Java容器之Hashtable源码分析
在上一篇博客 Java容器之HashMap源码分析(妈妈再也不用担心我不懂HashMap了) 从源码层次分析了HashMap容器的底层实现,在本篇博客将继续从源码层次分析Hashtable的底层实现。
注明:以下源码分析都是基于jdk 1.8.0_221版本

Hashtable容器概述(一图以蔽之)
Java中的Hashtable容器也是一个用来存放key-value(键值对)的容器,主要由table数组和若干链表组成。
Hashtable容器类的声明如下:
public class Hashtable extends Dictionaryimplements Map, Cloneable, java.io.Serializable
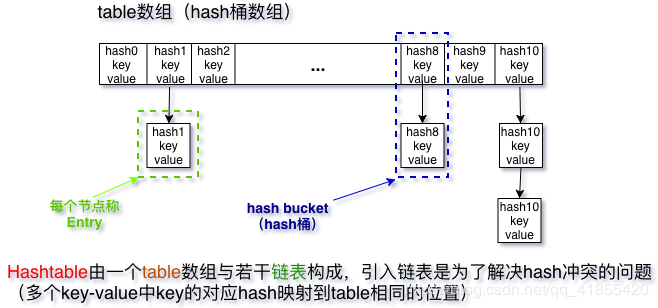
注明:既然Java已经有了HashMap容器,为啥还有引入Hashtable?应该有部分小伙伴对此有疑问。通过对比HashMap、Hashtable容器的功能,可以发现,两者都是key-value容器,不过HashMap是线程不安全的容器,即不能多个线程同时访问一个HashMap容器;而Hashtable容器是线程安全的,即Hashtable容器支持多个线程同时访问(通过synchronized关键字,this锁实现)。
Hashtable类的属性
Hashtable类中的主要属性如下:
/**
* table数组(hash桶数组),用于存放key-value数据
*/
private transient Entry[] table;
/**
* 容器中已经存放的key-value个数
*/
private transient int count;
/**
* 容器可存放key-value的阈值 = capacity * loadFactor
* capacity是容器的容量(table数组的长度,初始化时默认是11)
* loadFactor是负载因子,默认是0.75
*/
private int threshold;
/**
* 负载因子,默认是0.75
*/
private float loadFactor;
/**
* 用于记录容器结构性调整(增删Entry、rehash等)的次数
*/
private transient int modCount = 0;
/**
* 序列化版本ID
*/
private static final long serialVersionUID = 1421746759512286392L;
/**
* keySet用于存放容器中的所有key
* values用于存放容器中的所有value
* entrySet以set容器形式存放Entry,一般遍历Hashtable会用到此属性
*/
private transient volatile Set keySet;
private transient volatile Set<Map.Entry> entrySet;
private transient volatile Collection values;
注意:\color{red}注意:注意:capacity是容器的容量(table数组的长度,初始化时默认是11),count记录容器中已经存放的key-value个数,threshold记录容器可存放key-value的阈值 = 容器容量 * 负载因子。
Hashtable类的构造器
Hashtable类有四个构造器,分别如下:
/**
* @param initialCapacity 容器容量(table数组的长度)初始化参数
* @param loadFactor 负载因子
* @exception IllegalArgumentException initialCapacity、loadFactor参数非法异常
*/
public Hashtable(int initialCapacity, float loadFactor) {
// 检查initialCapacity、loadFactor参数的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
// 忙活了半天不能初始化空的容器吧。。。
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
// 计算容器可存放的key-value数量阈值,容量 * 负载因子
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
/**
* 默认负载因子为0.75的构造器
*
* @param initialCapacity 容器容量(table数组的长度)初始化参数
* @exception IllegalArgumentException initialCapacity参数非法异常
*/
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
/**
* 容器容量默认为11,负载因子默认为0.75
*/
public Hashtable() {
this(11, 0.75f);
}
/**
* 复制构造函数,用其它map容器初始化当前new的容器对象
*/
public Hashtable(Map t) {
// 先调用构造函数public Hashtable(int initialCapacity, float loadFactor)
// 一般Hashtable默认容量大小为11,所以不能比它还小
this(Math.max(2*t.size(), 11), 0.75f);
// 然后将容器t中的所有entry复制到新建的容器对象中
putAll(t);
}
四、增加key-value相关方法
1、addEntry方法
addEntry方法的作用是往容器中放入一个entry,注意此方法没有使用synchronized关键字修饰,但是用的private关键字修饰,也就是说不对外开发。只要是在本类调用addEntry的其它方法是线程同步,那么也不会产生线程不安全的状况。
/**
* @parm hash 通过调用hashCode()得到的hash值
* @parm key 键值对中的key
* @parm value 键值对中的value
* @parm index hash对应的table数组的预期下标
*/
private void addEntry(int hash, K key, V value, int index) {
// 插入节点,属于结构性调整
modCount++;
Entry tab[] = table;
if (count >= threshold) {
// 如果容器当前存放的key-value数量达到了threshold阈值(容器容量 * 负载因子)
// 则需要进行rehash扩容操作
rehash();
// 由于进行rehash操作,则key对应的hash需要重新计算,hash对应的下标也要重新计算
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 根据key-value,新建一个entry,放入tab[index]中
@SuppressWarnings("unchecked")
