小坨的Spark分布式集群环境搭建小笔记
这里采用2台机器(节点)作为实例来演示如何搭建Spark集群,其中1台机器作为Master节点,另外一台机器作为Slave1节点(即作为Worker节点)。
集群环境
Centos6.4
Hadoop2.7.7
java 1.8 (请确保java版本在1.8以上,否则会踩坑,反正我后面踩了)
搭建好Hadoop集群环境Spark分布式集群的安装环境,需要事先配置好Hadoop的分布式集群环境。如果没有配置好Hadoop的分布式集群环境,请参考小坨的在CentOS6.4搭建hadoop集群的实践笔记进行Hadoop分布式集群搭建。
安装Spark(Master节点上操作)Spark下载地址 http://spark.apache.org/downloads.html
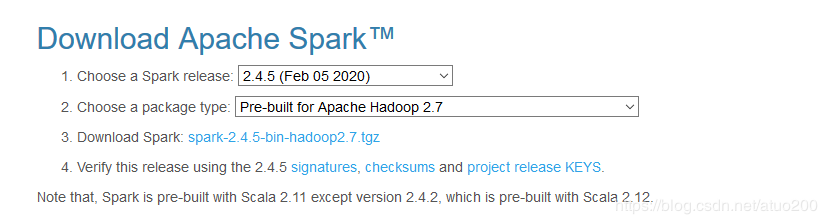
请选择对应自己Hadoop安装版本的Spark安装包进行下载
下载完成后,执行以下命令
sudo tar -zxf ~/下载/spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.5-bin-hadoop2.7 ./spark
sudo chown -R hadoop ./spark
配置环境变量(Master节点上操作)
vi ~/.bashrc
添加如下配置
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
使配置生效
source ~/.bashrc
Spark配置(Master节点上操作)
配置slaves文件
将 slaves.template 拷贝到 slaves
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves
编辑slaves内容,设置Worker节点,把默认内容localhost替换成如下内容
Slave1 #Slave1是主机名,在Hadoop安装配置的时候已做好IP地址映射
配置spark-env.sh文件
将 spark-env.sh.template 拷贝到 spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh,添加以下内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.100.10
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址
配置Worker节点把配置好的spark文件夹(/usr/local/spark)分发到Slave1节点上
在Master主机上执行如下命令
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz Slave1:/home/hadoop
在Slave1上执行以下操作
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark
记个bug
当在Slave1上执行sudo tar -zxf ~/spark.master.tar.gz -C /usr/local这一步时报出一个错误

原因是当在Slave1节点上进行解包的时候,Slave1和Master的时间不一致
只需要在解压命令加上m选项,就能解决问题
sudo tar -zmxf ~/spark.master.tar.gz -C /usr/local
有关此报错背后更详细的解答,可戳链接:解决tar命令出现“time stamp XXX in the future”的办法
启动Spark集群(在Master节点上操作)在启动Spark集群之前,要先启动Hadoop集群,在Master节点上执行命令
start-all.sh
再启动Spark集群
先启动Master节点
#我这里还没有为start-master.sh等命令配置好Path
cd /usr/local/spark/sbin
./start-master.sh
再记个bug
在执行tart-master.sh命令时报了个错误,假如你的是java版本是1.8以上的,那恭喜你跳过这个bug
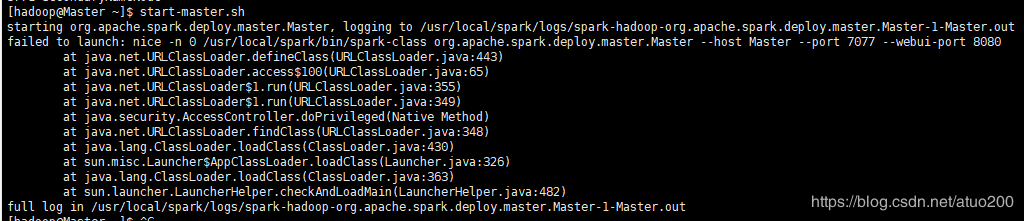
搜了一圈博客后发现是java版本不匹配的问题,原本用的是java 1.7,然后我新安装了java 1.8,把Java的环 境配置变量指向新安装的java1.8。但是此时在控制台输入java -version 和javac -version 指向的还是旧的Java 版本,死活没有用我新安装的,嗯这是个历史遗留问题,我们需要手动的把它更正过来。这里不一步一步 演示怎么更正,详细请戳:centos修改jdk之后无法生效问题。请不要忘记在Slave1节点也把Java版本更换过 来。
Master和Slave1节点都更换Java版本之后,在Master节点再次执行命令
cd /usr/local/spark/sbin
./start-master.sh
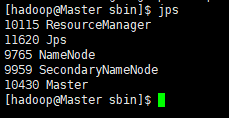
集群是正常启动了,在Master节点上运行jps命令,可以看到多了个Master进程
启动所有Slave节点(这里只有个Slave1)
在Master节点上执行以下命令
./start-slaves.sh
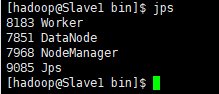
在Slave1上运行jps命令,可以看到多了个Worker进程
关闭Master节点
./stop-master.sh
关闭Worker节点
./stop-slaves.sh
关闭Hadoop集群
stop-all.sh
作者:阿坨