MySQL InnoDB引擎的缓存特性详解
1. 背景
2. 存储器性能差异
3. Buffer Pool
4. Free链表
5. Flush链表
6. LRU链表
7. 其它
1. 背景对于各种用户数据、索引数据等各种数据都是需要持久化存储到磁盘,然后以“页”为单位进行读写。
相对于直接读写缓存,磁盘IO的成本相当高昂。
对于读取的页面数据,并不是使用完就释放掉,而是放到缓冲区,因为下一次操作有可能还需要读区该页面。
对于修改过的页面数据,也不是马上同步到磁盘,也是放到缓冲区,因为下一次有可能还会修改该页面的数据。
但是缓存的空间是有大小限制的,不可能无限扩充。
对于缓冲区的数据,需要有合理的页面淘汰算法,将未来使用概率较小的页面释放或者同步到磁盘,
给当下需要存放到缓存的页面腾出位置。
2. 存储器性能差异寄存器:CPU暂存指令、数据的小型存储区域,速度快,容量小。
CPU高速缓存(CPU Cache):用于减少CPU访问内存所需平均时间的部件。
内存:用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。
硬盘:分为固态硬盘(SSD)和机械硬盘(HHD),是非易失性存储器。
下图是各种缓存器的价格和性能差距,
从下图可以看出,SSD的随机访问延时在微妙级别,而内存的的随机访问延时在纳秒级别,内存比SSD大概快1000倍左右。

一个缓冲池(缓冲池)是向操作系统申请的一块内存空间,这块内存空间由多个chunk组成,每个chunk均包含多个控制块和对应的缓冲页。
chunk是向操作系统申请内存的最小单位,缓冲页大小与InnoDB表空间使用的页面大小一致。
Buffer Pool的示意图如下
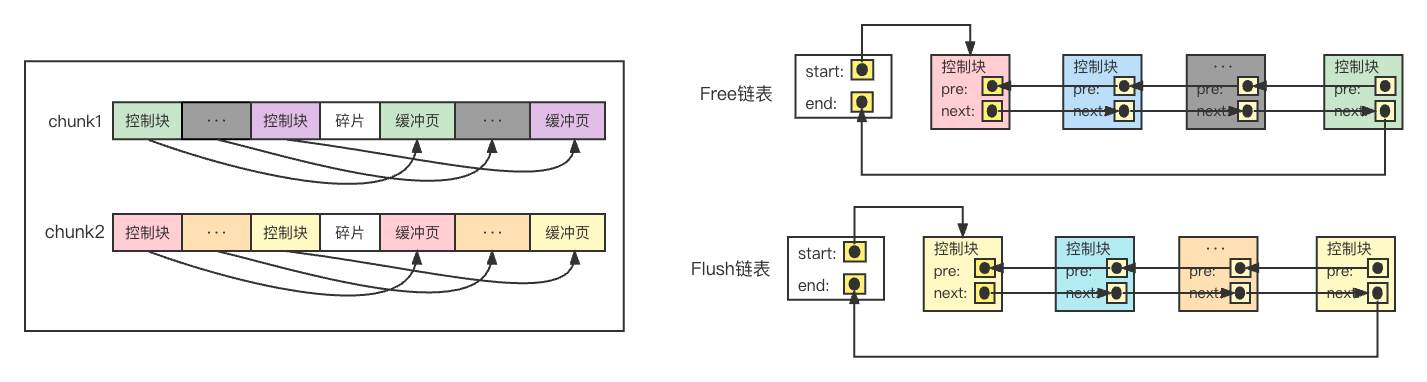
每一个控制块都对应一个缓冲页,控制块包含该缓冲页所属的表空间编号、页号、在Buffer Pool中的地址、链表结点信息等等。
当刚读取一个页面时,需要知道缓冲区有哪些空闲页面,当修改过后缓冲页后,需要记录该缓冲页需要持久化到磁盘,
当缓冲区没有空闲页面了,需要有页面淘汰算法来将缓冲页移出缓冲区,
以上涉及到Free链表、Flush链表、LRU链表,下面注意说明。
