基于机器视觉的乳液泵缺陷检测方法研究
Faster-RCNN+FPN+Dilation/DCN+ROI Align+Coco预训练+Focal Loss+Soft-NMS+投票平均+OHEM(batch级别)
1 Faster-RCNN(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
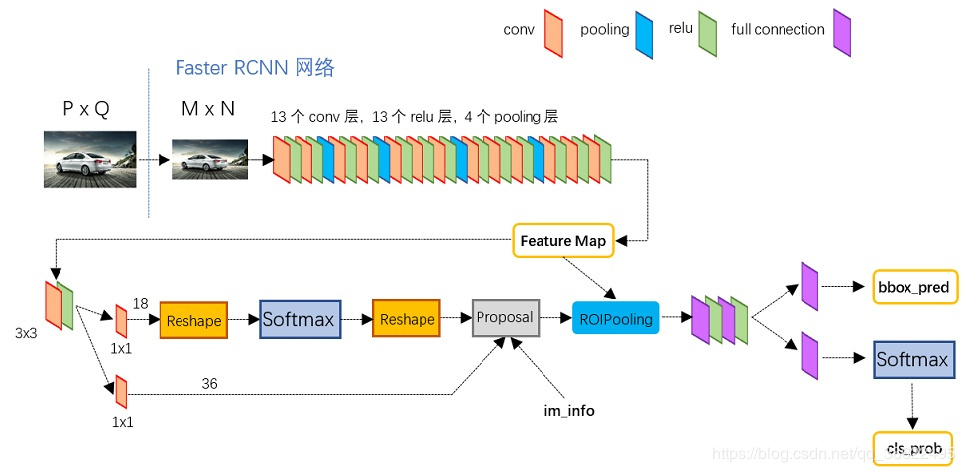
包含了conv,pooling,relu三种层
1.1.1 VGGConv layers部分共有13个conv层,13个relu层,4个pooling层。这里有一个非常容易被忽略但是又无比重要的信息,在Conv layers中:
所有的conv层都是: kernel_size=3kernel\_size=3kernel_size=3 , pad=1pad=1pad=1 ,stride=1stride=1stride=1 所有的pooling层都是: kernel_size=2kernel\_size=2kernel_size=2 , pad=0pad=0pad=0 , stride=2stride=2stride=2 Conv layers中的conv层不改变输入和输出矩阵大小 1.2 Region Proposal Networks(RPN)
1.2 Region Proposal Networks(RPN)
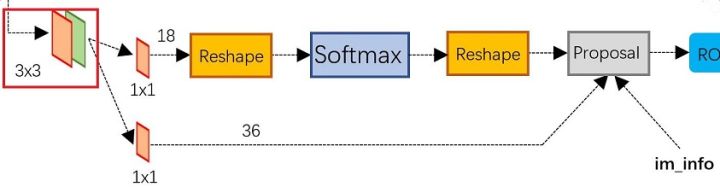
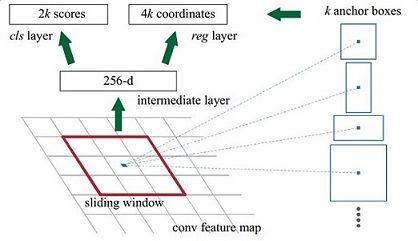 在原文中使用的是ZFmodel中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,相当于一张feature map每个点用256-D的特征表示。
由于输入图像M=800,N=600,且Conv Layers做了4次Pooling,feature map的长宽为[M/16, N/16]=[50, 38]
在conv5之后,做了rpn_conv/3x3卷积,num_output=256,相当于每个点使用了周围3x3的空间信息,同时256-d不变,如图3红框,同时对应图4中的红框中的3x3卷积
假设一共有k个anchor,而每个anhcor要分foreground和background,所以cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
在原文中使用的是ZFmodel中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,相当于一张feature map每个点用256-D的特征表示。
由于输入图像M=800,N=600,且Conv Layers做了4次Pooling,feature map的长宽为[M/16, N/16]=[50, 38]
在conv5之后,做了rpn_conv/3x3卷积,num_output=256,相当于每个点使用了周围3x3的空间信息,同时256-d不变,如图3红框,同时对应图4中的红框中的3x3卷积
假设一共有k个anchor,而每个anhcor要分foreground和background,所以cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
