采集 58同城 房产数据信息 | Java爬虫 Jsoup
一个数据采集系统(通俗的说就是爬虫),用来采集 58同城 房产 | 郑州中的房屋数据。使用 Java 语言和Jsoup库编写,这里分享给大家。
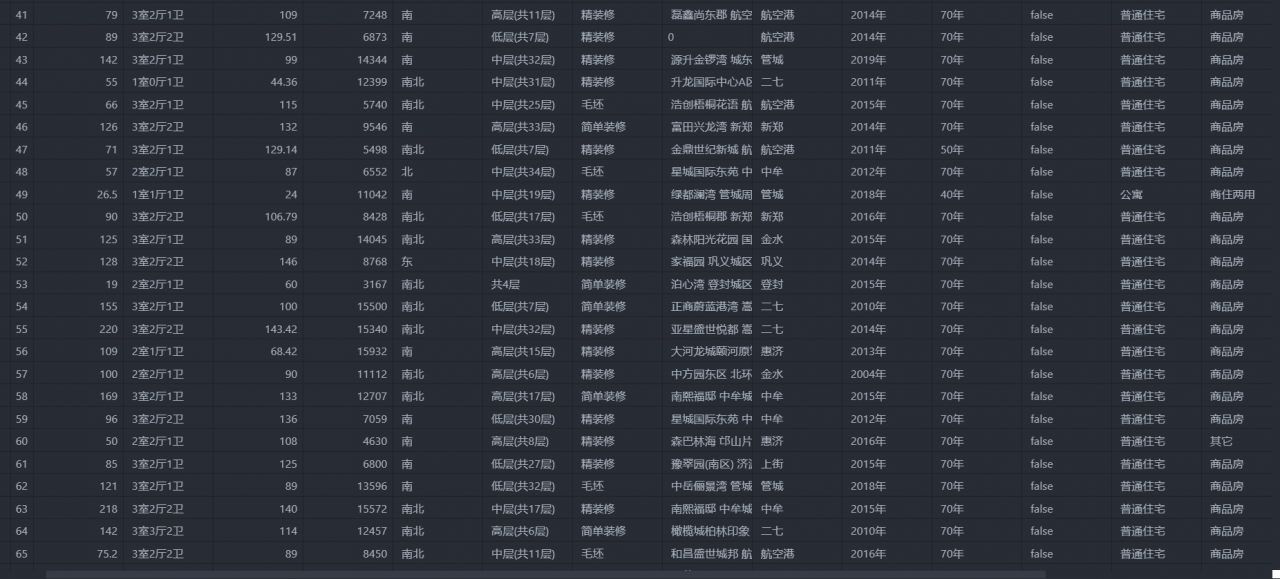
最后采集的数据结果 CSV 文件保存的,如下所示
功能都集中在 spider.get58 包的如下4个类中:
App: 应用驱动程序,控制爬虫的启动/运行逻辑和日志打印等; CrawUtil: 爬虫爬取单元,爬取特定的 url 返回 html 对象; DomParse: 从 html dom 中解析出需要的数据; House: Pojo,存储需要的数据信息。用到的 Maven 依赖如下:
org.jsoup
jsoup
1.12.1
com.alibaba
fastjson
1.2.61
org.slf4j
slf4j-log4j12
1.7.25
CrawUtil 的功能/实现是什么?
使用 Java 的 Jsoup 库(一个 Java 领域的爬虫库,相当于 python 中的 requests和 beautifulsoup)给定一个 url 连接,返回其 HTML,也就是 Jsoup库 中的 org.jsoup.nodes.Document 对象。这其中可以增加一些反反爬虫策略,如添加代理池、user-agent 标识等,来避免被人机验证。
DomParse 做了什么?
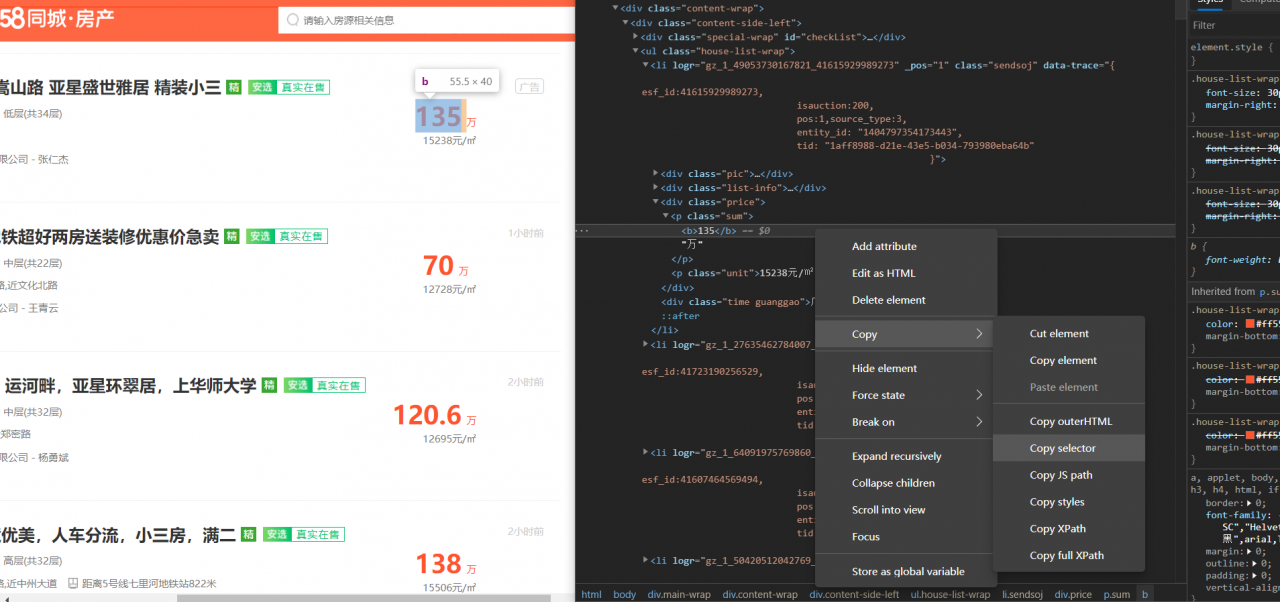
用来解析从 CarwUtil 中得到的 Document 对象,从中一步一步地遍历 dom 节点找出自己所需要的数据,这个过程就是自己现在浏览器的控制台中逐个寻找自己目标数据的位置(就像下图那样),然后通过一系列 Java API 操作得到这些数据,最后把它们额外处理下返回。里面提供了不同的方法,对应于从不同的信息网页解析出特定数据。
House 里面都包含了什么数据?
这里的数据都是58同城的网页上提供的,具体属性可以看后面的源码。
App 驱动都做了什么?
这个是代码中的核心部分,它控制了程序井井有条地爬取了58同城中所有的房屋数据,以及如何处理58的人机验证。要想详细解释它,我必须先解释下我是如何处理反爬虫的。我手工破的