Python爬取煎蛋网图片
Python爬取煎蛋网图片
1.请求网页函数

 5.完整代码
5.完整代码
作者:MuMengSunny
def get_url(url):
html = requests.get(url, headers=header).content.decode('utf-8')
return html
以get方式请求,加入headers参数传递头信息;抓取其二进制码并以“utf-8”形式编码,并返回;
2.解析网页,提取图片链接def parsel_url(html):
etree_html=etree.HTML(html)
img_urls=etree_html.xpath("//div[@class='row']/div[@class='text']/p/img/@src")
return img_urls
利用xpath语法提取图片链接
3.下载图片并保存#循环下载;下载4页,range左闭右开
for i in range(5):
#输入网址,找到网址规律
url = 'http://jandan.net/ooxx/MjAyMDAzMTQtMjE{}#comments'.format(i)
#请求网页
html=get_url(url)
#解析网页,提取图片链接
img_urls = parsel_url(html)
for img_url in img_urls:
#因为提取的网页链接不是网址标准形式,需要完善
response = requests.get('http:' + img_url, headers=header).content
#图片以二进制形式保存
with open("F://picture3//" + str(name) + '.jpg', 'wb') as f:
f.write(response)
#下载提示
print('正在下载第{}张'.format(name))
name += 1
利用name变量提示下载图片数量
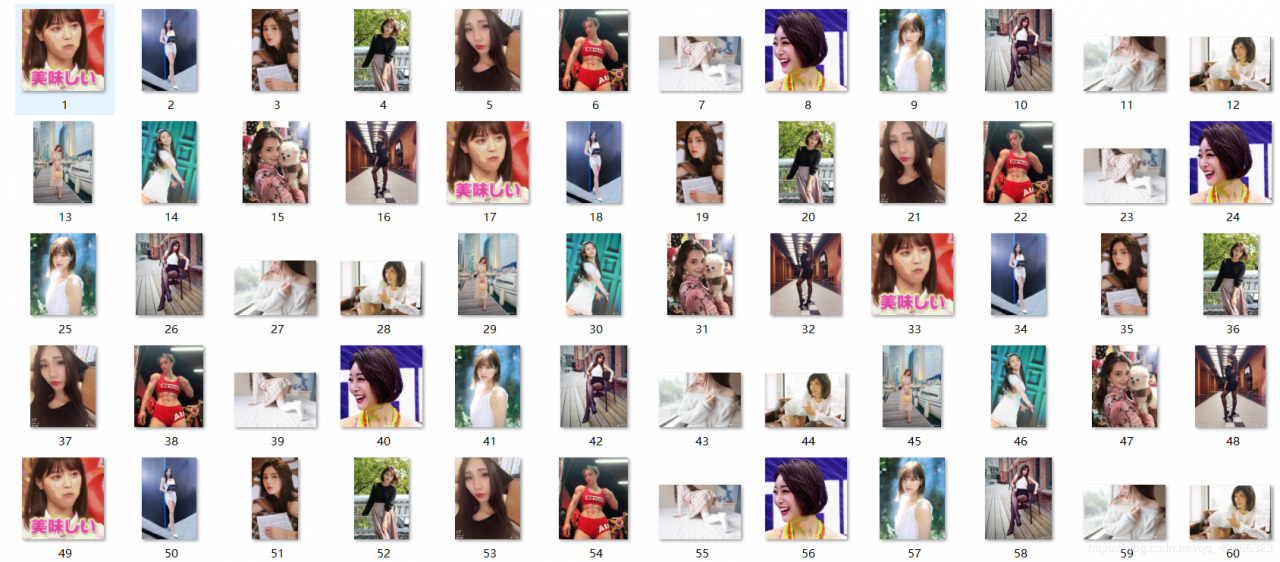
4.程序效果
5.完整代码
import requests
from lxml import etree
#用户代理
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
}
#用name表示下载的名字
name=1
#请求网页函数
def get_url(url):
html = requests.get(url, headers=header).content.decode('utf-8')
return html
#解析网页
def parsel_url(html):
etree_html=etree.HTML(html)
img_urls=etree_html.xpath("//div[@class='row']/div[@class='text']/p/img/@src")
return img_urls
#循环下载;下载4页,range左闭右开
for i in range(5):
#输入网址,找到网址规律
url = 'http://jandan.net/ooxx/MjAyMDAzMTQtMjE{}#comments'.format(i)
#请求网页
html=get_url(url)
#解析网页,提取图片链接
img_urls = parsel_url(html)
for img_url in img_urls:
#因为提取的网页链接不是网址标准形式,需要完善
response = requests.get('http:' + img_url, headers=header).content
#图片以二进制形式保存
with open("F://picture3//" + str(name) + '.jpg', 'wb') as f:
f.write(response)
#下载提示
print('正在下载第{}张'.format(name))
name += 1
作者:MuMengSunny