2. ∣T∣|T|∣T∣:表示模型复杂度
3. a:参数a≥0控制两者之间的影响,较大的a促使选择较简单的模型(树),较小的a促使选择较复杂的模型(树)。
4. t是树T的叶结点,叶结点有N,个样本点,其中k类的样本点有NtkN_{tk}Ntk个。
决策树学习的损失函数定义为:
Cα(T)=∑t=1TNtHt(T)+α∣T∣{C_\alpha }\left( T \right) = \sum\limits_{t = 1}^T {{N_t}{H_t}} \left( T \right) + \alpha |T|Cα(T)=t=1∑TNtHt(T)+α∣T∣
目标是获取损失函数最小的决策树。
其中经验熵为:
Ht(T)=−∑k∣Ntk∣∣Nt∣log2∣Ntk∣∣Nt∣{H_t}\left( T \right) = - \sum\limits_k {\frac{{|{N_{tk}}|}}{{|{N_t}|}}} {\log _2}\frac{{|{N_{tk}}|}}{{|{N_t}|}}Ht(T)=−k∑∣Nt∣∣Ntk∣log2∣Nt∣∣Ntk∣
C(T)=∑t=1TNtHt(T)=−∑t=1T∑kKNtklog2∣Ntk∣∣Nt∣C\left( T \right) = \sum\limits_{t = 1}^T {{N_t}{H_t}} \left( T \right) = - \sum\limits_{t = 1}^T {\sum\limits_k^K {{N_{tk}}} {{\log }_2}\frac{{|{N_{tk}}|}}{{|{N_t}|}}}C(T)=t=1∑TNtHt(T)=−t=1∑Tk∑KNtklog2∣Nt∣∣Ntk∣
Cα(T)=C(T)+α∣T∣{C_\alpha }\left( T \right) = C\left( T \right) + \alpha |T|Cα(T)=C(T)+α∣T∣
算法5.4 (树的剪枝算法)
输入:生成算法产生的整个树T,参数a;
输出:修剪后的子树Tg.
(1)计算每个结点的经验熵.
(2)递归地从树的叶结点向上回缩.
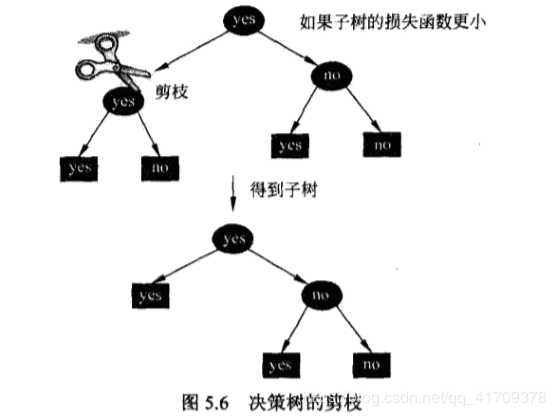
如果Cα(TA)≤Cα(TB){C_\alpha }\left( {{T_A}} \right) \le {C_\alpha }\left( {{T_B}} \right)Cα(TA)≤Cα(TB)则进行剪枝,即将父结点变为新的叶结点。
(3) 循环执行(2),直至不能继续为止,得到损失函数最小的子树T。.
决策树的剪枝过程就是从叶子节点开始递归,记其父节点将所有子节点回缩后的子树为TB{{T_B}}TB(分类值取类别比例最大的特征值),未回缩的子树为TA{{T_A}}TA如果Cα(TA)≤Cα(TB){C_\alpha }\left( {{T_A}} \right) \le {C_\alpha }\left( {{T_B}} \right)Cα(TA)≤Cα(TB)说明回缩后使得损失函数减小了,那么应该使这棵子树回缩,递归直到无法回缩为止。
可以看出,决策树的生成只是考虑通过提高信息增益对训练数据进行更好的拟合,而决策树剪枝通过优化损失函数还考虑了减小模型复杂度。
sklearn中的决策树在sklearn库中,可以使用sklearn.tree.DecisionTreeClassifier来创建一个决策树用于分类。
from sklearn.preprocessing import LabelEncoder # 用于序列化
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.model_selection import cross_val_score # 导入计算交叉检验值的函数cross_val_score
创建决策树:
# 创建一颗基于基尼系数的决策树
clf = DecisionTreeClassifier(criterion="gini", max_features=None)
主要参数有:
criterion: 用于选择属性的准则,可以传入“gini"代表基尼系数,或者“entropy代表信息增益
max features:表示在决策树结点进行分裂时,从多少个特征中选择最优特征。可以设定固定数目、百分比或其他标准。它的默认值是使用所有特征个数。
1.数据来源
为了方便学习,我上传了数据:
百度网盘链接: 点我获取隐形眼镜类型数据.