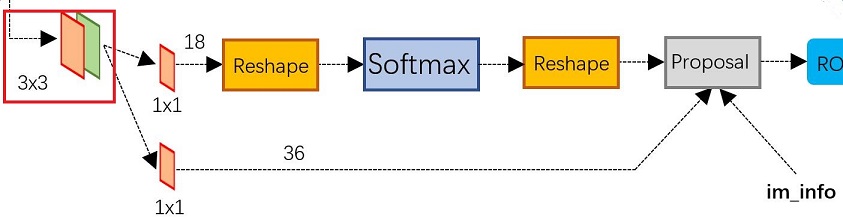
其实RPN就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud,仅仅是个二分类。
anchor原图800x600,VGG下采样16倍,feature map每个点设置9个Anchor:
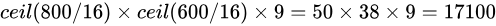
其中ceil()表示向上取整,是因为VGG输出的feature map size= 50*38。
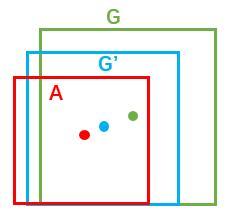
绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。

对于窗口一般使用四维向量 (x,y,w,h)(x, y, w, h)(x,y,w,h)表示,分别表示窗口的中心点坐标和宽高。红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G’。
给定:anchorA=(Ax,Ay,Aw,Ah)anchor A=(A_{x}, A_{y}, A_{w}, A_{h})anchorA=(Ax,Ay,Aw,Ah) 和 GT=[Gx,Gy,Gw,Gh]GT=[G_{x}, G_{y}, G_{w}, G_{h}]GT=[Gx,Gy,Gw,Gh]
寻找一种变换F,使得:F(Ax,Ay,Aw,Ah)=(Gx′,Gy′,Gw′,Gh′)F(A_{x}, A_{y}, A_{w}, A_{h})=(G_{x}^{'}, G_{y}^{'}, G_{w}^{'}, G_{h}^{'})F(Ax,Ay,Aw,Ah)=(Gx′,Gy′,Gw′,Gh′),其中(Gx′,Gy′,Gw′,Gh′)≈(Gx,Gy,Gw,Gh)(G_{x}^{'}, G_{y}^{'}, G_{w}^{'}, G_{h}^{'})≈(G_{x}, G_{y}, G_{w}, G_{h})(Gx′,Gy′,Gw′,Gh′)≈(Gx,Gy,Gw,Gh)
平移(Δx,Δy)(\Delta x,\Delta y)(Δx,Δy)
水平方向:Δx=Awdx(A)⇀Gx′=Ax+Δx\Delta x=A_{w}d_{x}(A)\rightharpoonup G^{'}_{x}=A_{x}+\Delta xΔx=Awdx(A)⇀Gx′=Ax+Δx 竖直方向:Δy=Awdy(A)⇀Gy′=Ay+Δy\Delta y=A_{w}d_{y}(A)\rightharpoonup G^{'}_{y}=A_{y}+\Delta yΔy=Awdy(A)⇀Gy′=Ay+Δy尺度缩放
宽度:Gw′=Awe(dw(A))G^{'}_{w}=A_{w}e^{(d_{w}(A))}Gw′=Awe(dw(A)) 高度:Gh′=Ahe(dh(A))G^{'}_{h}=A_{h}e^{(d_{h}(A))}Gh′=Ahe(dh(A))当Anchor与Ground Truth 相差较少时(RCNN设置Iou是0.6),可以认为变换是一种线性变换,所以可以用线性回归对建模进行微调。
FPN作者:爱弹ukulele的程序猿