4. Free链表Free链表是由空闲的缓冲页对应的控制块组成的链表,通过Free链表就获取到空闲的缓冲页及其在缓冲区中的地址。
每当需要从磁盘加载一个页面到缓冲区时,从该Free链表取出一个控制块结点,从Free链表移除该结点,并加入LRU链表。
如果这个缓冲区页面被修改过,那么会被加入到Flush链表中。
5. Flush链表如果一修改缓冲页的数据之后就刷新到磁盘,这种频繁的IO操作势必影响程序等整体性能。
试想一下,先后修改1000次同一缓冲区页面的一字节数据,每次修改都刷新到磁盘,与修改1000次后再将最终结果刷新磁盘,节省了999次刷新磁盘的操作。
因此,当页面的数据被修改之后,需要将改页面放到Flush链表,排队等候写入磁盘。
这既可以减少在用户进程中刷新磁盘的次数,也从整体上减少了磁盘IO到次数。
6. LRU链表内存空间有限,不可能将所有数据都缓存在内存当中,因此需要有一定的算法将内存中页面淘汰掉(修改过的页面持久化到磁盘)。
LRU(Least Recently Used)链表主要用于辅助实现内存页面淘汰,故名思义,最先淘汰的是最近最少使用的缓冲页。
LRU链表的结果如下图所示
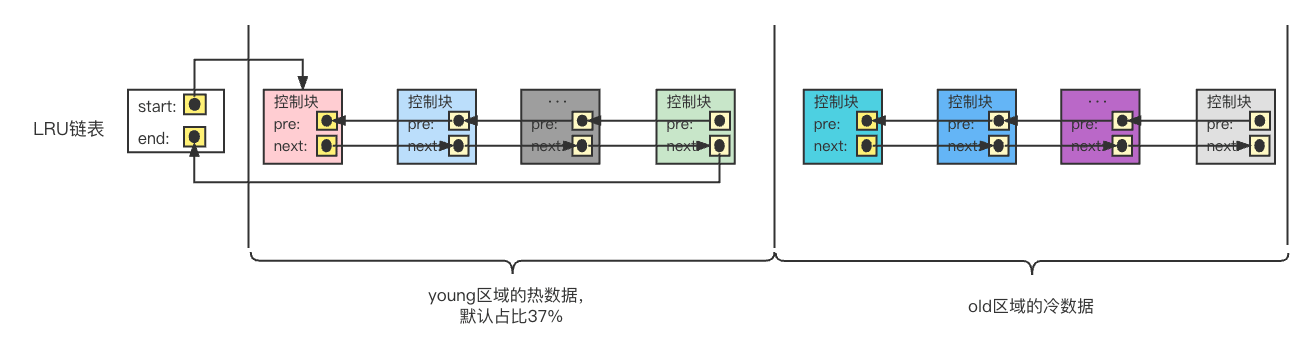
将LRU链表分为young区域和old区域。
对于初次加载到缓冲区的页面,会放到LRU链表old区域的头部,这主要避免了预读的页面被放到了LRU链表的首部。
当第二次访问缓冲页且时间间隔超过innodb_old_blocks_time(默认1s)时,才将该页面移动到LRU链表的首部。
进一步,为了避免频繁的移动链表结点,当某个缓冲页已经在young区域的前3/4时,则不会移动该结点到首部。
7. 其它如何定位页面是否被缓冲呢?
表空间号和页号可以唯一识别缓冲页,因此InnoDB引擎建立了以表空间号+页号为key,以缓冲页控制块地址为value的哈希表,
从而快速判断页面是否被缓冲,快速定位到数据所在地址。
到此这篇关于MySQL InnoDB引擎的缓存特性详解的文章就介绍到这了,更多相关MySQL InnoDB 缓存特性内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!