Entry e = (Entry) tab[index];
// 注意Entry的构造函数的第四个参数是next,也就是把tab[index] = new Entry
// 然后让new Entry.next = e(未更新前tab[index]指向的内容)
tab[index] = new Entry(hash, key, value, e);
count++;
}
2、put方法
put方法用了synchronized、public关键字修饰,对外开放,并且是线程安全。(synchronized关键字修饰非静态方法,用的是this锁)
/**
* @param key the hashtable key
* @param value the value
* @return 如果容器已经有key,更新value并且返回旧value,否则插入并且返回空
* @exception NullPointerException if the key or value is
* null
*/
public synchronized V put(K key, V value) {
// 确保value不能为空
if (value == null) {
throw new NullPointerException();
}
// 计算key对应的hash以及hash对应在table数组中的下标
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// entry直线table[index],即hash对应的链表头部
Entry entry = (Entry)tab[index];
// 遍历这个链表
for(; entry != null ; entry = entry.next) {
// 如果key已经存在,修改新的value,并且返回之前的value
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 否则调用addEntry方法插入,当前方法已经加了synchronized关键字,所以addEntry不会产生线程不安全的状况
addEntry(hash, key, value, index);
return null;
}
3、putAll方法
putAll方法的作用是将其他map容器中的元素复制到当前容器中,使用了synchronized关键字修饰,所以不会引发线程安全的状况。
/**
* 作用是将其他map容器中的元素复制到当前容器中
*/
public synchronized void putAll(Map t) {
// 遍历容器t将key-value一一复制到当前容器中
for (Map.Entry e : t.entrySet())
put(e.getKey(), e.getValue());
}
五、删除key-value相关方法
1、remove(key)方法
remove(key)方法的作用是通过key删除key-value。
/**
* 通过key移除key-value
* @param key the key that needs to be removed
* @return 移除成功返回key对应的value,否则返空
* @throws NullPointerException if the key is null
*/
public synchronized V remove(Object key) {
Entry tab[] = table;
// 计算key对应的hash值,从而找到key在table数组中的下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 获取hash值对应的链表头部
Entry e = (Entry)tab[index];
// 遍历此链表,pre指向的e前面的节点
for(Entry prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
// key匹配成功
// 移除节点也是结构性调整
modCount++;
if (prev != null) {
// 如果e前面(pre)不为空,则直接把e移除链表即可
prev.next = e.next;
} else {
// 否则e就是链表的表头tab[index],则需要更新tab[index]
tab[index] = e.next;
}
count--;
// 返回移除前key-value中的value
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
2、remove(key,value)方法
remove(key,value)方法是通过key-value删除,只有两个都匹配成功才进行删除操作。此方法同样使用了synchronized关键字修饰,所以不会引发线程不安全的问题。
public synchronized boolean remove(Object key, Object value) {
Objects.requireNonNull(value);
Entry tab[] = table;
// 计算key对应的hash值,从而找到key在table数组中的下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
// 获取hash值对应的链表头部
Entry e = (Entry)tab[index];
// 遍历此链表,pre指向的e前面的节点
for (Entry prev = null; e != null; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key) && e.value.equals(value)) {
// key匹配成功
// 移除节点也是结构性调整
modCount++;
if (prev != null) {
// 如果e前面(pre)不为空,则直接把e移除链表即可
prev.next = e.next;
} else {
// 否则e就是链表的表头tab[index],则需要更新tab[index]
tab[index] = e.next;
}
count--;
e.value = null;
// 删除成功则返回true
return true;
}
}
return false;
}
六、查找key-value相关方法
1、get(key)方法
get(key)方法的作用是通过key查找value,该方法同样使用了synchronized关键字修饰。
/**
* 通过`key`查找`value`
*/
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry tab[] = table;
// 计算key对应的hash值,从而找到key在table数组中的下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 遍历tab[index]这个链表,查找key对应的value
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
2、containsKey(key)方法