提取码:2y3i
2.处理文本获取数据
处理.txt文本,获取每一列的特征值,及最后一列目标标签值。
fr = open('lenses.txt', 'r')
lenses = [inst.strip().split('\t') for inst in fr.readlines()] # 去掉空格,提取每组数据的类别,保存在列表里
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] # 特征标签
lenses_target = [row[-1] for row in lenses] # 目标标签
lenses_list = [] # 保存lenses数据的临时列表
lenses_dict = {} # 保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels:
# 提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
lenses_data = pd.DataFrame(lenses_dict) # 生成pandas.DataFrame
3.序列化
lenses_data = pd.DataFrame(lenses_dict) # 生成pandas.DataFrame
le = LabelEncoder() # 创建LabelEncoder()对象,用于序列化
for col in lenses_data.columns:
# 为每一列序列化
lenses_data[col] = le.fit_transform(lenses_data[col])
lenses_target = le.fit_transform(lenses_target) # 将标签序列化
序列化后的数据显示:
age astigmatic prescript tearRate
0 2 0 1 1
1 2 0 1 0
2 2 1 1 1
3 2 1 1 0
4 2 0 0 1
三:预测类型
1. 待预测的数据集
选取三个测试集用来测试分类:
test = [ [“presbyopic”, “yes”, “myope”, “normal”],[“young”, “no” ,“myope”, “normal”],[“pre”, “yes”, “hyper”, “reduced”] ]
测试集序列化后的值为
test = [ [1, 1, 1, 0], [2, 0, 1, 0], [0, 1, 0, 1] ]
2. 预测结果显示
运用 决策树 预测分类结果: [0 2 1]
预测后:
test[0] 对应的目标标签为:hard
test[1] 对应的目标标签为:soft
test[2] 对应的目标标签为:no lenses
3. 图像可视化
运用Matplotllb模块可以绘制决策树的可视图。
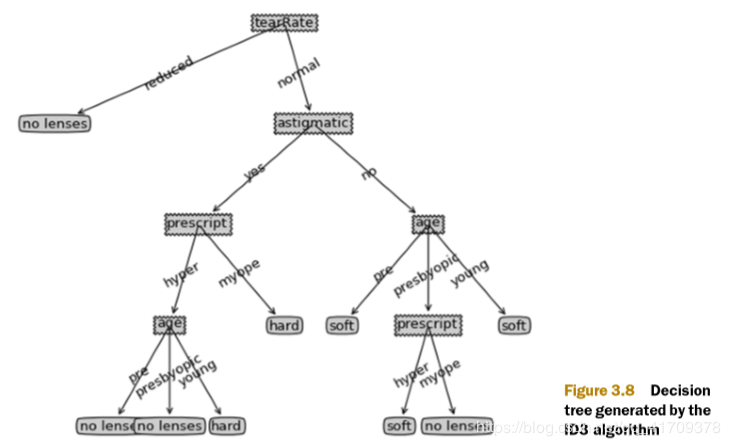
4. 完整程序:
# -*- coding: utf-8 -*-
# @Time : 2020/4/10 21:13
'''
1.决策树预测隐形眼镜类型
'''
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder # 用于序列化
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
from sklearn.model_selection import cross_val_score # 导入计算交叉检验值的函数cross_val_score
fr = open('lenses.txt', 'r')
lenses = [inst.strip().split('\t') for inst in fr.readlines()] # 去掉空格,提取每组数据的类别,保存在列表里
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] # 特征标签
lenses_target = [row[-1] for row in lenses] # 目标标签
# print(lenses_target)
lenses_list = [] # 保存lenses数据的临时列表
lenses_dict = {} # 保存lenses数据的字典,用于生成pandas
for each_label in lensesLabels:
# 提取信息,生成字典
for each in lenses:
lenses_list.append(each[lensesLabels.index(each_label)])
lenses_dict[each_label] = lenses_list
lenses_list = []
lenses_data = pd.DataFrame(lenses_dict) # 生成pandas.DataFrame
# print(lenses_data)
le = LabelEncoder() # 创建LabelEncoder()对象,用于序列化
for col in lenses_data.columns:
# 为每一列序列化
lenses_data[col] = le.fit_transform(lenses_data[col])
lenses_target = le.fit_transform(lenses_target) # 将标签序列化
# print(lenses_target)
# print(lenses_data)
lenses_data = np.array(lenses_data)
lenses_target = np.array(lenses_target)
# 创建一颗基于基尼系数的决策树
clf = DecisionTreeClassifier(criterion="gini", max_features=None)
score = cross_val_score(clf, lenses_data, lenses_target, cv = 10) # 使用10折交叉验证
clf.fit(lenses_data, lenses_target) # fit()训练模型
# 待预测的测试集
test = [
[1, 1, 1, 0],
[2, 0, 1, 0],
[0, 1, 0, 1]]
pre_test_tree = clf.predict(test) # 决策树,函数预测
print('运用 决策树 预测分类结果:',pre_test_tree)
5 测试案例2:鸢尾花数据集分类
1. 鸢尾花数据展示: 数据-图片.
