Spark基础知识04——窄依赖、宽依赖、DAG、缓存
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
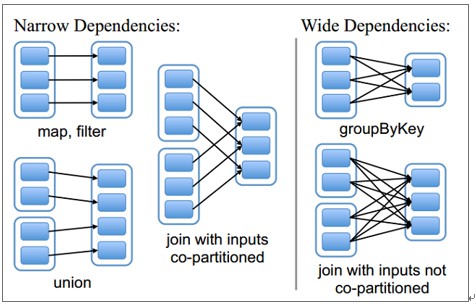
窄依赖:
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女
宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:宽依赖我们形象的比喻为超生
ps:Spark中产生宽窄依赖的依据是shuffle,当发生shuffle时,会产生宽依赖,基本上shuffle算子都会产生宽依赖,但是join除外,在执行join算子之前如果先执行groupByKey,执行groupByKey之后,会把相同的key分到同一个分区,再执行join算子,join算子是把key相同的进行join(只是对于k v形式的数据可以使用),不一定会产生shuffle ,有可能发生shuffle,也有可能不发生
distinct
聚合
reduceByKey
groupBy
groupByKey
aggregateByKey
combineByKey
排序
sortByKey
sortBy
重分区
coalesce
repartition
集合或者表操作
intersection
join
leftOuterJoin...................
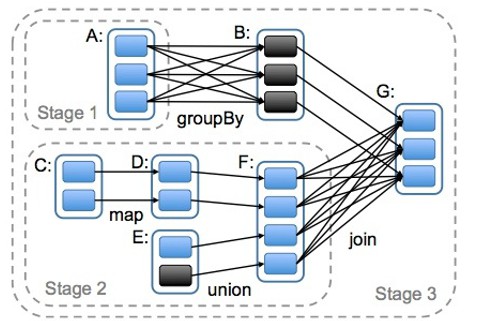
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
Application:
就是spark-submit提交的程序,经过初始化、transformation和action执行后最终能够得到想要的结果
Job:
和Hadoop一样,都是指的是作业,但和mr不一样的是,
Spark的Job是指的是一个应用程序中有几个action就有几个Job。
当action触发的时候,意味着Job开始执行了,它会把action之前的所有的transformation都进行提交任务并进行执行
Stage:
一个应用程序可以有一个或多个Job,一个Job中可以有一个或多个Stage,
划分Stage的目的是为了生成task并能够按照阶段进行执行。
多个Stage是按照顺序执行的,
Stage是初始化的时候需要划分的,划分Stage的依据是看父RDD和子RDD是否是发生宽依赖。
Task:
task是Executor执行的最终计算单元,task的生成和Stage的数量和分区的数量有直接关系
task的生成会根据分区的对应关系生成pipeline
Shuffle:是数据进行重新洗牌的过程,
Spark的Shuffle会分成两个阶段,会跨Stage节点,分成两个范围,即map task和reduce task
Shuffle Write:发生在map task阶段,是将缓冲的数据落地到磁盘的过程
Shuffle Read:发生在reduce task阶段,是将落地到磁盘的数据再读取到内存
--------------------------------------------------------------------------------------------------------------------------------------------------------------
stage划分:

-------------------------------------------------------------------------------------------------------------------------------------------------------------------
Lineage:
RDD只支持粗粒度的转换,也就是在大量的记录上执行的是单个操作。
这个过程会将RDD的一系列元数据记录下来,记录的过程就有了Lineage,
作用是通过Lineage可以方便恢复丢失的分区


RDD的缓存:
就是将中间结果数据放到缓存,以供以后计算使用
cache一般是在shuffle后再进行缓存
cache就是为了保证提高计算效率
还可以调用persist方法,该方法可以指定缓存级别 (cache调用了persist)
checkpoint:
Spark除了缓存之外,还提供了检查点机制,主要是为了通过Lineage做容错辅助,
我们的Job有时候往往依赖链条很长,Lineage过长会造成容错的成本过高,这样就不如在中间阶段做检查点进行容错,
如果之后有节点出现问题而丢失数据,从检查点重新开始做Lineage,就会减少很多的额外开销,做检查点推荐用hdfs。
跨Job是可以使用检查点的,如果跨应用程序是无法使用的。
什么时候做cache和checkpoint:
1、依赖链条特别长
2、某个计算步骤特别耗时
3、发生shuffle之后
- cache和checkoint区别:cache放在内存,checkpoint放在磁盘 HDFS上
-cache和checkpoint都要等遇到action算子才会真正的进行存储
使用流程:
1、设置检查点的目录 setCheckpointDir
2、在shuffle后做cache
3、设置检查点 checkpoint
示范:
package com.qf.gp1921.day10
import org.apache.spark.{SparkConf, SparkContext}
object CheckpointDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("checkpoint").setMaster("local[2]")
val sc = new SparkContext(conf)
// 1、设置检查点的目录
sc.setCheckpointDir("hdfs://node01:9000/cp-20190706-1")
// 2、在shuffle后做cache
val rdd = sc.textFile("hdfs://node01:9000/files").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).cache()
// 3、设置检查点
rdd.checkpoint()
rdd.count()
//因为遇到了action算子,此处将开始新的job 检查点不必创建新的,可以跨job使用
sc.stop()
}
}
作者:zgm12