containsKey(key)方法的作用是判断容器中是否存在key,该方法也使用了synchronized关键字修饰。
/**
* 判断容器中是否窜在key
*/
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
// 计算key对应的hash值,从而找到key在table数组中的下标
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 遍历tab[index]链表,查找key
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
3、containsValue(value)方法
containsValue(value)方法判断容器中是否存在value,该方法也使用了synchronized关键字修饰。
/**
* 判断容器中是否存在`value`
*/
public synchronized boolean contains(Object value) {
if (value == null) {
// 由于Hashtable的key、value都不能为空,所以为null的value不需要查找
throw new NullPointerException();
}
// 此时需要遍历整个table数组
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
// 遍历tab[i] 每个链表
for (Entry e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
七、其它方法
1、hashCode方法
hashCode方法的效果类似于重写Object类的hashCode方法。
/**
* 返回容器对应的hash值
*/
public synchronized int hashCode() {
/*
* This code detects the recursion caused by computing the hash code
* of a self-referential hash table and prevents the stack overflow
* that would otherwise result. This allows certain 1.1-era
* applets with self-referential hash tables to work. This code
* abuses the loadFactor field to do double-duty as a hashCode
* in progress flag, so as not to worsen the space performance.
* A negative load factor indicates that hash code computation is
* in progress.
*/
int h = 0;
if (count == 0 || loadFactor < 0)
return h; // Returns zero
//
loadFactor = -loadFactor; // Mark hashCode computation in progress
Entry[] tab = table;
// 将所有entry对应的hashCode求和
for (Entry entry : tab) {
while (entry != null) {
h += entry.hashCode();
entry = entry.next;
}
}
loadFactor = -loadFactor; // Mark hashCode computation complete
return h;
}
2、rehash方法
rehash方法的作用是进行扩容,并且重新计算key对应的index(调整key-value的位置),此方法虽没有使用synchronized关键字修饰,但是使用了protected关键字修饰,只对类中方法、子类方法可见,只要调用此方法的方法使用synchronized关键字修饰,那么也不会引发线程不安全的状况。
/**
* 容器扩容,并且调整各个key-value的位置
*/
@SuppressWarnings("unchecked")
protected void rehash() {
// 记录之前table数组的状态
int oldCapacity = table.length;
Entry[] oldMap = table;
// 扩大为原来的2倍 + 1
int newCapacity = (oldCapacity < 0) {
// 如果扩容前就是最大容量,则无法扩容了
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
// 否则扩容为最大值
newCapacity = MAX_ARRAY_SIZE;
}
Entry[] newMap = new Entry[newCapacity];
// 扩容也是结构性调整
modCount++;
// 计算扩容后key-value的阈值,newCapacity * 负载因子
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 将之前的table数组中的key-value进行调整
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry old = (Entry)oldMap[i] ; old != null ; ) {
Entry e = old;
old = old.next;
// 由于容量扩大了,需要重新计算下标
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry)newMap[index];
newMap[index] = e;
}
}
}
八、Hashtable、HashMap容器区别
1、HashMap允许key和value为空,而Hashtable不允许。
2、Hashtable是线程安全的(通过synchronized关键字,this锁实现),HashMap不是线程安全。
3、Hashtable继承自Dictionary,HashMap继承自AbstractMap。
4、迭代器不同,Hashtable是enumerator迭代器,HashMap是Iterator迭代器。
5、Hashtable中的hash桶由链表构成,HashMap中的hash桶可由红黑树或链表构成。
6、Hashtable中的hash值由Object.hashCode()& 0x7FFFFFFF方法计算而得(与上0x7FFFFFFF是防止hashCode出现负数,求余时也会是负数),HashMap中的hash值由Object.hashCode()的高16位、低16位异或计算而得。
7、Hashtable初始化默认大小是11,扩容为原来的2倍+1,HashMap初始化默认大小是16,每次扩容后的大小都是2的次幂。
Hashtable线程安全,相对效率低,结构也较为简单、HashMap线程不安全,但是高效,不过结构也更复杂些。
作者:hestyle