首先,我们导入sklearn内嵌的鸢尾花数据集:from sklearn.datasets import load_ jiris,接下来,我们使用import语句导入决策树分类器,同时导入交叉检验值的函数cross_val_score。
from sklearn.datasets import load_iris #导入鸢尾花训练集
from sklearn.tree import DecisionTreeClassifier #导入决策树分类器
from sklearn.model_selection import cross_val_score #导入计算交叉检验值的函数cross_val_score
2. 决策树的使用:
与“案例一” 一样,我们使用默认参数,创建一颗基 于基尼系数的决策树,并将该决策树分类器赋值给变量clf,将鸢尾花数据赋值给变量iris。
#创建一颗基于基尼系数的决策树
clf = DecisionTreeClassifier()
#将鸢尾花数据赋值给变量iris
iris = load_iris()
这里我们将决策树分类器做为待评估的模型,iris.data鸢尾花数据做为特征,iris.target鸢尾花分类标签做为目标结果,通过设定cv为10,使用10折交叉验证,得到最终的交叉验证得分。
data = iris.data #鸢尾花数据作为特征,
target = iris.target #鸢尾花数据作为目标结果[0,1,2],
cv = 10 #使用10折交叉验证
score = cross_val_score(clf, data, target, cv = 10)
用 fit() 函数训练模型,并使用predict() 函数预测。
clf.fit(data, target) #fit()训练模型
test = [[5.1, 3.5, 1.4, 0.2],
[4., 2.2, 1.7, 0.4],
[5.9, 3., 5.1, 1.8]]
pre_test_tree = clf.predict(test) #决策树 函数预测
3. 测试结果:
运用 决策树 预测分类结果: [0 0 2]
在用测试用例test进行测试时,鸢尾花数据的不同特征的值,将决定预测的分类。
4. 完整程序:
# -*- coding: utf-8 -*-
# @Time : 2020/4/10 22:36
'''
1.机器学习-监督学习(分类)
运用鸢尾花数据集:决策树模型
'''
from sklearn.datasets import load_iris #导入鸢尾花训练集
from sklearn.tree import DecisionTreeClassifier #导入决策树分类器
from sklearn.model_selection import cross_val_score #导入计算交叉检验值的函数cross_val_score
#创建一颗基于基尼系数的决策树
clf = DecisionTreeClassifier()
#将鸢尾花数据赋值给变量iris
iris = load_iris()
data = iris.data #鸢尾花数据作为特征,
target = iris.target #鸢尾花数据作为目标结果[0,1,2],
cv = 10 #使用10折交叉验证
cross_val_score(clf, data, target, cv = 10)
clf.fit(data, target) #fit()训练模型
test = [[5.1, 3.5, 1.4, 0.2],
[4., 2.2, 1.7, 0.4],
[5.9, 3., 5.1, 1.8]]
pre_test_tree = clf.predict(test) #决策树 函数预测
print('运用 决策树 预测分类结果:',pre_test_tree)
总结:
决策树的生成往往通过计算信息增益或其他指标,从根结点开始,递归地产生决策树、这相当于用信息增益或其他准则不断地选取局部最优的特征,或将训练集分割为能够基本正确分类的子集。 决策树本质上是寻找一种对特征空间上的划分,旨在构建一个训练数据拟合的好,并且复杂度小的决策树。在运用python编写决策树模型,实际调用sklearn库DecisionTreeClassifier模块,需要根据数据情况,选取特点的传入参数,比如选择合适的criterion,设置随机变量等。参考书籍:
[1] 李航. 统计学习方法[M]. 北京:清华大学出版社,2012
[2]《机器学习实战-中文版》
附录了两本书的下载链接:
链接: 书籍下载.
提取码:g8bn
作者:三个半_Z